论文信息:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
代码链接:https://github.com/google-research/fixmatch
整体信息:这在实际业务场景中,大量的标注数据对于模型性能的提升至关重要,但是获取标注数据是一个耗时耗力的过程,例如工业场景中由于机台型号的更换导致模型性能下降,花费大量时间对新数据进行重新标注大概率会导致模型上线时间delay,而半监督学习(Semi-Supervised Learning, SSL)探究了如何利用大量未标注数据和部分标注数据来提升模型性能。而本文,谷歌提出的fixmatch,是对现有SSL方法进行显著简化的算法。
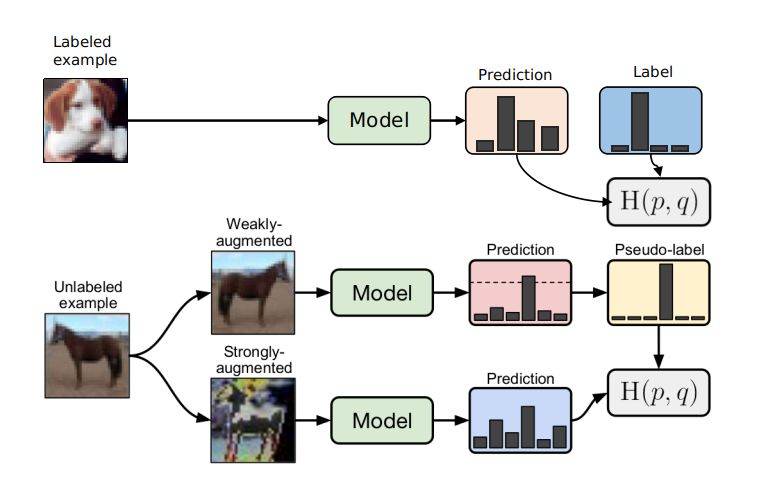
核心思想
如上图所示,训练过程包括两个部分,有监督训练和无监督训练。有label的数据,执行有监督训练,和普通分类任务训练没有区别。没有label的数据,经过首先经过弱增强获取伪标签。然后利用该伪标签去监督强增强的输出值,只有大于一定阈值条件才执行伪标签的生成。无监督的训练过程包含两种思想在里面,即一致性正则化和伪标签训练。
1. 一致性正则
一致性正则化是当前半监督SOTA工作中一个重要的组件,其建立在一个基本假设:相同图片经过不同扰动(增强)经过网络会输出相同预测结果,因此对这二者进行loss计算便可以对网络进行监督训练,又被称为自监督训练。loss计算如下:
其中,$\alpha$ 表示随机的弱增强操作。
2. 伪标签
伪标签是利用模型本身为未标记数据获取人工标签的思想。通常是使用“hard”标签,也就是argmax获取的onehot标签,仅保留最大类概率超过阈值的标签。计算loss的时如下:
其中,$\hat{q}{b}=\arg \max \left(q{b}\right)$ , $\tau$ 是阈值。
3.为什么work?
无监督训练过程实际上是一个孪生网络,可以提取到图片的有用特征。弱增强不至于图像失真,再加上输出伪标签阈值的设置,极大程度上降低了引入错误标签噪声的可能性。而仅仅使用弱增强可能会导致训练过拟合,无法提取到本质的特征,所以使用强增强。强增强带来图片的严重失真,但是依然是保留足够可以辨认类别的特征。有监督和无监督混合训练,逐步提高模型的表达能力。
算法流程

1.输入:有标签数据,无标签数据,另外需要设定一些超参,包括置信度阈值,无标签采样比例,loss权重。
2.对有标签数据进行监督训练,使Cross-Entropy loss;
3.遍历无标签数据,利用弱增强获取伪标签;
4.利用获取的伪标签对无标签数据进行训练,同样利用Cross-Entropy loss;
5.基于loss权重,对俩者loss进行融合;
loss设计
loss包含俩部分:有标注数据的监督训练$L_s$和无标注数据的伪标签监督训练$L_u$。
其中,$\alpha(.)$ 表示弱增强,一般为flip翻转,shift平移;$\mathcal{A}$(.)为强增强,一般为颜色变换,对比度增强等等。
数据增强
在fixmatch中包含俩种数据增强:weak aug和strong aug. weak aug为标准的flip-and-shift增强策略,50%的概率进行flip和12.5%的概率进行shift,包括水平和竖直方向。对于strong aug,论文主要应用RandAugment和CTAugment两种策略,都是为提高模型表现而提出的增强策略。

对于RandAugment:(1)从这个列表里随机选出N个增强,例如N为2;(2)然后选择一个随机的幅度M,例如50%之类的;(3)将所选的增强应用于图像,每种增强都有50%的可能性被应用。
实验
作者在CIFRAR,SVHN,STL数据集上做了详尽的实验,从实验结果来看,均优于以前的方法。
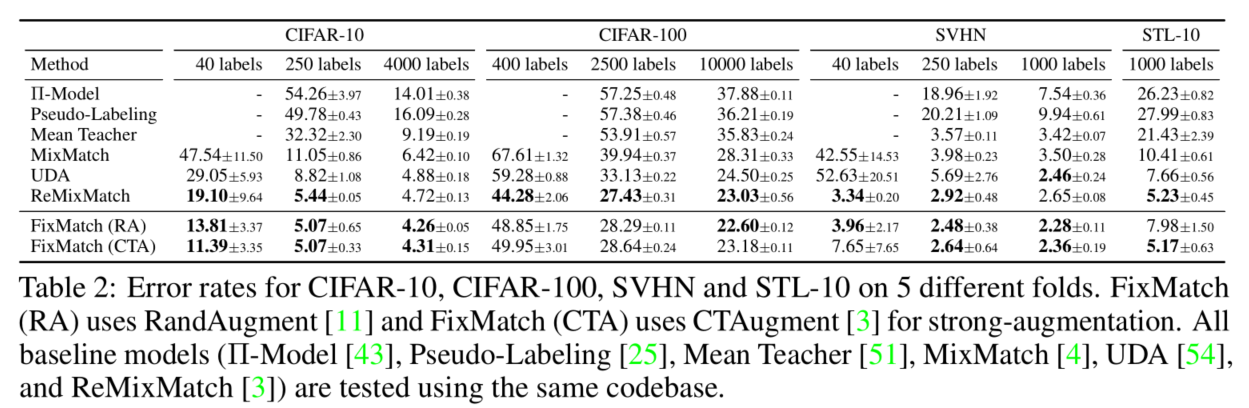
在CIFAR-10和SVHN上选用的是Wide ResNet-28-2模型, CIFAR-100选用的是WRN-28-8,STL-10选用的是WRN-37-2。在每个类只有四张图片的情况下,fixmatch明显优于其他方法。
对于极端缺少标注的场景,仅仅使用每个类别使用1张图片,共10张标注的图片就可以达到78%的最大accuracy,当然这种做法和挑选的样本质量有关,作者也做了相关实验论证。不过也证明本文的方法的确work。

总结
fixmatch是SSL领域的一篇经典论文,做法简单有效,利用少量的标注图片就可以达到一个不错的效果,这对于获取标注困难的场景非常有意义。很值得在业务场景试一下。