论文信息: Instance Localization for Self-supervised Detection Pretraining
代码链接:https://github.com/limbo0000/InstanceLoc
整体信息:这是被CVPR2021的文章,现有的自监督学习方法极大地提升了在图像分类任务上的指标上限,然而在目标检测任务上的迁移性能却与分类任务不一致。论文将这种迁移学习中存在的misalignment问题归咎为:(1)预训练网络结构和目标检测网络结构不一致;(2)现有的对比学习自监督方式是一个分类问题,没有对位置建模。
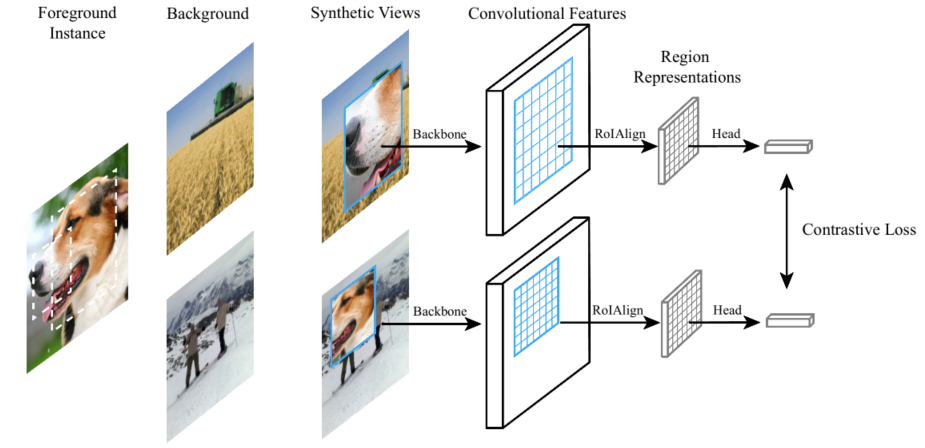
方法很直观,将同一个Instance随机crop得到patch,随机粘贴到不同的背景中,使用对比学习进行自监督学习。其中对比学习框架上是按照MoCo来的,其中包括queue设计、动量更新等。
Bounding-Box Augmentation
在对比学习中,通常需要构建俩个不同view下的输入,在InsLoc这篇论文中,采用的是anchor的方式生成的。
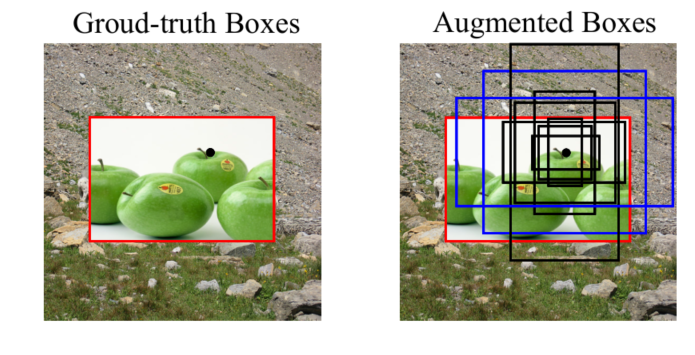
给定gt box,可以计算所有anchors和gt的iou,选取IOU>0.5的anchor作为aug box构造输入对,进行对比学习。
gt box和aug box经过roi align之后得到roi特征,再经由一个俩层的MLP层得到最终特征表示,用于后续的contrastive learning。
Experients
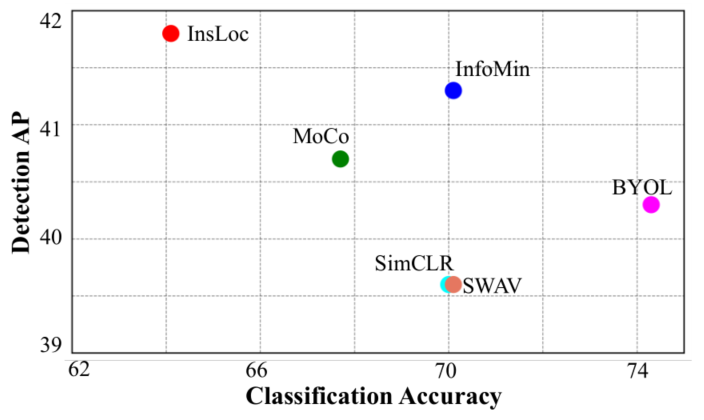
从上图可以看出,相比于其他方法,insloc牺牲了很多分类上的acc,但都贡献在检测的ap上。
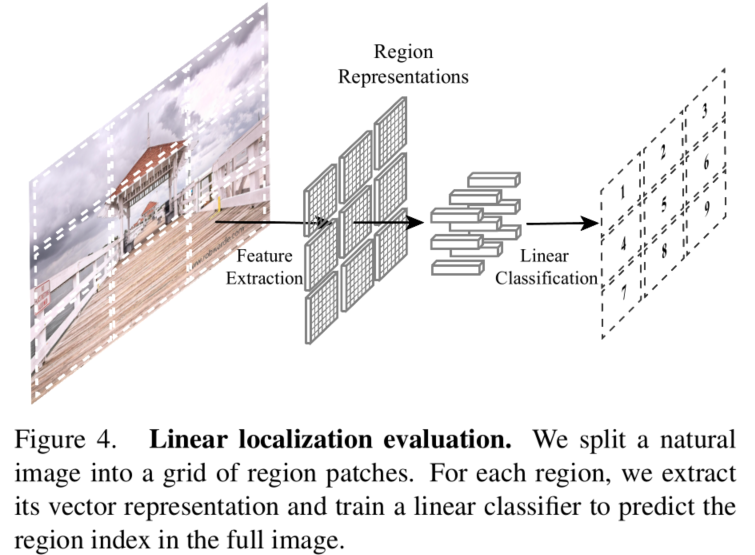
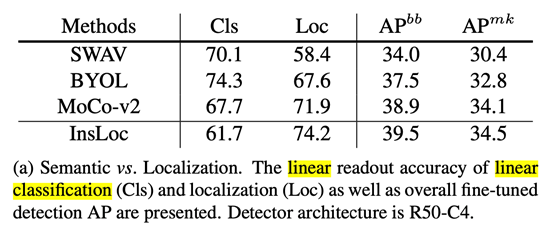
在论文中还提到如何评估自监督方法是否具有关注定位的能力。转化为patch块的位置预测。 如上图所示。下面是对应方法的实验结果。IncLoc对于定位能力是最强。