论文信息: Unbiased Teacher for Semi-Supervised Object Detection
代码链接:https://github.com/facebookresearch/unbiased-teacher
整体信息:这是facebook research在半监督目标检测上的工作。以往的半监督学习多聚焦与分类任务上,在检测任务上少有涉及。解决半监督目标检测的一个直接方法是应用半监督分类方法,但是由于目标检测的特性,图像分类方法并不适合,主要原因在于目标检测任务中的类别不平衡严重阻碍了伪标签的使用。
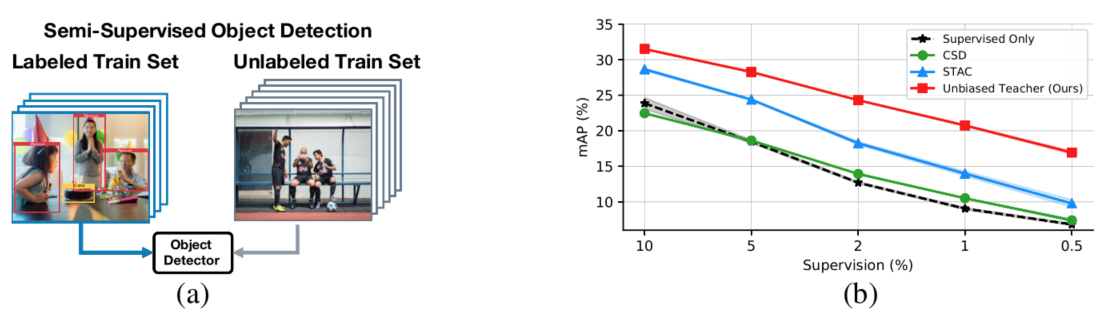
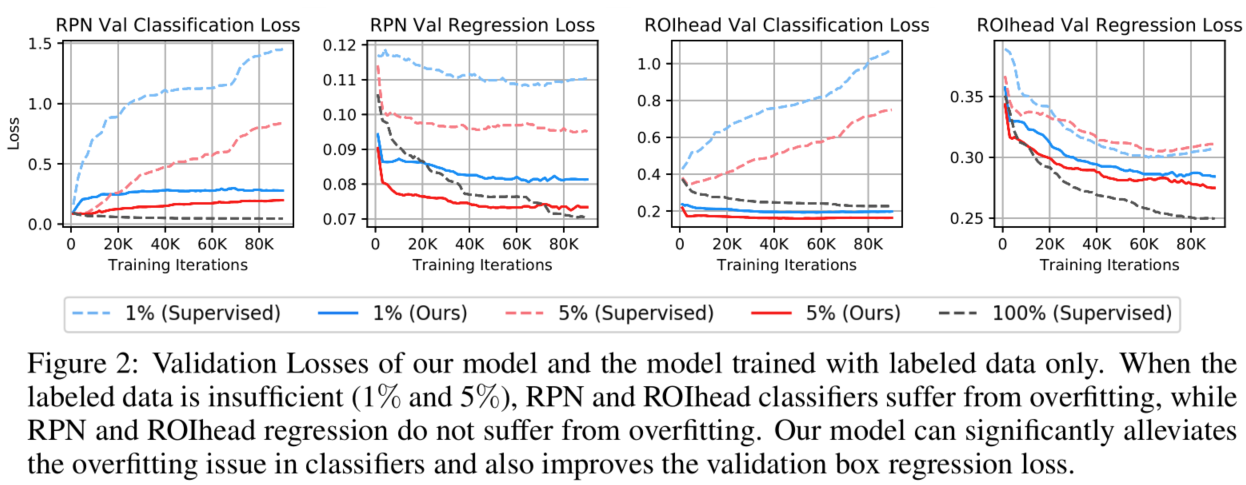
目标检测中存在前景背景不平衡和前景之间类不平衡,这些不平衡导致半监督训练中产生有偏差的预测。伪标签作为图像分类半监督中最有效的方法之一,在目标检测中因为倾向置信度高的类别和区域导致产生偏差。将偏差伪标签加入训练会加重类不平衡问题和产生过拟合。如上图所示。
核心思想
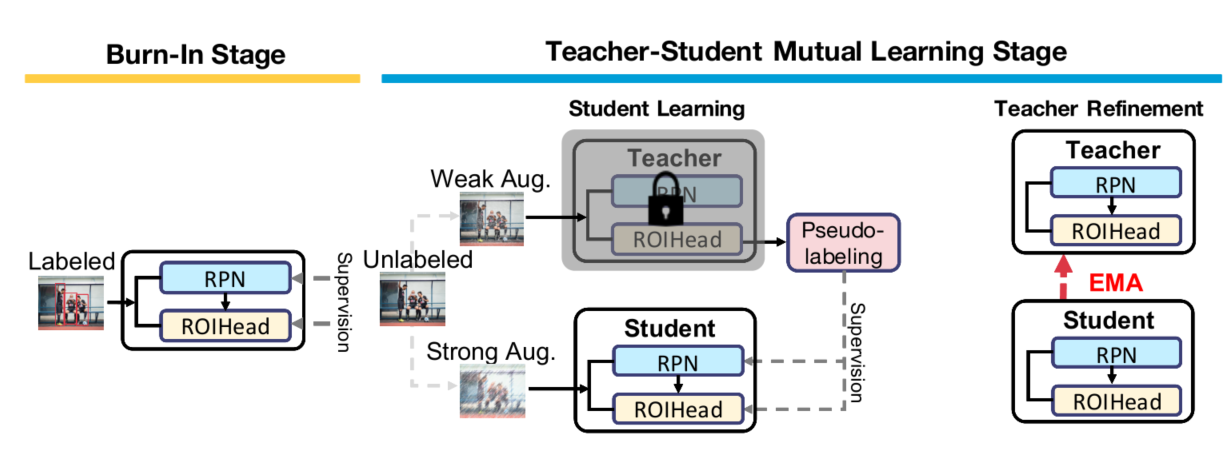
如上图所示,Unbiased Teacher框架包含俩个部分,Burn-In 和 Teacher-Student Mutual Learning。在Burn-In 阶段,使用所有有标注数据训练目标检测器。在第二阶段,我们先将Burn-In训练好的检测器复制给两个模型(Teacher和Student)。第二阶段的目标是通过一种共同学习的机制来更新Teacher和Student模型,Teacher模型产生伪标签用于训练Student模型,然后student模型学到的知识再用于更新teacher模型,因此用于训练student模型的伪标签本身也在自我更新。
1. Burn In
该阶段使用所有标注数据来训练检测模型,使用$L_{sup}$ 优化模型参数:
在作者的appendix有验证burn-in阶段的必要性,在早期阶段,burn-in可以使模型获得更准确的伪标签,而且可以加快模型收敛。
2. Teacher-Student Mutual Learning
teacher模型生成伪标签用于训练student模型,student模型的权重转移给teacher模型以更新teacher模型,在teacher和student的迭代训练中提高了检测准确率。随着检测准确率的提高,teacher产生更为准确和稳定的伪标签,这是性能改善的关键。我们也可以将teacher视为student在不同的时间步里进行temporal ensemble所得,这与我们的研究一致,即teacher的准确率高于student。与先前的研究相比,改善teacher的关键因素就是student模型的多样性,所以我们采用强增强图片作为student的输入,使用弱增强图片作为teacher的输入以提供可信赖的伪标签.
Student Learning with Pseudo-Labeling
我们首先设置一个置信度阈值 $\delta$,用于过滤低置信度的预测框,这些低置信度的预测框极有可能是错误的正样本。此外,含噪的伪标签会涌向teacher模型,所以我们将teacher和student分开训练。在获得伪标签后只有student的权重可以通过反向传播更新:
Teacher Refinement via Exponential Moving Average
为了获得稳定的伪标签,我们应用EMA来逐步更新teacher模型。
3. Bias in pseudo-label
理论上来说,基于伪标签的方法可以解决由于标签匮乏带来的问题,但是目标检测任务中的不平衡属性影响了该方法的有效性。目标检测中存在前景-背景不平衡和前景中类不平衡问题,如果在训练数据不充足的情况下使用标准CE,模型会倾向于预测主要类别,这会导致预测偏向数量较多的类别,生成类不平衡的伪标签(偏差伪标签)。在训练时使用偏差伪标签会使不平衡预测问题恶化。
为了解决这个问题,我们考虑一种简单但是高效的方法,在ROIhead的多类别分类loss中,我们使用Focal loss代替CE loss。Focal loss将给置信度较低的目标实例分配更多的loss权重,这样模型会看重hard目标而不是那些极有可能是主要类别的简单目标。
另一方面,采用EMA机制可以防止决策边界急剧的向少数类别倾斜,teacher模型的权重可表示为
EMA-training使得Teacher模型有利于产生更稳定的伪标签,解决SS-OD中的类失衡问题。
实验
以FasterRCNN作为目标检测器,置信度阈值$\delta = 0.7$;弱增强:随机水平翻转flip;强增强:color jitter, grayscale,gaussian blur, cutout等等。
COCO-standard
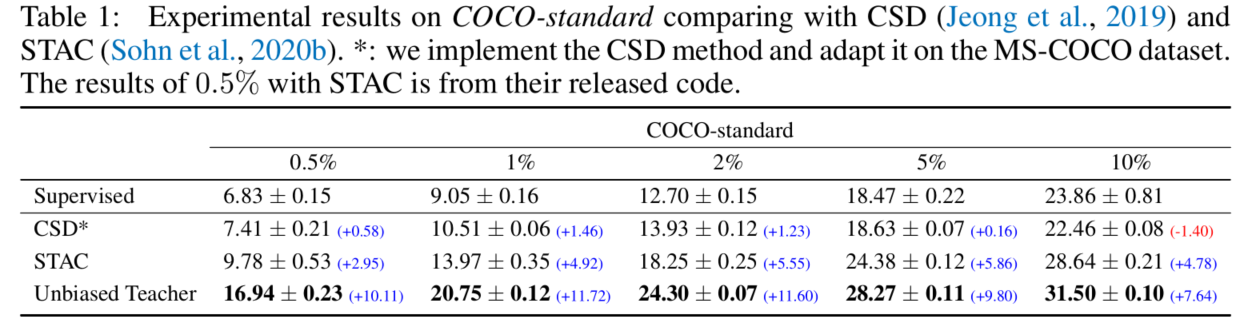
从上述表格可以看出,有标签数据越少,本文提出的方法改善越大。在作者看来,主要原因在于:(1)伪标签更准确;(2)EMA和Focal loss有效地解决伪标签类失衡问题;
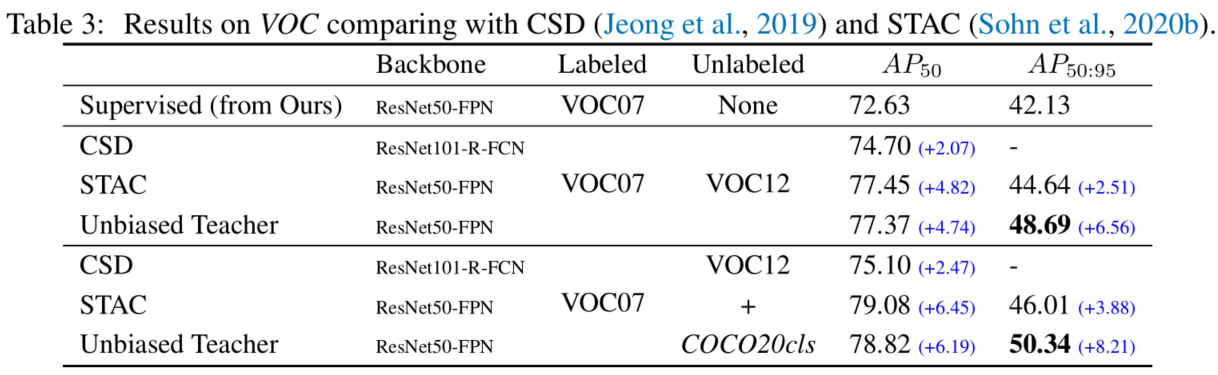
COCO-additional and VOC
作者还有进一步验证在100%标注数据下,使用额外无标注数据能否进一步提升模型性能。
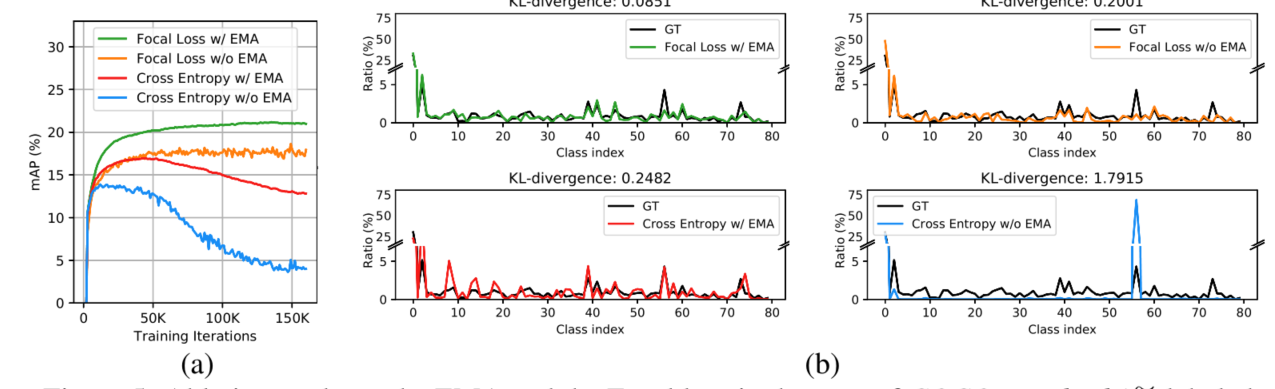
ablation study
EMA: teacher和student同步更新,目前半监督图像分类中最优的模型Fixmatch也是同步更新。
Focal loss:有使用Focal loss的模型产生的伪标签分布与真是标签分布更相似,将KL散度从1.7915(无EMA无Focal loss)改善到0.2001(无EMA有Focal loss)
总结
这篇文章分析了直接将半监督分类方法应用与目标检测任务时存在的俩个问题:类失衡和过拟合,并提出了unbiased-teacher,简单高效的解决了上述俩个问题。