CLIP是OpenAI在2021年发表的一种用NLP来监督CV的方法。成功连接文本和图像。CLIP全称是, Contrastive Language–Image Pre-training,一种基于对比文本-图像对的预训练方法。在了解CLIP具体方法之前,可以先看一下该工作的在一些下游任务的应用。
应用
1.风格迁移styleCLIP

styleCLIP很神奇,CLIP可以理解各种抽象的妆容,比如发型,卸妆等等
2.文本生成图像CLIPDraw

这个也是使用CLIP指导模型的生成,甚至无需训练,就可以生成简笔画,颇具有抽象派画风。
3.开集目标检测ViLD
传统目标检测方法可能只能告诉你以上均是玩具类别,但是基于CLIP还可以知道玩具颜色,玩具种类。
4.文本视频检索Clifs

CLIP还可以用于视频检索,如上图所示,告知“A truck with the text “odwalla””,可以基于文本内容检索到视频中对应帧的位置。
动机
现有的模型都是基于固定的预定义物体类别集合进行监督训练。比如coco 80类等。但是这种限制性的监督型号限制了模型本身的泛化性,当需要识别新物体类别时需要重新收集新的数据重新训练,因此作者想到使用NLP里面文本信息获取监督信号。
具体方法
CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。

这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本-图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出 $N^2$ 个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的个$N^2-N$个文本-图像对为负样本,那么CLIP的训练目标就是最大个N正样本的相似度,同时最小化$N^2-N$个负样本的相似度,对应的伪代码实现如下所示:
1 | # image_encoder - ResNet or Vision Transformer |
为了训练CLIP,OpenAI从互联网收集了4亿文本-图像对,论文称之为WebImageText。论文中Text Encoder固定选择一个包含63M参数的text transformer模型,而Image Encoder采用了两种的不同的架构,一是常用的CNN架构ResNet,二是基于transformer的ViT,其中ResNet包含5个不同大小的模型:ResNet50,ResNet101,RN50x4,RN50x16和RNx64(后面三个模型是按照EfficientNet缩放规则对ResNet分别增大4x,16x和64x得到),而ViT选择3个不同大小的模型:ViT-B/32,ViT-B/16和ViT-L/14。所有的模型都训练32个epoch,采用AdamW优化器,而且训练过程采用了一个较大的batch size:32768。由于数据量较大,最大的ResNet模型RN50x64需要在592个V100卡上训练18天,而最大ViT模型ViT-L/14需要在256张V100卡上训练12天,可见要训练CLIP需要耗费多大的资源。对于ViT-L/14,还在336的分辨率下额外finetune了一个epoch来增强性能,论文发现这个模型效果最好,记为ViT-L/14@336,论文中进行对比实验的CLIP模型也采用这个。
值得思考的是,在CLIP中,作者没有采用预测式的目标函数优化模型,而是采样对比学习的方式进行优化,在这一块,原文有介绍,使用对比学习的方式训练模型,放宽了约束,模型也更容易收敛,相比于预测型监督,对比式监督可以提升4倍的训练效率。
使用CLIP实现zero-shot分类
当CLIP预训练好之后,有俩个编码器Text Encoder和Image Encoder,基于这俩训练好的encoder可以直接实现zero-shot分类,即无需任何训练数据,就能在某个下游任务上实现分类。具体步骤:

- 根据分类任务的分类标签构建每个类别的描述文本:A photo of {label}, 然后将这些文本送入Text Encoder获得对应的文本特征,如果类别数目为N,那么得到N个文本特征。
- 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算余弦相似度,将相似度大的作为图像预测类别。
在zero-shot分类任务上,CLIP在多个数据集上取得优于在imagenet上fine的res101,具体可以看下图的结果对比:
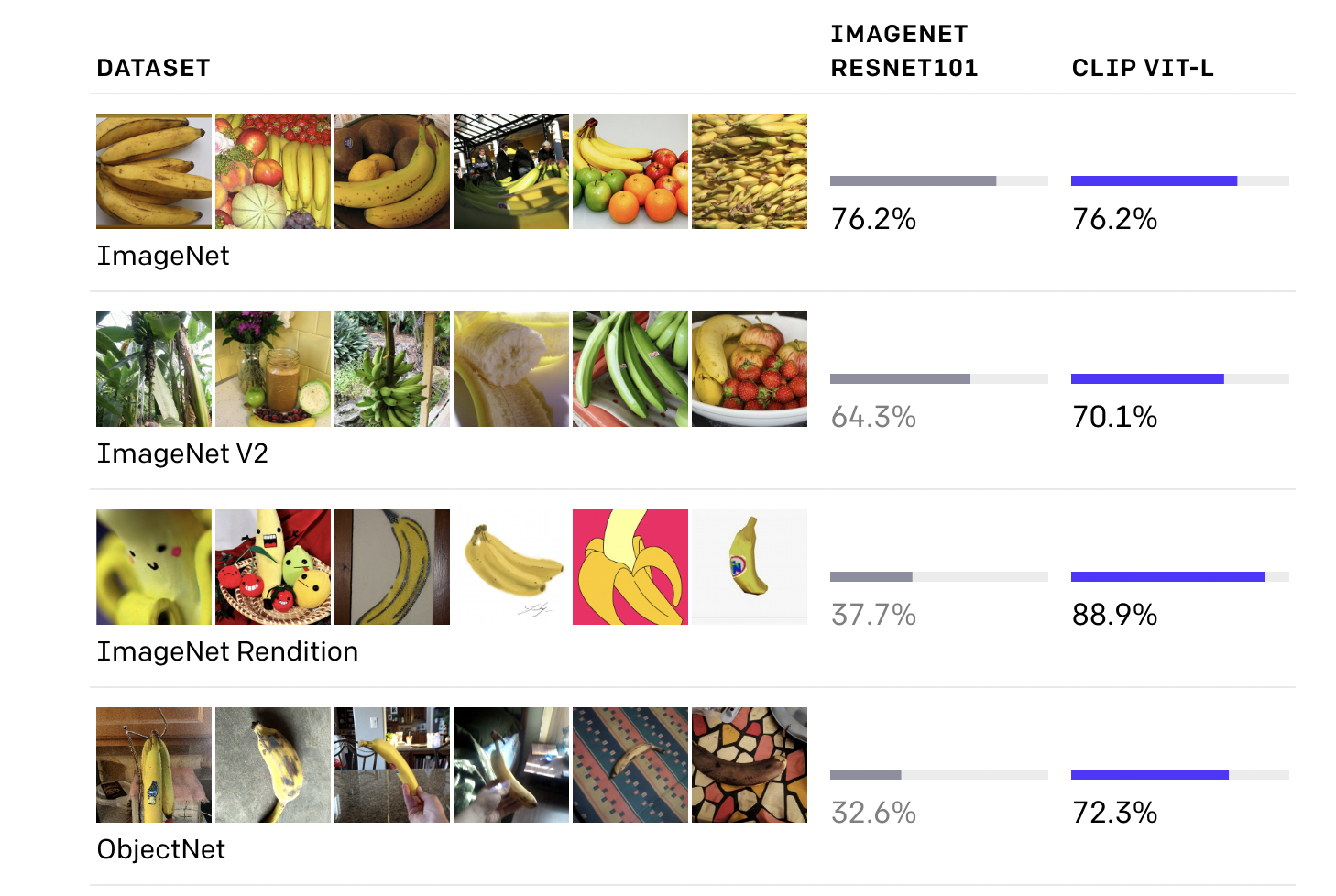
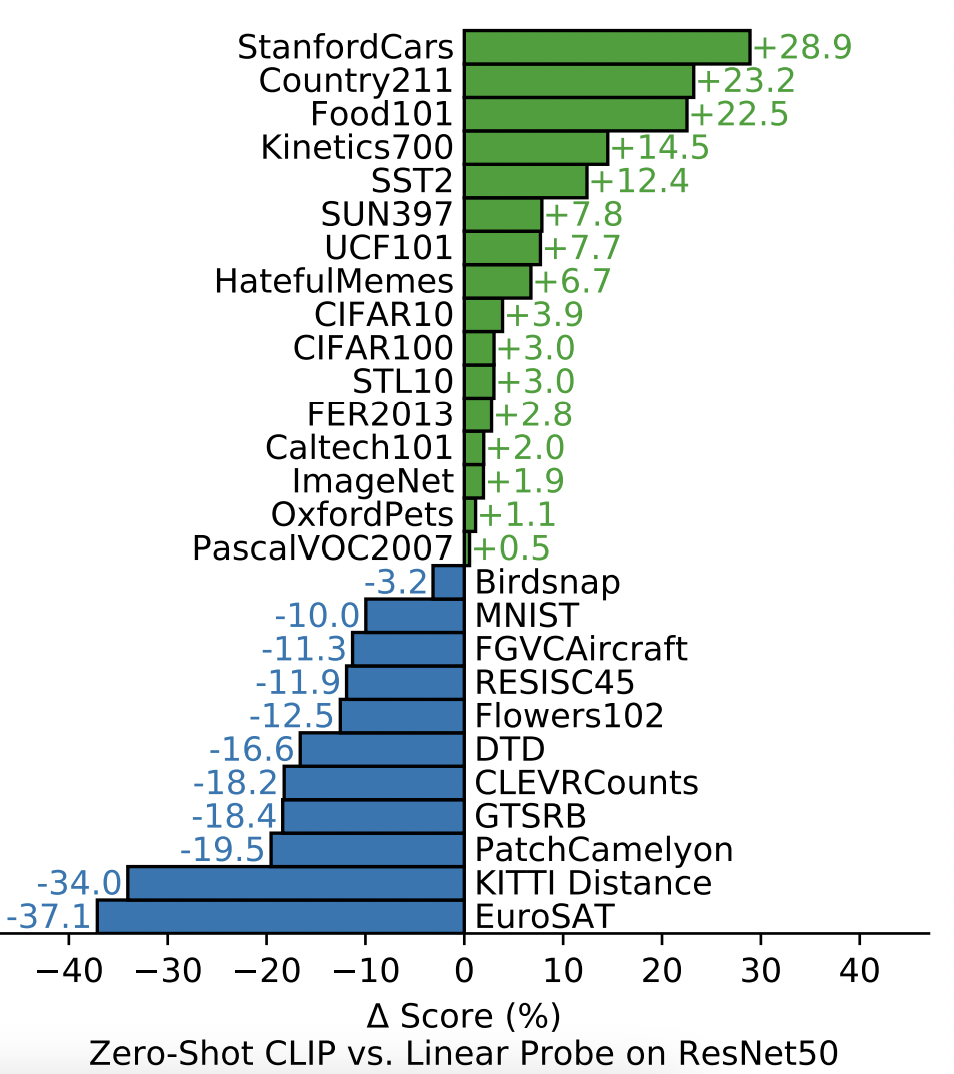
在zero-shot任务上,作者在linear probe基础上做了详尽的实验,首先作者通过和经过强监督学习的Resnet-50提取的特征对比,任务都是分类任务,因此作者基于Resnet-50和CLIP提取出的特征,只是训练了最后的分类器,分类结果如下图所示。可以发现仅仅通过无监督的对比学习预训练得到的特征,即便是和强监督模型特征相比也是不分伯仲的。同时可以发现,zero-shot CLIP在一些动作识别任务中,比如Kinetics 700,UCF 101中有着比较大的提高,作者认为这可能是因为目前的文本描述中有很多以动词,动作为中心的句子导致的。
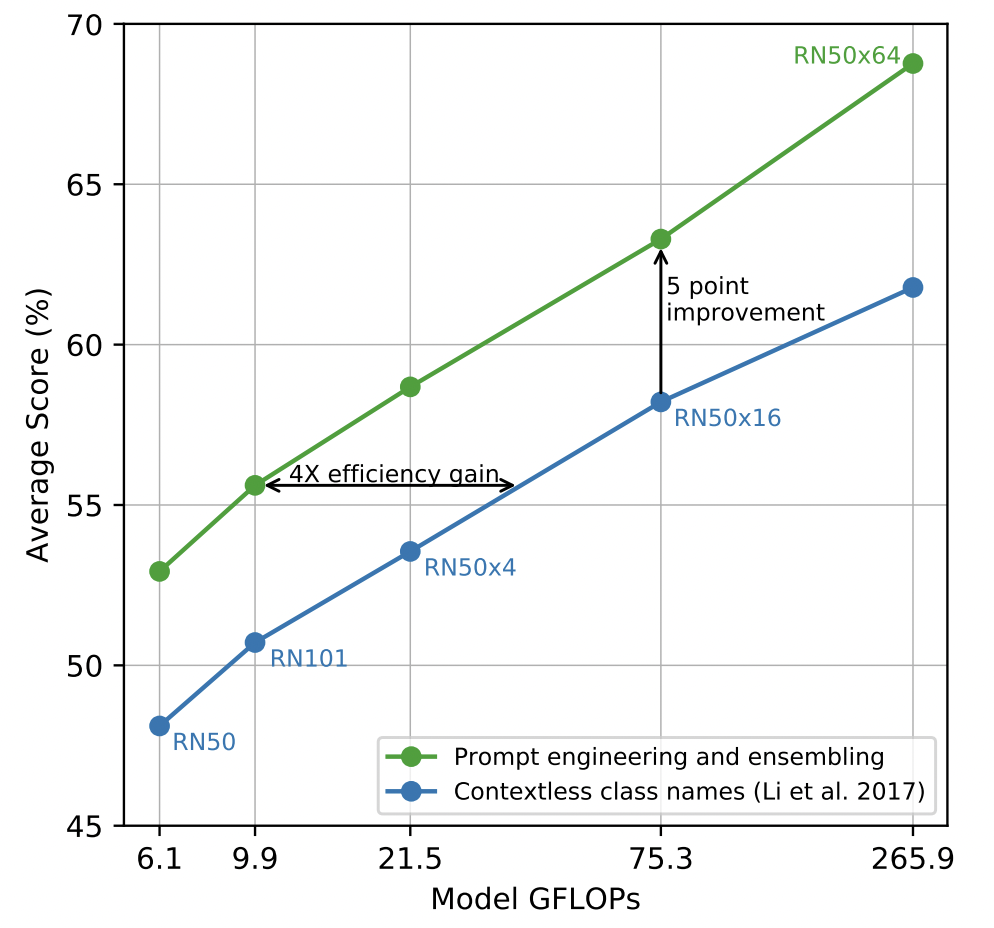
prompt engineering
考虑到以单词作为标签存在歧义情况,比如在Oxford-IIIT Pet dataset 数据集中boxer表示斗牛犬,而在其他数据集中则可能表示拳击运动;在ImageNet中,crane同时表示了起重机和鹤。这种词语的多义显然对是因为缺少对标签的上下文描述导致的。为了解决这种问题,作者在指示上下文中添加了一些提示标签类型的词语,比如A photo of a <LABEL>, a type of pet.。作者将这个方法称之为“prompt engineering”。在合适地选取了不同的指示上下文,并且将其打分进行ensemble之后。作者发现这些Tricks竟能在zero-shot实验上提高5个绝对百分位,如Fig 2.3所示。
limitation
这部分是最容易被忽略,但个人认为这部分往往更引人深思,这里简单的总结一下我关注的几个CLIP的limitation:
- CLIP在zero-shot上的性能虽然总体上比supervised baseline res50要好,但是在很多任务上是比不过sota,因此CLIP的迁移学习有待挖掘;
- CLIP在一下几种task上的性能不好:细粒度分类,计数等任务;
- CLIP本质上还是在有限的类别中进行对比推理,无法像image caption那样完全地灵活地生成新的概念,不同于生成模型;
- CLIP依旧没有解决深度学习poor data efficiency的问题;
结论
CLIP可以再预训练阶段学习到更多通用的视觉语义信息,并且给下游任务提供帮助。而且相比于以往的训练方法,打破了之前的固定种类标签的范式。