本文要介绍的是微软的俩篇有关VLP的工作,Oscar和METER,前者是发表在CVPR2020,后者是发表在CVPR2022。论文链接如下:Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks,An Empirical Study of Training End-to-End Vision-and-Language Transformers,下面大致介绍这俩篇工作的具体内容。
ALBEF方法详解
这篇文章介绍一篇多模态预训练相关的论文,Align before Fuse: Vision and Language Representation Learning with Momentum Distillation,单位是Salesforce Research,下面大致的介绍一下两篇论文的具体工作。这篇paper提出了一个新的视觉-语言表征学习框架,通过在融合之前首先对齐单模态表征来实现最佳性能。
BERT原理详解与HuggingFace使用[转载]
最近在做一些图文理解相关的工作,顺带了解了一下BERT,自BERT(Bidirectional Encoder Representations from Transformer)出现后,NLP界开启了一个全新的范式。本文主要介绍BERT的原理,以及如何使用HuggingFace提供的 transformers 库完成基于BERT的微调任务。
文本分词详解
在对文本进行处理时,我们需要进行文本预处理 ,而最重要的一步就是分词(Tokenize) 。一个完整的分词流程如下:
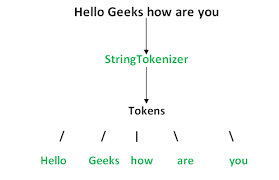
其中,执行分词的算法模型称为分词器(Tokenizer) ,划分好的一个个词称为 Token (为啥不直接叫 Word?接着往后看),这个过程称为 Tokenization 。我们将一个个的 token(可以理解为小片段)表示向量,我们分词的目的就是尽可能的让这些向量蕴含更多有用的信息,然后把这些向量输入到算法模型中。由于一篇文本的词往往太多了,为了方便算法模型训练,我们会选取出频率 (也可能是其它的权重)最高的若干个词组成一个词表(Vocabulary) 。
Deformable-DETR详解与代码解读
DETR是第一个end2end的目标检测器,不需要众多手工设计组件(anchor,iou匹配,nms后处理等),但也存在收敛慢,能处理的特征分辨率有限等缺陷。原因大概存在如下:
- transformer在初始化时,分配给所有特征像素的注意力权重几乎均等;这就造成了模型需要长时间去学习关注真正有意义的位置,这些位置应该是稀疏的;
- transformer在计算注意力权重时,伴随着高计算量与空间复杂度。特别是在编码器部分,与特征像素点的数量成平方级关系,因此难以处理高分辨率的特征;
pix2seq方法详解
本文分享seq2seq learning相关的两篇论文,单位是google brain,一作均为Ting Chen(自监督学习方法SimCLR的作者),论文地址:pix2seq: A Language Modeling Framework for Object Detection,[ICLR2022接收];A Unified Sequence Interface for Vision Tasks,[上星期挂arxiv],后者是对前者在多个视觉任务上的拓展。下面大致的介绍一下两篇论文的具体工作。
ViLD基于CLIP模型的zero-shot目标检测方法
论文信息:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
代码链接:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
整体信息:这是google research 发表在ICLR2022上有关CLIP在下游任务-目标检测任务上的应用。使用CLIP模型实现zero-shot场景下的目标检测任务。比较有想象意义的是,通过一句话就可以检测出图像中需要的指定目标。在之前CLIP图文多模态对比预训练方法详解中也有提及过这篇工作。
DeCLIP一种数据高效的CLIP训练方法
论文信息:Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
代码链接:https://github.com/Sense-GVT/DeCLIP
整体信息:这是商汤科技发表在ICLR2022上关于多模态预训练的工作,在前面的文章中介绍过CLIP,是一种基于对比文本-图像对的预训练方法,该方法需要在大量的图像-文本对数据集进行训练,在CLIP工作上就使用了4亿的图像-文本对数据,数百张卡进行预训练。为了提高训练效率,这篇工作提出了DeCLIP(Data Efficiency CLIP)方法,在较少数据下依旧可以取得不错的效果。