近期断断续续的看了一些transformer相关的paper,看的比较杂,有些是对应领域比较有代表性地工作。偷个懒就不详细介绍每篇Paper,简单地记录一下这些paper大致要解决地问题。
知识蒸馏[转载]
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法,由于其简单,有效,在工业界被广泛应用。这一技术的理论来自于2015年Hinton发表的一篇神作: Distilling the Knowledge in a Neural Network。Knowledge Distillation,简称KD,顾名思义,就是将已经训练好的模型包含的知识(”Knowledge”),蒸馏(“Distill”)提取到另一个模型里面去。
Swin-transformer
论文信息: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
代码链接:https://github.com/microsoft/Swin-Transformer
整体信息: Swin Transformer 提出了一种针对视觉任务的通用的 Transformer 架构,Transformer 架构在 NLP 任务中已经算得上一种通用的架构,但是如果想迁移到视觉任务中有一个比较大的困难就是处理数据的尺寸不一样。作者分析表明,Transformer 从 NLP 迁移到 CV 上没有大放异彩主要有两点原因:(1)两个领域涉及的scale不同,NLP的scale是标准固定的,而CV的scale变化范围非常大。(2) CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。
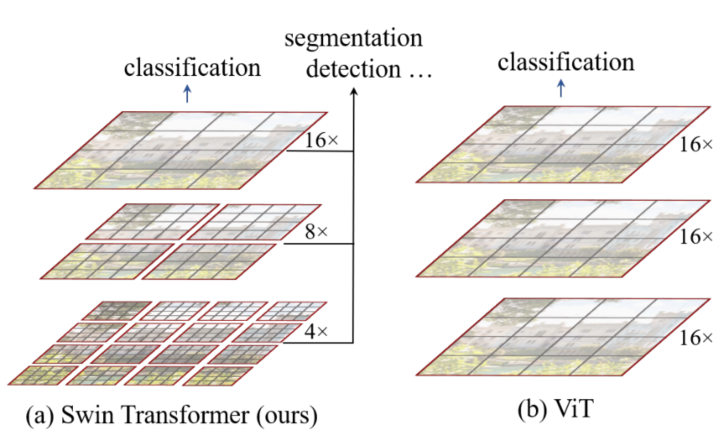
Transformer 在图像领域应用的开拓者VIT
论文信息: An image is worth 16x16 words: Transformers for image recognition at scale
代码链接:https://github.com/google-research/vision_transformer
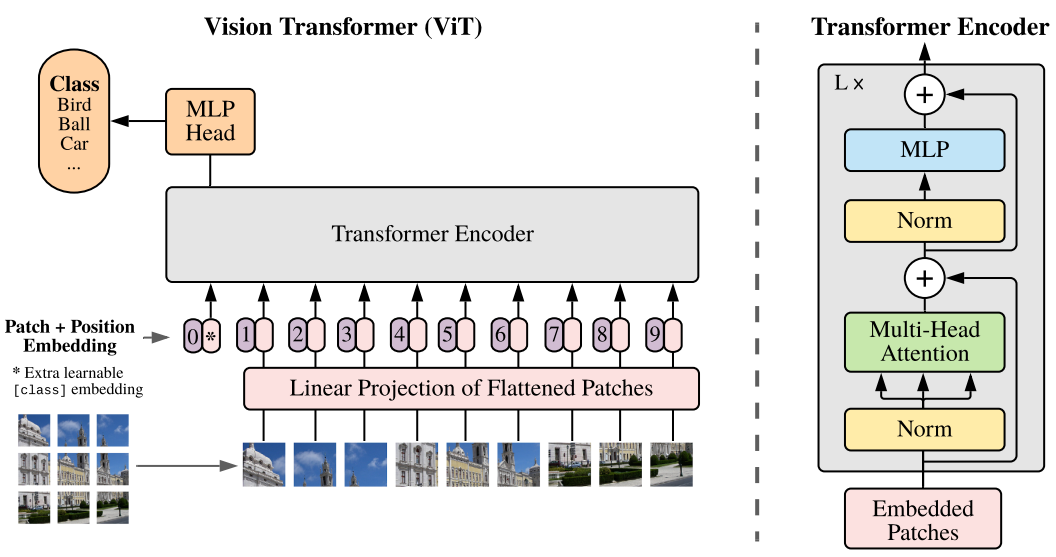
整体信息:ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。
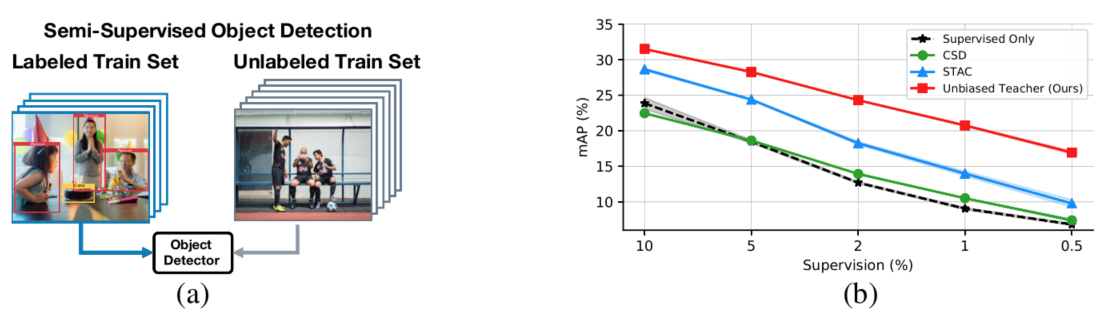
unbiased teacher-半监督目标检测
论文信息: Unbiased Teacher for Semi-Supervised Object Detection
代码链接:https://github.com/facebookresearch/unbiased-teacher
整体信息:这是facebook research在半监督目标检测上的工作。以往的半监督学习多聚焦与分类任务上,在检测任务上少有涉及。解决半监督目标检测的一个直接方法是应用半监督分类方法,但是由于目标检测的特性,图像分类方法并不适合,主要原因在于目标检测任务中的类别不平衡严重阻碍了伪标签的使用。
fixmatch-基于数据增强实现半监督学习
论文信息:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
代码链接:https://github.com/google-research/fixmatch
整体信息:这在实际业务场景中,大量的标注数据对于模型性能的提升至关重要,但是获取标注数据是一个耗时耗力的过程,例如工业场景中由于机台型号的更换导致模型性能下降,花费大量时间对新数据进行重新标注大概率会导致模型上线时间delay,而半监督学习(Semi-Supervised Learning, SSL)探究了如何利用大量未标注数据和部分标注数据来提升模型性能。而本文,谷歌提出的fixmatch,是对现有SSL方法进行显著简化的算法。
目标检测上的自监督学习
论文信息: Instance Localization for Self-supervised Detection Pretraining
代码链接:https://github.com/limbo0000/InstanceLoc
整体信息:这是被CVPR2021的文章,现有的自监督学习方法极大地提升了在图像分类任务上的指标上限,然而在目标检测任务上的迁移性能却与分类任务不一致。论文将这种迁移学习中存在的misalignment问题归咎为:(1)预训练网络结构和目标检测网络结构不一致;(2)现有的对比学习自监督方式是一个分类问题,没有对位置建模。
长尾目标检测-Seesaw Loss[转载]
论文信息: Seesaw Loss for Long-Tailed Instance Segmentation
代码链接:https://github.com/open-mmlab/mmdetection/tree/master/configs/seesaw_loss
整体信息:这是 MMDet 团队参加 LVIS 2020 竞赛获得rank1时提出地损失函数,这篇文章指出了限制检测器在长尾分布数据上性能的一个关键原因:施加在尾部类别(tail class上的正负样本梯度的比例是不均衡的。因此,我们提出 Seesaw Loss 来动态地抑制尾部类别上过量的负样本梯度,同时补充对误分类样本的惩罚。 Seesaw Loss 显著提升了尾部类别的分类准确率,进而为检测器在长尾数据集上的整体性能带来可观的增益。由于原作在知乎上已有讲解,我就不班门弄斧,直接搬运过来,侵权删。
TTFNet 快速训练版的CenterNet
论文信息: Training-Time-Friendly Network for Real-Time Object Detection
代码链接:https://github.com/ZJULearning/ttfnet
问题: 这篇论文主要是解决CenterNet存在的一些问题,CenterNet在推理速度精度上表现不差,但存在训练耗时的问题,CenterNet官方代码训练coco需要2.5天,因此这篇论文主要是如何改进CenterNet训练耗时长的问题。作者基于CenterNet,在回归box时,作者认为由于CenterNet进行回归时仅仅使用中心点的那些目标是次优的选择,同时作者借助了FCOS是使用Ground Truth回归所有样本的思想,这里作者想到使用高斯核来选择回归样本,一方面可以增加回归的信息量,提升检测精度,同时作者指出这样有增加batch size的效果,可以使用更大的学习率以及有更短的训练时间。并且没有引入FCOS中耗时的NMS后处理过程,使得Inference时间减小。