本文分享seq2seq learning相关的两篇论文,单位是google brain,一作均为Ting Chen(自监督学习方法SimCLR的作者),论文地址:pix2seq: A Language Modeling Framework for Object Detection,[ICLR2022接收];A Unified Sequence Interface for Vision Tasks,[上星期挂arxiv],后者是对前者在多个视觉任务上的拓展。下面大致的介绍一下两篇论文的具体工作。
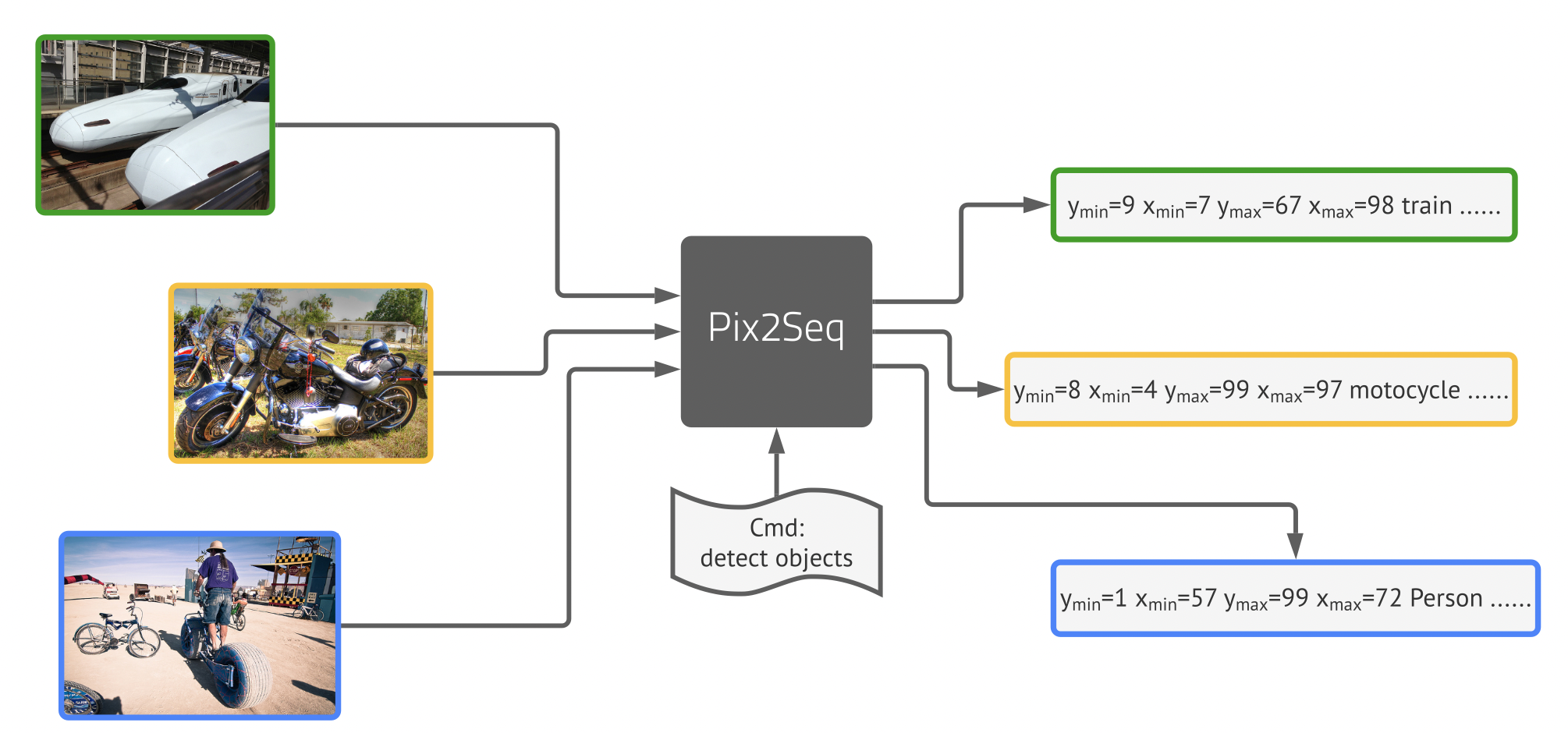
Pix2seq
主要方法
pix2seq将目标检测任务转换为语言建模来处理,以往目标检测任务基于属性进行预测,通常会分为分类预测+回归预测。而该方法是通过将object的类别和box信息构造成序列,对序列进行预测。pix2seq的结构和学习过程由四个部分组成,如下图所示:
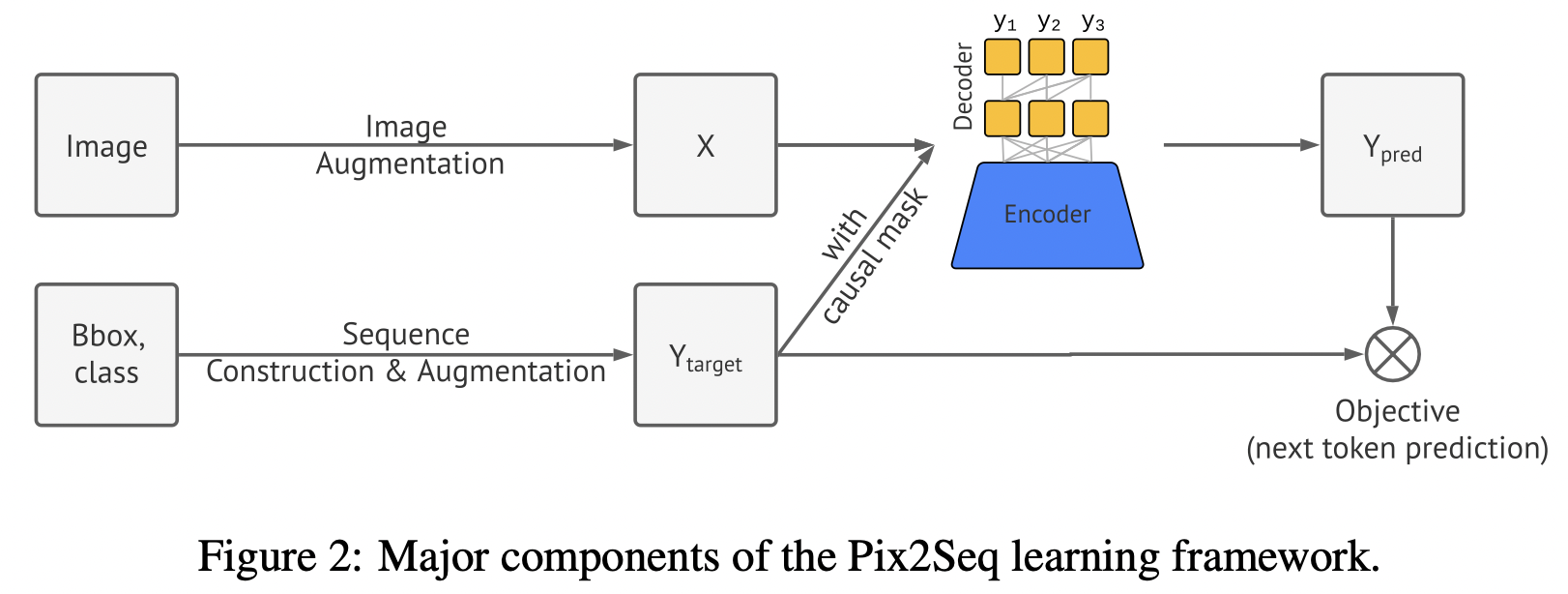
Pix2seq主要包含四部分:
- Image augmentation:图像数据增强,包括random scale+crops;
- Sequence construction & augmentation:构造序列和序列增强,将bbox和label转换为离散的token;
- Architecture:使用encoder-decoder结构将输入图像pixel转换为序列;
- Objective/loss function:常用的softmax 交叉熵损失;
序列化

这里详细介绍一下box+cls序列化方法,为了和自然语言对齐,它把坐标框(4个值)和类别(1)都拼成一个序列,意味着100个目标对应着长度为500的序列。因为坐标是连续值,作者这里用了一个分桶的机制,把坐标分到n个桶里(bin),就构成了离散值。具体地,一个目标被表示为一个由五个离散的[token]组成的序列,即[ymin, xmin, ymax, xmax, c],其中每个连续的角坐标被均匀地离散为[1, nbins]之间的一个整数,c是类索引。我们对所有标记使用共享词汇表,因此词汇量大小等于 bin 数+类别数。对于600x600的图片而言,使用600个bin就可以实现零量化误差,其实整个离散值的范围比起nlp里的字典而言,还是非常非常小的。
实验结果
在构建好序列之后,使用Resnet + 6层transformer encoder + 6层transformer decoder对输入图像进行序列化,然后使用交叉熵计算损失。作者分别在train from scratch和finetune两种setting下进行了一些实验对比。
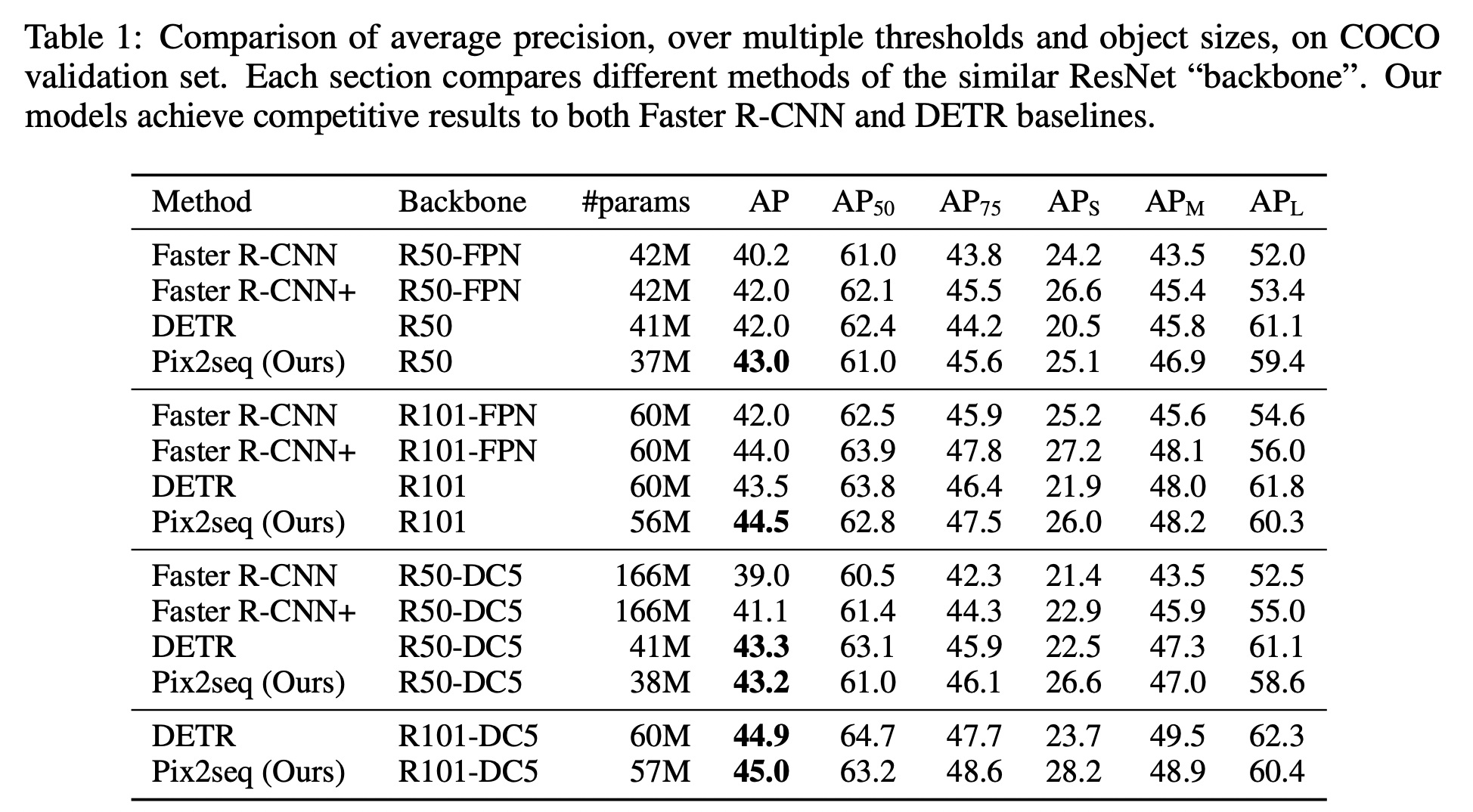
从上面结果来看,相比较而言,在指标上优势并不明显,但足矣证明本文的idea是可行的。在train from scratch的setting下,pix2seq是训练了300epoch,表格上之所以并没表明对比方法训练的epoch数,可能这正是pix2seq的一个缺点,训练收敛慢。
PixSeq v2
主要方法
Pixseq v2是上周Ting Chen挂在arxiv的对pix2seq在多个视觉任务上拓展的一个工作,总的来说,作者并没有对模型层面做进一步改进,但对不同视觉task的输入输出接口做了统一。如下图所示,
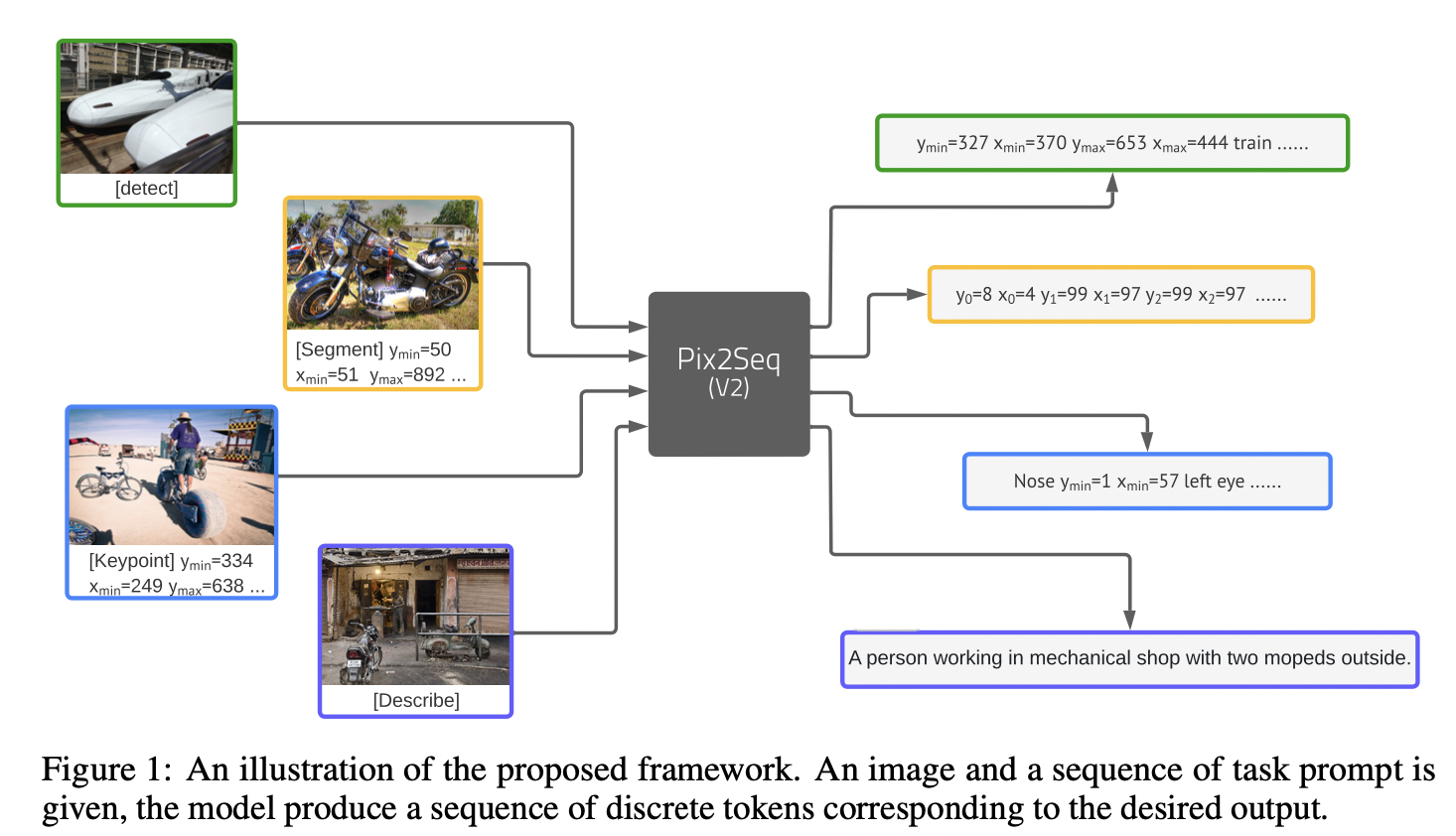
以往的视觉任务比如,目标检测、实例分割、关键点检测和图像描述等任务都是单独设计不同模型、不同输入、不同损失函数来解决,而本文将每个任务的输出形式化为具有一个统一接口的一个离散的token序列,可以做到在所有这些任务上仅训练一个具有单一模型结构和损失函数的神经网络,而不需要针对特定任务进行模型结构或损失函数的定制。为了解决一个特定的任务,本文使用一个简短的prompt作为该任务的描述,网络的输出序列适应于该prompt,因此模型能够产生特定于任务的输出。
- 对于目标检测任务,遵循pix2seq做法,通过量化连续图像坐标,将box和cls转换为一系列离散token;
- 对于实例分割任务,以图像坐标序列形式预测polygon,与检测任务一样,对坐标进行量化离散为token;
- 对于关键点预测任务,给定一个人体实例,将关键点预测为一个量化的图像坐标序列;
- 对于图像描述,直接预测文本token。
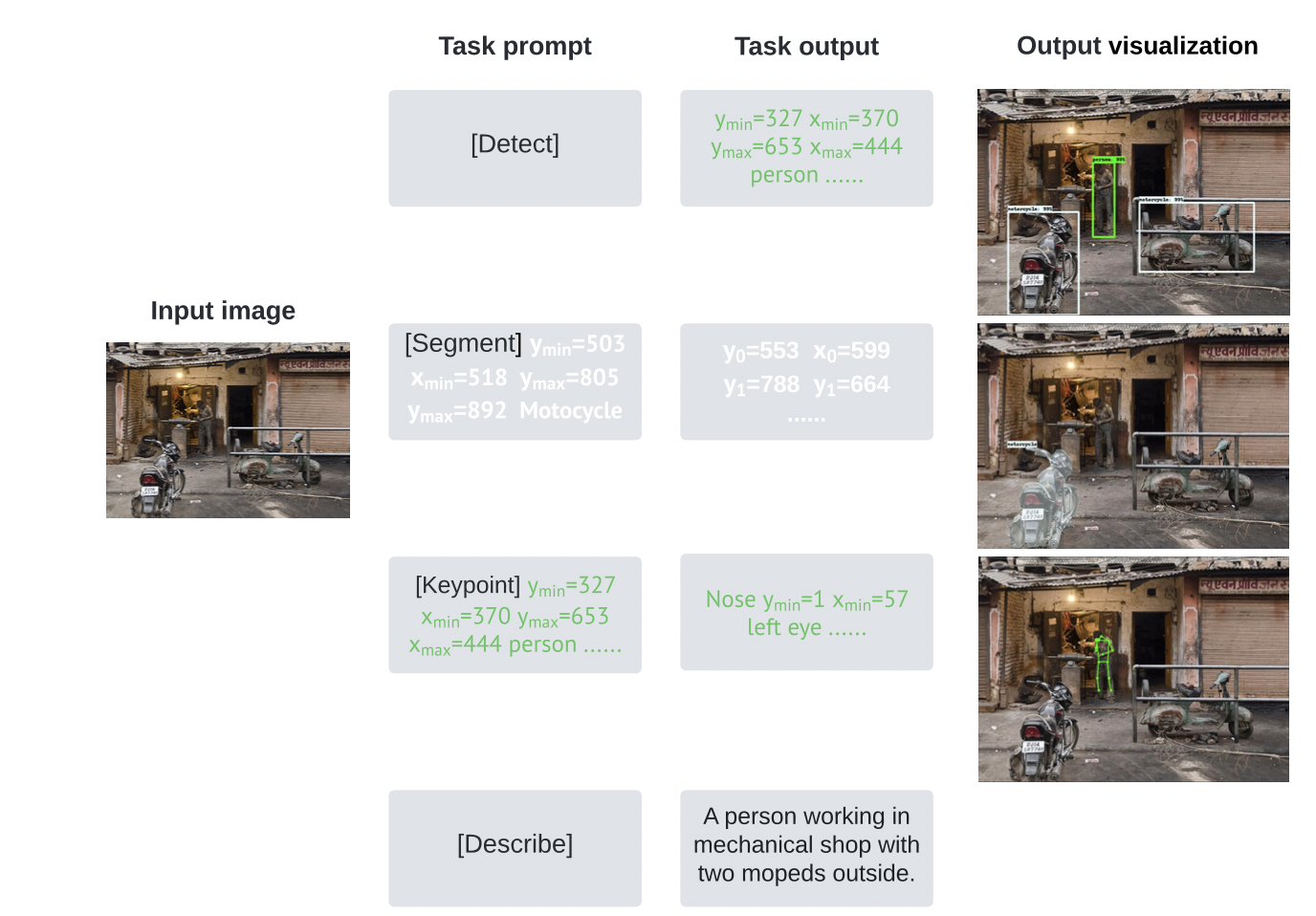
值得注意的是,所有四个任务都使用同一个词汇表。 具体的prompt和输出序列如上图所示
训练
每个任务都有自己的成对图像序列训练数据。有两种方法可以将任务结合起来进行联合训练。作者提出了data mixing和batch mixing两种数据混合方式。

data mixing在概念上简单,但是因为数据格式不同,图像增强很难合并比较麻烦,相比较而言,batch mixing对单个任务采样图像后进行相应增强后转换为图像-序列对,模型分别计算每个任务的损失和梯度。作者认为可以将特定任务的每一批数据的梯度以适当的形式加权组合起来。
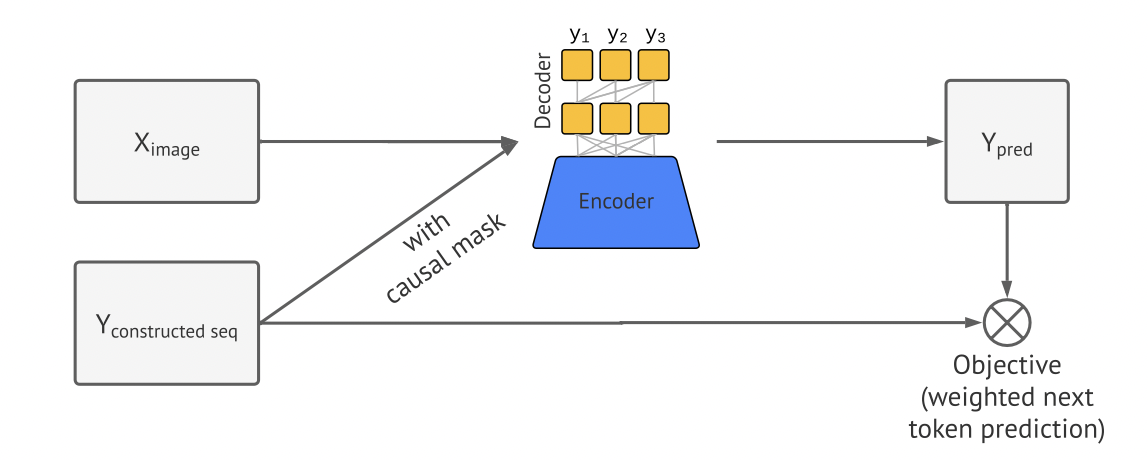
在损失函数上,与pix2seq一样,训练目标是最大化基于图像的token和之前的token的似然性。
其中,x表示输入图像,y是长度为L的编码序列(监督信号),序列y的初始部分是一个prompt,为此作者将权重wi设置为零,损失计算时不包括该部分。
实验结果
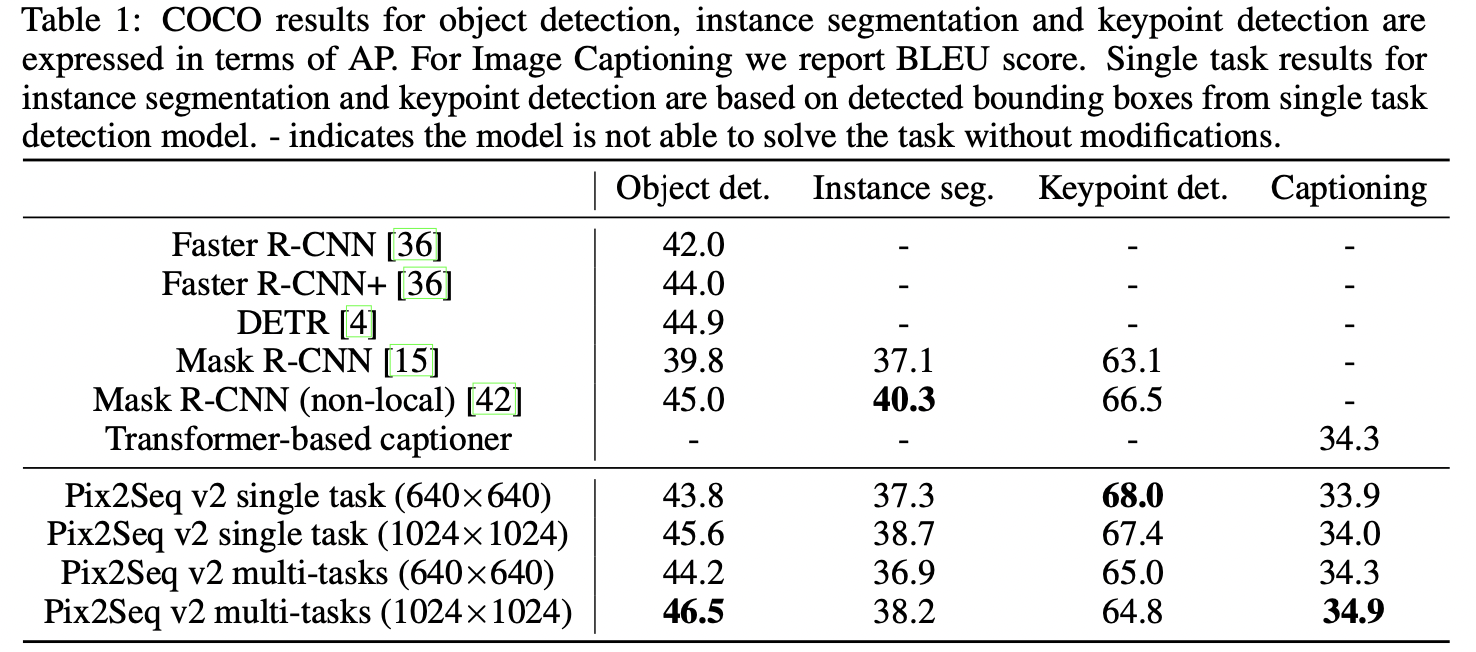
从上述表格可以看出,在模型结构和损失函数都没有针对特定任务进行设计的前提下,本文所提出的模型对于每个单独的任务仍然可以获得与专门定制化的baseline相比,依然具有一定的可比性(即使输入图像的尺寸更小)。