前几天看完CLIP论文后觉得视觉-语言预训练(Vision-Language Pretraining)这个方向还挺有意思,就顺便找了一篇关于VLP的综述文章:VLP: A Survey on Vision-Language Pre-training,这篇文章有详细地介绍了VLP领域的最新进展和总结,包括了图像-文本和视频-文本的预训练。对于完整的了解VLP这个领域有很大帮助。
整篇综述从以下5个方面对视觉-语言预训练进行了详细地阐述:
- 特征提取
- 模型架构
- 预训练目标
- 预训练数据集
- 下游任务
VLP主要通过对大规模数据的预训练来学习不同模态之间的语义对应关系。例如,在图文预训练中,我们希望模型将文本中的“狗”与图像中的“狗”联系起来。在视频文本预训练中,我们期望模型将文本中的对象/动作映射到视频中的对象/动作。为了实现这一目标,需要巧妙地设计VLP对象和模型体系结构,以允许模型挖掘不同模式之间的关联。
特征提取
特征提取部分分为视觉特征提取和文本特征提取。视觉特征提取包括图像特征提取和视频特征提取。
图像特征提取
- OD-based Region Features (OD-RFs):使用预训练的目标检测模型识别图像中目标区域,并提取每个区域的表示,来提取视觉特征,常用的是Faster RCNN;
- CNN-based Grid Features (CNN-GFs):直接用CNN对整张图提取视觉特征获得网格特征;
- ViT-based Patch Features (ViT-PFs):使用ViT将图片压平成序列,对于transformer类型的encoder的输入比较友好;
视频特征提取
一般把视频当做M帧组成的图像信息。VLP模型利用上述图像特征提取方法提取frame特征。俩个常用的是CNN-GFs和ViT-PFs。对于CNN-GFs,一般是使用在imagenet上预训练的resnet和预先训练好的SlowFast来提取每个视频帧的2d特征和3d特征。将这些特征串联便可得到视频的视觉特征,通过FC层被投影到与token embedding相同的低维空间;对于ViT-PFs,一段视频clips $V_{i} \in \mathbb{R}^{M \times H \times W \times C}$ 会被分割为 $M \times N$ 的无重叠的时空patchs,大小为$P \times P$, 在这里 $N=\frac{H W}{P^{2}}$.
文本特征提取
对于文本特征,一般使用Bert进行特征提取。VLP模型首先将输入的句子分割成一系列字词。然后再序列的开头和结尾处插入序列开始和结束标记。
模型结构
模型结构主要从俩个视角进行划分:
- 从多模态融合上,可以划分为:Single-stream和Dual-stream;
- 从整体结构设计上,可以划分为:Encoder-Only和Encoder-Decoder;
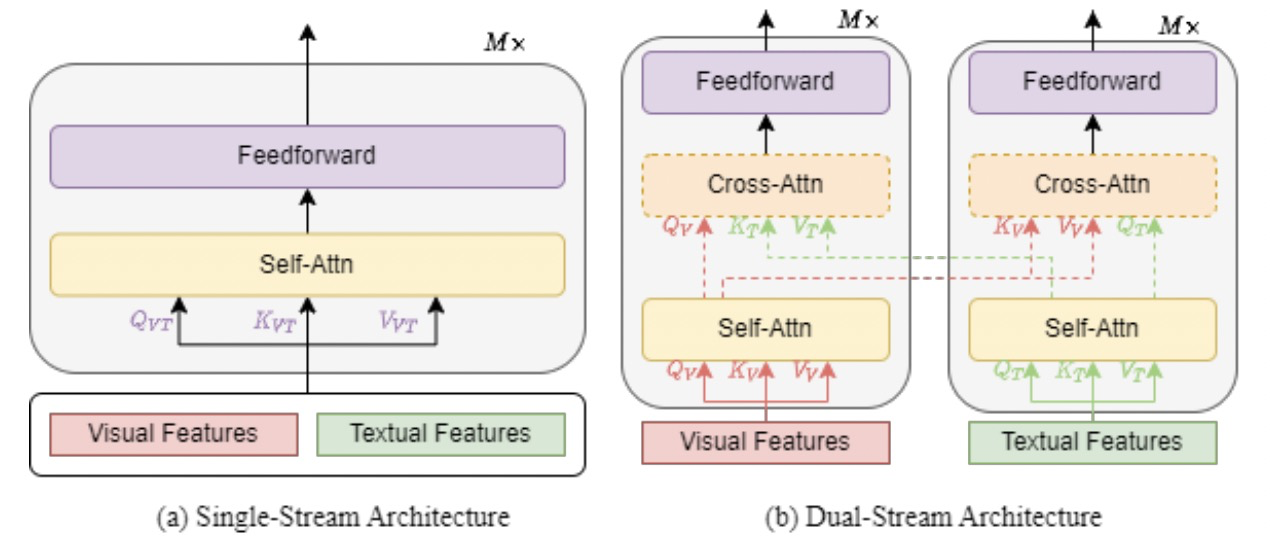
Single-stream vs Dual-stream
单流架构是指将文本和视觉特征连接在一起,然后馈送到单个Transformer块中。双流架构是指文本和视觉特征不是串联在一起而是独立地发送到两个不同的Transformer块中。单流架构一般来说更加parameter-efficient。双流架构一般采用上图虚线所表示的cross attention进行特征交互。
Encoder-Only vs Encoder-Decoder
许多VLP模型采用encoder-only的体系结构,其中跨模态表示被直接馈送到输出层以生成最终输出。相比之下,其他VLP模型主张使用encoder-decoder体系结构,其中跨模态表示首先被馈送到decoder,然后被馈送到输出层。
预训练目标
在论文中对预训练目标归纳为了四类:Completion、Matching、Temporal和Particular。
Completion
这类方法主要是通过对masked的元素进行重建来理解模态信息。包括:Masked Language Modeling、Prefix Language Modeling和 Masked Vision Modeling。
Masked Language Modeling
掩蔽语言建模(MLM)应该是被广泛应用在Bert模型中的一种预训练方式,通过利用上下文的可见的词向量预测masked词向量。而在VLP任务重则是使用上下文可见的词向量和视觉向量表征去预测masked的视觉或者词向量。
Prefix Language Modeling
前缀语言建模(Prefix Language Model,Prefix LM)是屏蔽语言模型和语言建模的统一。前缀模型的提出是为了使模型具有实体生成能力,使得文本诱导的zero-shot具有无需fine-tuning的泛化性。
Masked Vision Modeling
与MLM类似,MVM对视觉(图像或视频)区域或块进行采样,并通常以15%的概率mask其视觉特征。在给定剩余视觉特征和所有文本特征的情况下,VLP模型需要重建mask的视觉特征。
Matching
Matching是将视觉和语言统一到一个共享的隐层,生成通用的视觉语言表征。包括Vision-Language Matching, Vision-Language Contrastive Learning, Word-Region Alignment。
Vision-Language Matching
视觉语言匹配(VLM)是最常见的预训练模型的目标,以实现视觉和语言的匹配。以双流VLP模型为例,在得到视觉表征和文本表征之后将其串联起来,作为俩种模式的融合表征,然后经过FC层和sigmoid函数,以预测0-1分数,0表示视觉-语言不匹配,1表示视觉和语言匹配。
Vision-Language Contrastive Learning
视觉语言对比学习(VLC)从N × N个可能的视觉语言对中预测出匹配的视觉语言对。请注意,在一批训练中有N ~ N个负视觉语言对。VLP模型计算 softmax-normalized 的视觉(图像或视频)到文本的相似性和文本到视觉的相似性,并利用视觉到文本和文本到视觉相似性的交叉熵损失来更新自己。相似度通常用点积来实现。最常见的方法就是CLIP。
Word-Region Alignment
单词-区域对齐(WRA)是一种无监督的预训练目标,用于对齐视觉区域(视觉patch)和单词。VLP模型利用最优传输来学习视觉和语言之间的对齐。
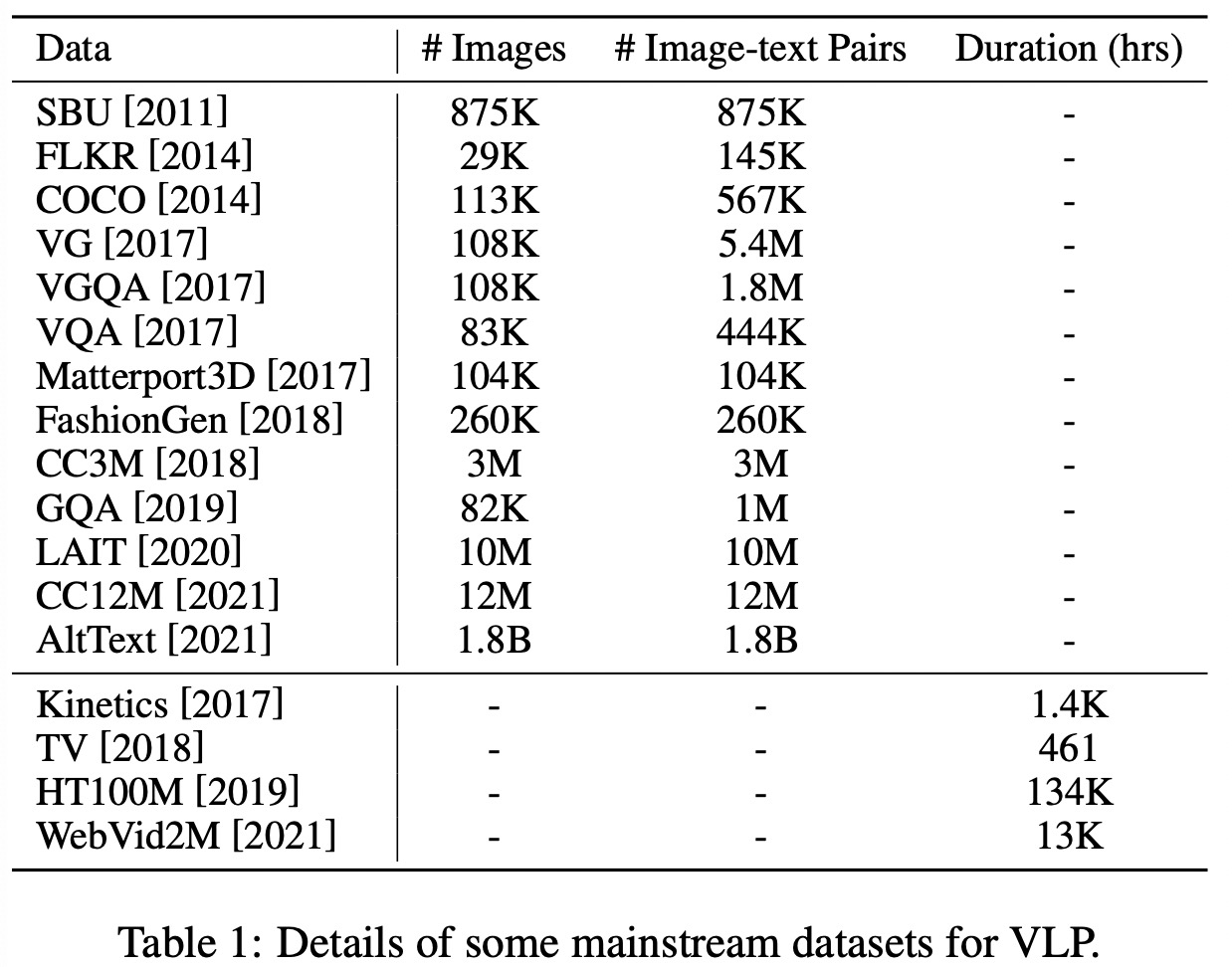
预训练数据集
下游任务
下游任务主要有分类、回归、检索、生成以及其他任务。
分类任务:Visual Question Answering (VQA),Visual Reasoning and Compositional Question Answering (GQA),Video-Language Inference (VLI),Natural Language for Visual Reasoning (NLVR),Visual Entailment (VE),Visual Commonsense Reasoning (VCR),Grounding Referring Expressions (GRE),Category Recognition (CR).
回归任务:Multi-modal Sentiment Analysis (MSA).
检索任务:Vision-Language Retrieval (VLR).
生成任务:Visual Captioning (VC),Novel Object Captioning at Scale (NoCaps),Visual Dialogue (VD).
其他任务:Multi-modal Machine Translation (MMT),Vision-Language Navigation (VLN),Optical Character Recognition (OCR).
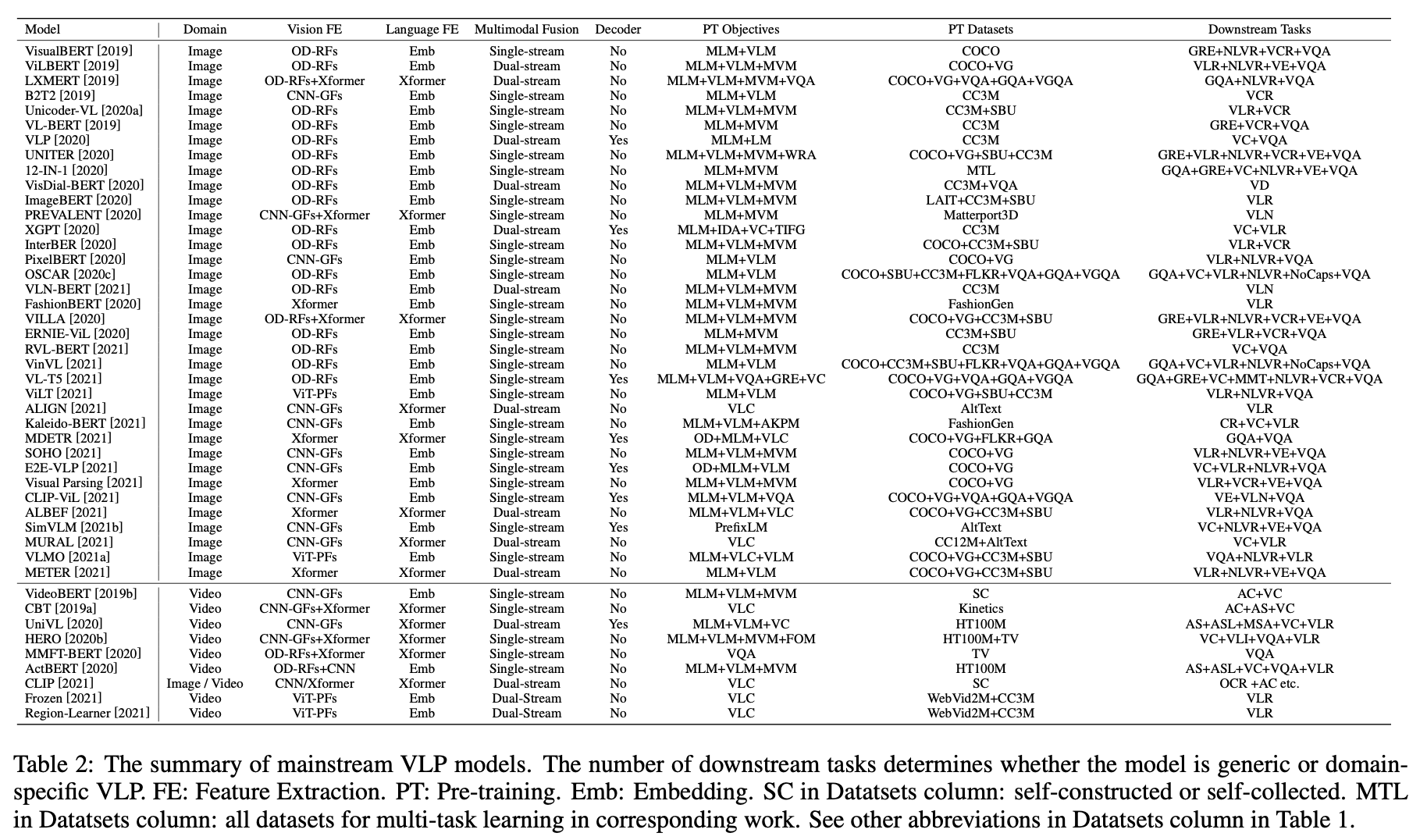
SOTA VLP 模型
最后
第一篇关于VLP的调研综述。文章从特征提取、模型结构、预训练目标、预训练数据集和下游任务五个方面综述了其最新进展,并对具体的SOTA VLP模型进行了详细的总结。这能够帮助研究人员更好地了解VLP,并启发新的工作来推动这一领域的发展。