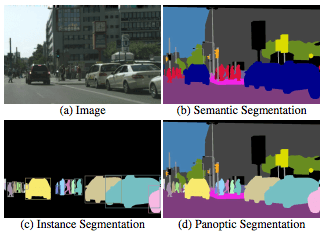
最近在知乎上频繁地刷到有关Mask2Former地帖子,这么多人吹捧地必是精品,就跟一波风看了一下Mask2Former,顺带地也了解一下Panoptic Segmentation这个任务。众所周知,图像分割主要有两个方向:
- 语义分割(semantic segmentation),常用来识别天空、草地、道路等没有固定形状的不可数事物(stuff)。语义分割的标记方法通常是给每个像素加上标签。
- 实例分割(instance segmentation),人、动物或工具等可数的、独立的明显物体(things)。实例分割通常用包围盒或分割掩码标记目标。
全景分割(Panoptic Segmentation)其实就是把这两个方向结合起来,生成统一的、全局的分割图像,既识别事物,也识别物体。
标记方法
全景分割的标记方法结合了语义分割和实例分割,给每个像素加上标签$\left(l{i}, z{i}\right)$,其中i表示第i个像素,l表示语义类别,z表示实例ID。语义类别由两部分组成,事物类别$L^{ST}$和$L^{TH}$分别为stuff和thing的简写)。当$l_{i} \in L^{S T}$,忽略$z_i$(事物类别);
评估标准
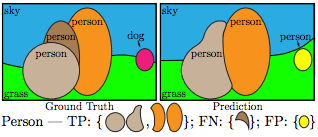
首先是常规的IoU > 0.5,然后结合TF、FN、FP搞出了一个PQ标准。(PQ是Panoptic Quality,即全景质量的简称。)
PQ的具体公式为:
另外,PQ可以分解为分割质量(segmentation quality,SQ)和识别质量(recognition quality,RQ)的乘积,便于进一步评估分割和识别环节的表现。
数据集
全景分割数据集需要既有语义分割标注,也有实例分割标注。
- Cityscapes(19classes):5000张街景图片,97%的图片有像素标注,共有19个类别,其中8个类别符合语义分割的特征;
- ADE20k(150classes):图像总量超过25000张,并经过公开标注。其中包括100种物体和59种事物。
- Mapillary Vistas(65classes):25000张分辨率不同的街景照片。其中98%的图片都经过了像素标注,涵盖28种事物与37种物体。
- COCO:知名数据集COCO最近加入了全景分割标注。
方法
1.MaskFormer
Per-Pixel Classification is Not All You Need for Semantic Segmentation
篇文章提出了一个新的分割输出端范式,传统方法会将每个像素点预测成一种类别来完成分割任务,而本文则是会输出很多个二分类分割图,如下图所示:
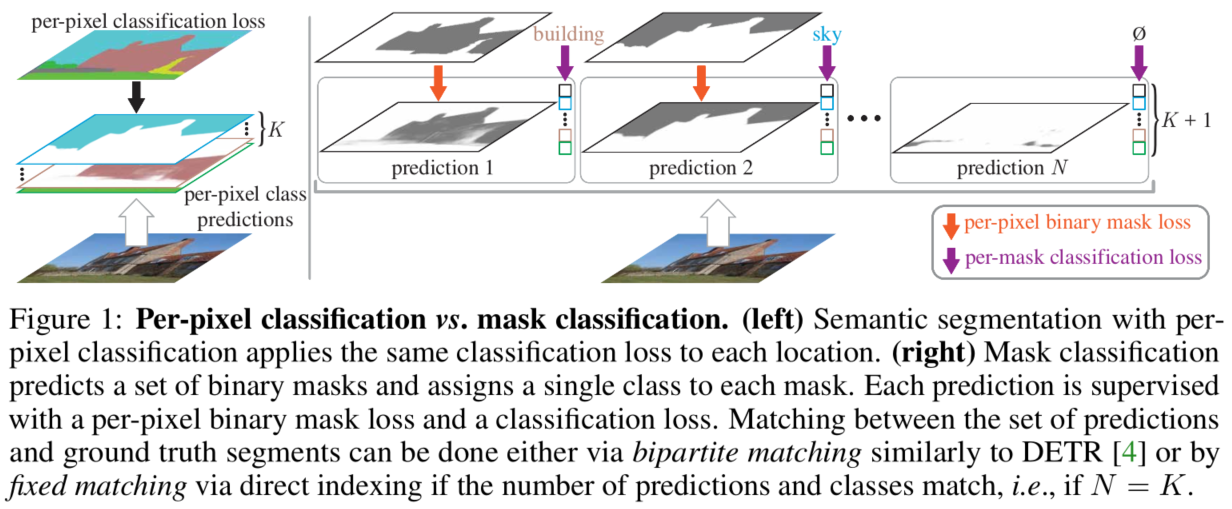
上图左侧为传统方法,右侧为本文方法,不是只输出 K 个类别二值分类图,而是提前设定一个较大值,同时与分类图一同预测的还有一个预测类别,这个类别可以为空,即该二值分类图没有用。因此损失函数由两个组成,一个是预测分类图与真值图的损失,另一个是预测类别的交叉熵损失.
匹配策略上依旧采用匈牙利匹配,匹配成本:
其中,$L_{mask}$为二类交叉熵损失。MaskFormer具体结构如下:
2.Mask2Former
Masked-attention Mask Transformer for Universal Image Segmentation
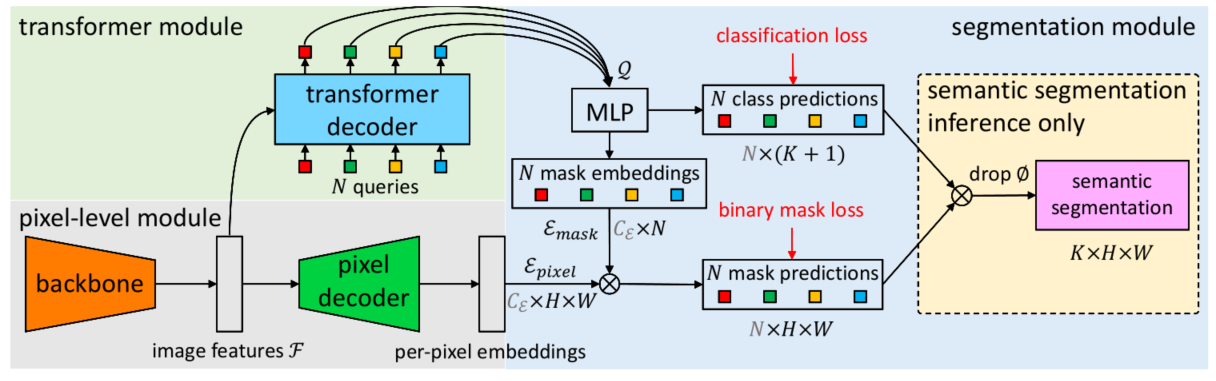
一个model去建模所有的分割任务:语义分割,实例分割和以及全景分割。一个模型取得三个不同分割任务STOA.。具体而言本文方法沿用了上一篇的分割图分别产生方式,另外有两个主要创新点,包括每个transformer decoder层都会使用pixel-decoder的金字塔对应结构,以及 Mask Attention 形式。可参考下图:
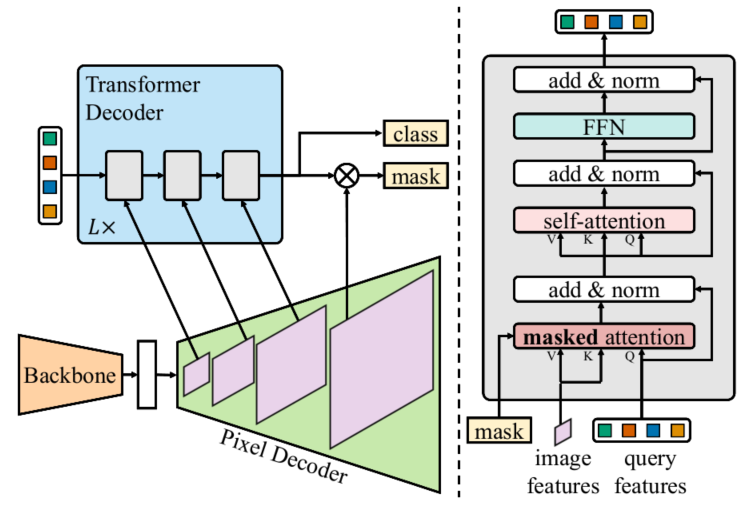
因此,作者基于上述的问题和最初的motivation(一个模型取得三个不同分割任务STOA),提出了几个改进,节省训练的时间(MaskFormer训练需要300epoch)和cost的同时能够提升性能。
第一个改进:Mask Attention加速收敛,相比于之前的cross attention,这个里面的attention affinity是一种稀疏的attention,其实就是将上一层预测的分割图使用阈值0.5转换成[0,1]mask图,将转换后的mask进一步转换成[-inf,0],然后和原始att相加,过softmax得到att_mask,相当于不计算原始分割图中为0的区域att.
standard cross-attention: $\mathbf{X}{l}=\operatorname{softmax}\left(\mathbf{Q}{l} \mathbf{K}{l}^{\mathrm{T}}\right) \mathbf{V}{l}+\mathbf{X}_{l-1}$
masked cross-attention:
具体代码如下:
1 | class MultiScaleMaskedTransformerDecoder(nn.Module): |
第二个改进是多尺度特征改善小目标分割,对应于pixel-decoder,作者使用了类似于Deformable DETR decoder端的设置,在decoder端采用了multi scale的特征输入做attention。这个步骤对于提升small object的segmentation帮助很大。具体代码如下:
1 | class MSDeformAttnPixelDecoder(nn.Module): |
此外,文章还额外提出了三个小改进:
- 将 Self 和 Cross Attention 的顺序做一个变换,让 Cross 在前面,因为在图像特征没加入计算时自身做 Self 效率会较低;
- 文章将 Transformer 解码器的初始序列设置为可学版本;
- 整个模型将不使用 dropout 操作。
- 使用point-rend head 改善分割边界质量,同时降低显存;
mask2former/modeling/meta_arch/mask_former_head.py
backbone:res50
800x800(short size=800) —>res2[1, 256, 200, 200],res3[1, 512, 100, 100],res4[1, 1024, 50, 50],res5[1, 2048, 25, 25],
pixel decoder:MSDeformAttnPixelDecoder(6 layers)
res3,res4,res5—>MSDeformAttnTransformerEncoderOnly—>x1[1, 256, 25, 25],x2[1, 256, 50, 50],x3[1, 256, 100, 100],
x1,x2,x3+FPN(res2) —->x1[1, 256, 25, 25],x2[1, 256, 50, 50],x3[1, 256, 100, 100],x4[1, 256, 200, 200]
res3,res4,res5—> mask_features:conv[x4],transformer_encoder_features:x4,multi_scale_features:[x1,x2,x3]
Transformer decoder:MultiScaleMaskedTransformerDecoder
input:multi_scale_features,mask_features
query_feat(100x256),mask_features[1, 256, 200, 200] —>forward_prediction_heads—>outputs_class[1, 100, 134],outputs_mask[1, 100, 200, 200],attn_mask[8, 100, 625],attn_mask是有outputs_mask插值降采样得到
3.PointRend
文中使用了各种术语,比如rend、subdivision、ray-tracing,是想说明一个问题: 图像是对真实目标的一个离散化表达,真实目标的一些属性,如区域联通性、边缘连续性,在图像中同样存在。那么分割问题就可以看作预测一个真实目标在离散化后的图像中所占的区域,即:point-wise label prediction(点对点分类)。连续性体现在:图像中的像素可以通过插值得到与真实目标一一对应的坐标点。分割是在离散化的网格区域点对点的分类,但是有些点很难分类的准确,这些点大部分处在目标的边缘。pointrend方法的提出是对这些模糊分割的点,做更进一步的预测,即:精细分割。主要分成3步,如下图所示:1)候选点(或模糊分割点)选取;2)点特征提取;3)点分割预测。
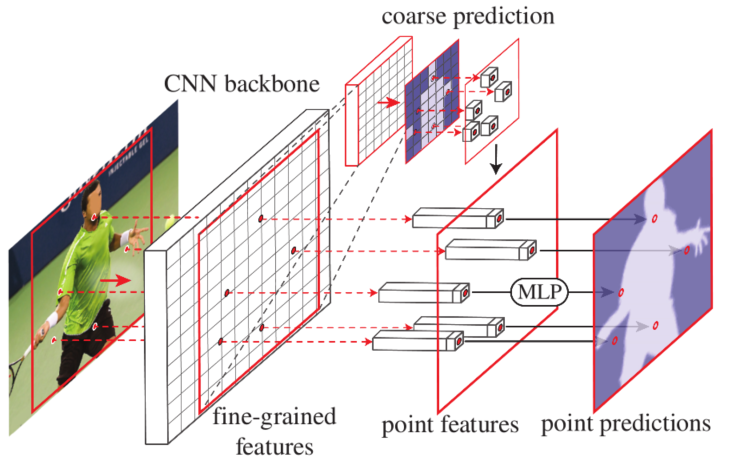
1.候选点选取
候选点选取在训练和测试过程是不一样的,其中推断过程是通过迭代的方式从一个低分辨率的分割图像得到一个高分辨率的图像,这种方式不适合训练过程中的梯度反传,故采用另一种方式。
Point select for training
- 随机生成kN个点,其中k>1。
- 估计这kN个点的不确定程度,并根据不确定程度,筛选前βN个点,β取值范围为[0, 1]。其中不确定程度的估计方式与推断过程估计方式相同,使用低分辨率的分割置信度。
- 在剩余的点中,均匀采用得到(1-β)N个点。
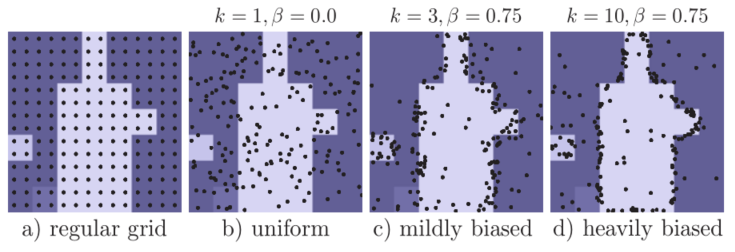
在PointRend中,采用了k=3和$\beta=0.75$的采样策略参数,采样得到$14^{2}$个点;从 coarse prediction 中插值的 GT 类别的概率和 0.5 之间的距离作为 point-wise 不确定性度量.
Point select for inference
推断过程是迭代进行的,具体过程如下图所示,首先通过上采样,将模型直接输出的低分辨率的分割图的长宽各扩大2倍得到高分辨的分割图,如从4x4的特征图上采样得到8x8的特征图;然后在高分辨分割图中,筛选N个分割模糊的点,即分割置信度(若置信度区间为[0,1])在0.5左右的点,如在下图8x8的高分辨率分割图中,点集中在边缘附近。这N个点为最终筛选出来进行再次确认的点。以此类推,逐步迭代,得到最终目标分辨率的分割图。
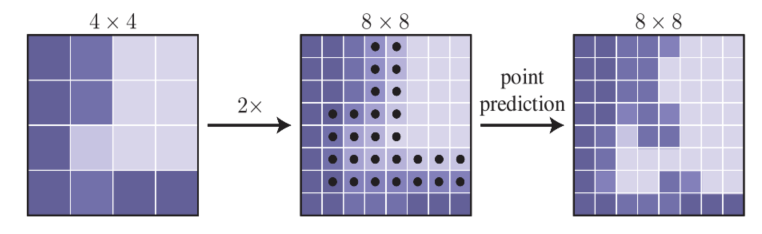
在PointRend中,对于预测类别 c 的矩形框,除非特别说明,均采用 adaptive subdivision 来通过 5 steps 将 7x7 coarse 预测精细化到 224x224. 每一次迭代,选择并更新 $N=28^2$个基于预测值和 0.5 之间的差异性距离得到最不确定的点.
2.点特征提取
点特征提取包括fine-grained特征和coarse特征,其中coarse为K维,来自低分辨的分割mask,fine-grained特征来自原cnn backbone某个stage或者多个stage的组合特征。文中使用P2层的卷积特征作为fine-grained特征提取的特征图,具体流程如下图。
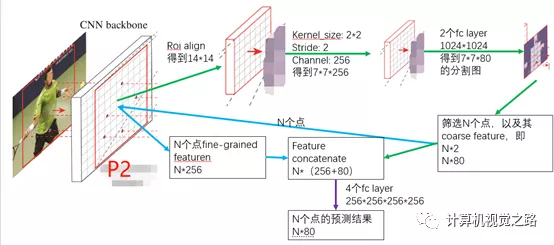
3. 点分割预测
如上图所示紫色箭头,得到候选点的特征表达后,经过一组MLP,来得到最后的N个点的分割预测结果。其中,在实验中使用了4个全连接层,其中每个全连接层的输出,都联合coarse feature,作为下一个全连接层的输入。
5. Results

其中左边一列图为mask rcnn的结果,右边一列图为PointRend的结果,从视觉效果看,PointRend对物体边缘描述更加精细化。
4.Panoptic SegFormer
Delving Deeper into Panoptic Segmentation with Transformers
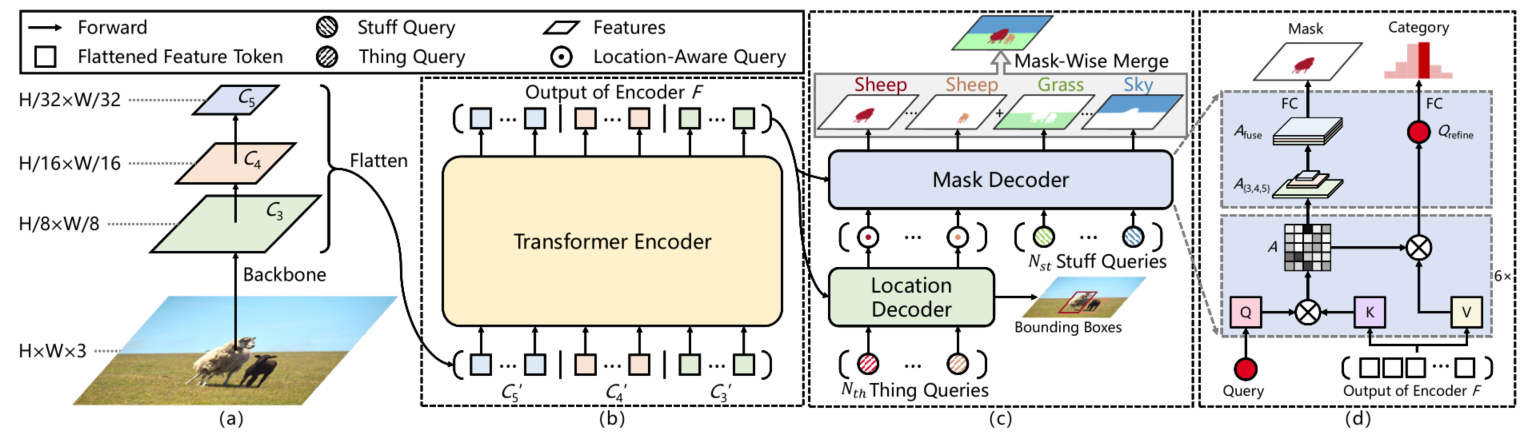
该结构与DETR类似,不同之处在于:
(1)backbone使用多尺度特征(C3,C4,C5);
(2)针对decoder中query做了进一步精细划分,解耦location和Mask。针对Thing Query使用location Decoder捕获thing类别位置信息对Thing Query进行refine;此后使用refine后的Thing Query和Stuff Query作为Mask Decoder 输出mask结果。其中location Decoders使用bbox信息辅助监督,可以加速网络收敛;
(3)后处理部分,使用Mask-wise merge策略融合things和stuff获取最终的mask结果.
下面详细讲一下location decoder、mask decoder和mask-wise merge部分。
Location Decoder
给定N个初始化queries,训练阶段,在location decoder后面添加一个辅助MLP来预测位置和尺寸,location decoder的输出称为location-aware queries;推理阶段,去除辅助MLP。这一个辅助loss,可以帮助网络快速收敛,每个query关注区域指向性更明确。
Mask Decoder
mask decoder将location decoder的输出location-wise queries当作query,和MaskFormer预测mask和类别不同的是,Panoptic SegFormer预测mask需要先将attention map拆分成A3,A4,A5,然后都上采样到H/8xW/8的分辨率,concat在一起得到A_fuse,最后通过1x1卷积得到mask预测结果。
Mask-wise merge

之前的分割去重,一般都是使用pixel-wise argmax策略,也就是重叠部分保留预测分数最大的类别。本文提出的mask-wise merge策略,对于重叠部分进行舍弃,上图是伪代码。
很喜欢作者在conclusion里面提到的一句话, Given the similarities and differences among the various segmentation tasks, “seek common ground while reserving differences” is a more reasonable guiding ideology. 完全的统一框架不见得是最好的选择,“求同存异”才是一个更合理的指导思想。
代码链接:https://github.com/zhiqi-li/Panoptic-SegFormer
结果复现:
| Method | PQ | SQ | RQ | N |
|---|---|---|---|---|
| All(paper) | 49.600 | 81.600 | 59.900 | 133 |
| All(rep) | 49.900 | 81.500 | 60.200 | 133 |
5. K-Net
K-Net: Towards Unified Image Segmentation
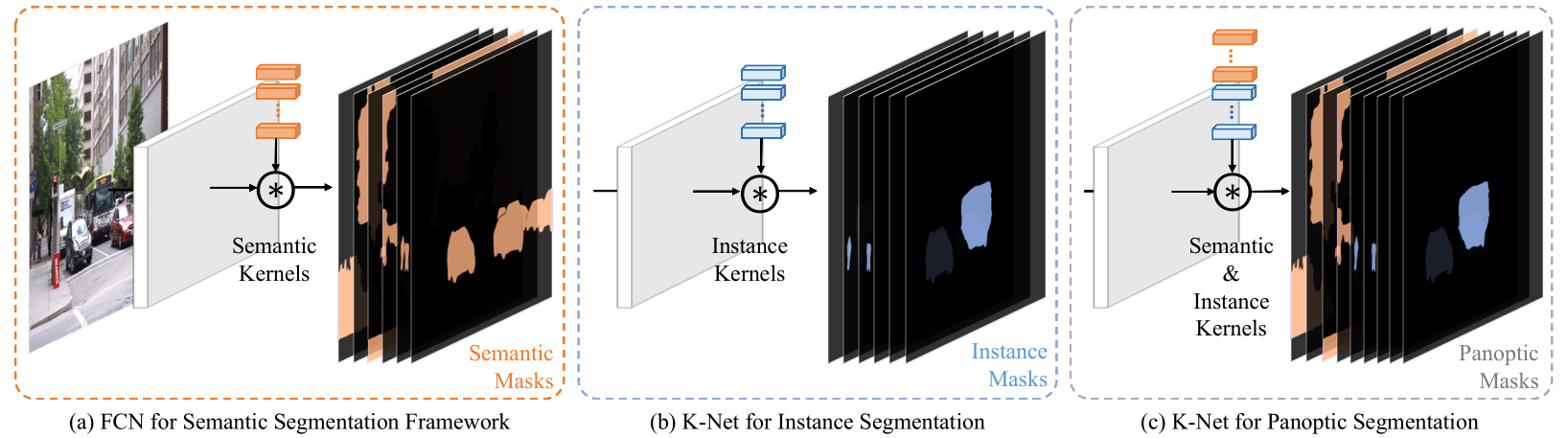
K-Net的目标也是在于统一实例分割和语义分割。如上图所示,语义分割核心结构就是由一组kernel来负责语义mask的生成,让kernel数量与数据集类别数据保持一致,每个kernel负责一个固定类别masker的生成。受此启发,在实例分割中,可以通过同样方式引入一组卷积核来负责 mask 的生成,限定一个 kernel 只分割一个物体,每个kernel负责分割不同的物体,实例分割任务统一到一个框架内。
Group-Aware Kernels
理论上一组instance kernel就可以得到实例分割结果,但实验结果却相差甚远,与sem seg 相比,ins seg需要的kernel要求更高:
(1)在sem seg中,每个单独的sem kernel与类别(sem class)是绑定的,在每张图上都可以学习分割同一个类别,而ins seg不具备,而是通过Bipartite matching 来做的 target assignment,这导致每个kernel在每张图上学习的目标是根据当前的预测情况动态分配的。
(2)ins kernel需要区分appearence和scale变化的物体,需要具备更强的判别特性;
基于此,作者设计了Kernel Update Head 基于 mask 和特征图来将 kernel 动态化;如下图所示,Kernel Update Head 首先获得每个 kernel 对应 pixel group 的 feature,然后以某种方式动态地更新当前kernel。
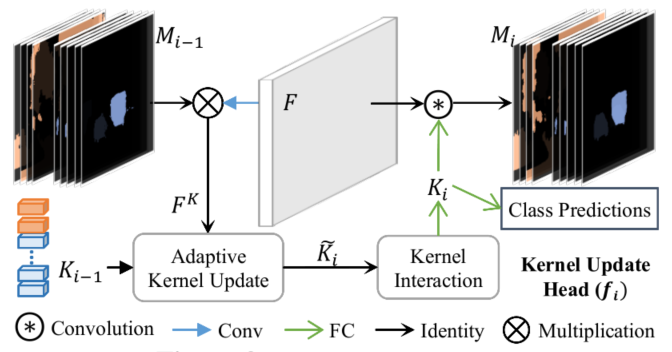
此外,为了使得kernel可以modeling全局信息,作者还新增kernel interaction模块,最终得到的特征可用于class prediction, dynamic kernels 和mask predictions.
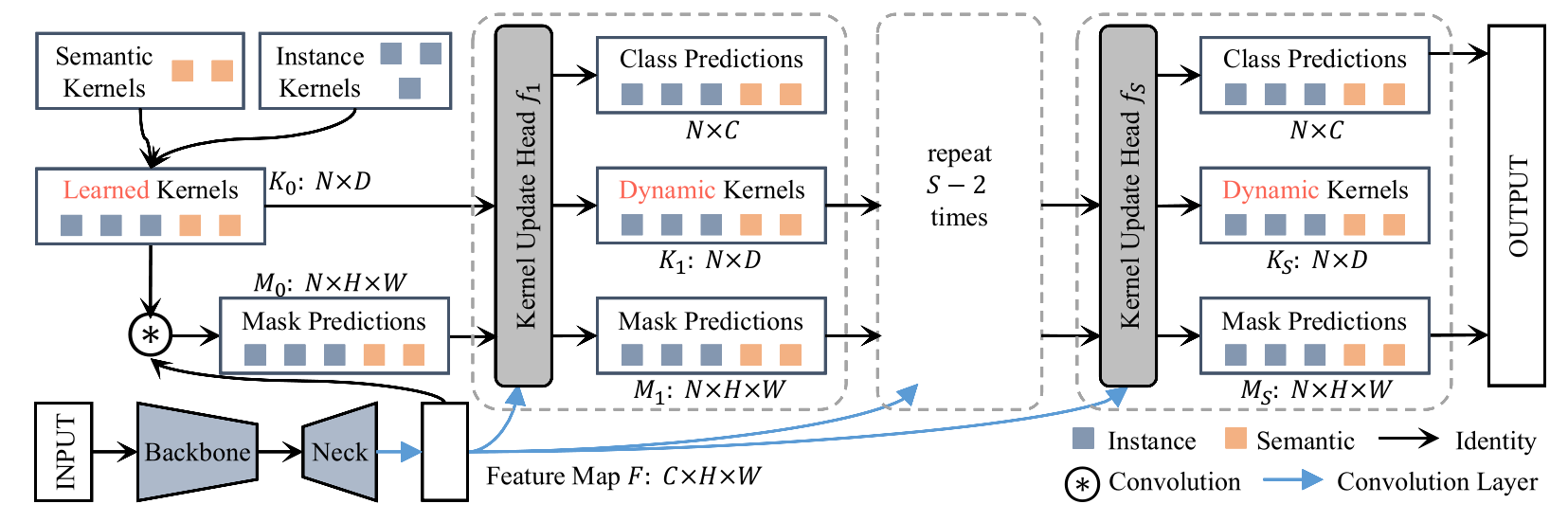
为了得到更精细化的mask,可以通过叠加多个Kernel Update Head对mask和kernel进行迭代式refine.最终K-Net pipeline如上图所示,在论文中使用了3个Kernel Update Head和100个ins kernel.
注:在COCO-Panoptic上多尺度训练36epoch,训练一个K-Net,使用16张V1100需要两天半,在两台机器的情况下,训练时间有点长。