前几天看完CLIP论文后觉得视觉-语言预训练(Vision-Language Pretraining)这个方向还挺有意思,就顺便找了一篇关于VLP的综述文章:VLP: A Survey on Vision-Language Pre-training,这篇文章有详细地介绍了VLP领域的最新进展和总结,包括了图像-文本和视频-文本的预训练。对于完整的了解VLP这个领域有很大帮助。
CLIP图文多模态对比预训练方法详解
CLIP是OpenAI在2021年发表的一种用NLP来监督CV的方法。成功连接文本和图像。CLIP全称是, Contrastive Language–Image Pre-training,一种基于对比文本-图像对的预训练方法。在了解CLIP具体方法之前,可以先看一下该工作的在一些下游任务的应用。
Diffusion Model详解
扩散模型(Diffusion Model)是一种新的图像生成范式,有着与其他生成方法比如GAN、VAE以及Flow-based models不同而且有意思的特性。最近也有许多基于diffusion model的图像生成方法涌现出来,比如DALLE2、Imagen、GLIDE, CogView1&2,本文主要依据Lil’Log 的博客进行翻译整理,方便学习记录。可以先看一下基于diffusion model的一些下游方法基于text-to-image图像生成结果。
Real-ESRGAN详解
论文信息:Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
代码链接: https://github.com/xinntao/Real-ESRGAN
整体信息: Real-ESRGAN目前超分算法中比较热门应用较广的算法,在了解该算法前,可以先了解一下该方法的一个发展历程,SRCNN->SRGAN->ESRGAN->Real-ESRGAN。
Mask Transfiner详解
论文信息:Mask Transfiner for High-Quality Instance Segmentation
代码链接:https://github.com/SysCV/transfiner
整体信息:这是ETH和港科大合作发表在CVPR2022上有关实例分割的论文,该论文中提出的Mask Transfiner通过引入 Incoherent Regions检测机制的方式,在不产生额外计算成本的情况下,有效地改善目标分割mask。在COCO,Cityscapes和BDD100K上均取得了明显的性能提升。
![]()
增量目标检测方法 Faster ILOD
论文信息: Faster ILOD: Incremental Learning for Object Detectors based on Faster RCNN
代码链接:https://github.com/CanPeng123/Faster-ILOD
整体信息:这是发表在PRL2020上的一篇文章关于增量目标检测的文章,作者是来自The University of Queensland,这篇文章基于Faster RCNN,使用multi-network 自适应蒸馏,设计了一种end2end的增量目标检测方法。
增量目标检测方法调研
最近参加了CVPR2022 有关增量学习的一个Workshop:Workshop on Continual Learning in Computer Vision,这个workshop有三个赛道:(1)Instance Classification Track,(2)Category Detection Track;(3)Instance Detection Track,三个赛道的任务介绍可以看官网。个人是做检测方向出身,因此关注了一下track2,并基于增量目标检测方向做了部分调研,并简单介绍其中部分算法。
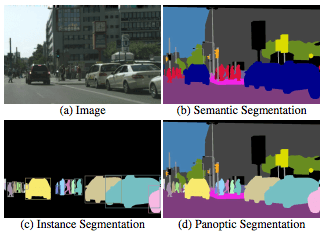
Panoptic Segmentation详解
最近在知乎上频繁地刷到有关Mask2Former地帖子,这么多人吹捧地必是精品,就跟一波风看了一下Mask2Former,顺带地也了解一下Panoptic Segmentation这个任务。众所周知,图像分割主要有两个方向:
- 语义分割(semantic segmentation),常用来识别天空、草地、道路等没有固定形状的不可数事物(stuff)。语义分割的标记方法通常是给每个像素加上标签。
- 实例分割(instance segmentation),人、动物或工具等可数的、独立的明显物体(things)。实例分割通常用包围盒或分割掩码标记目标。
全景分割(Panoptic Segmentation)其实就是把这两个方向结合起来,生成统一的、全局的分割图像,既识别事物,也识别物体。
自监督学习--基于contrastive learning方法
基于contrastive learning的自监督学习方法从2020-2021年涌现了许多工作,这里不一一列举,但是会简单介绍一些高引用的方法:MoCo,SimCLR,MoCov2,BYOL,SwAV,SimSiam,MoCov3。

自监督学习--基于pretext-task方法
自从2019年MoCo横空出世,掀起了一股自监督学习的浪潮,随后SimCLR,MoCo,BYOL,SwAV等一系列优秀的工作被提出,2021年底,何凯明的MAE更是将自监督学习带到另外一个高度。自监督学习的背后一个强大的动机就是,打破目前神经网络训练对于标注数据的依赖,即使在没有标注数据的情况下,也可以高效的训练网络。自监督学习的核心在于合理构建有利于模型学习的任务,其大致可分为三类: