本文要介绍的是微软的俩篇有关VLP的工作,Oscar和METER,前者是发表在CVPR2020,后者是发表在CVPR2022。论文链接如下:Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks,An Empirical Study of Training End-to-End Vision-and-Language Transformers,下面大致介绍这俩篇工作的具体内容。
Oscar
这篇论文中提出了一种新的多模态预训练方法Oscar,把object用作视觉和语言语义层面上的Anchor Point,以简化图像和文本之间的语义对齐的学习任务,在多个下游任务上刷新了SOTA。
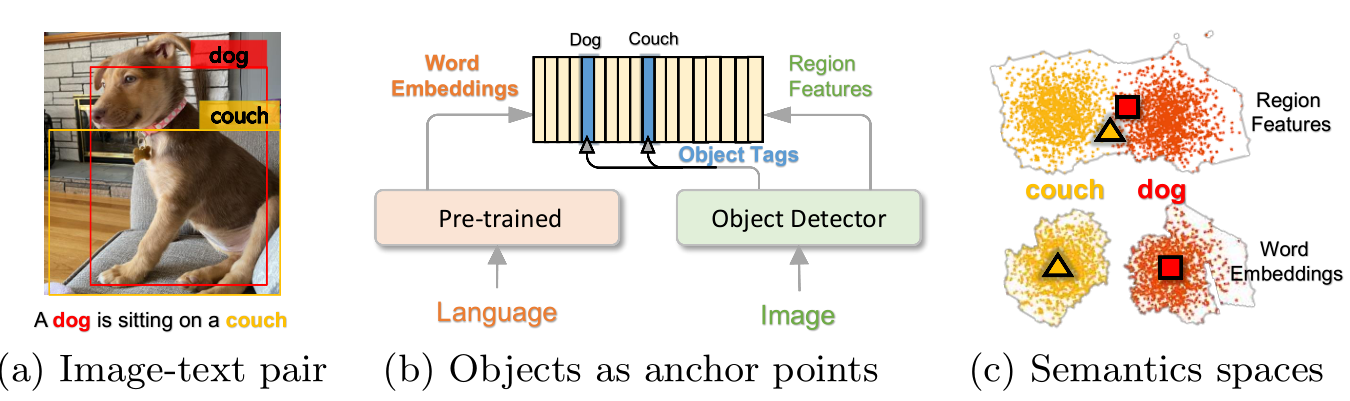
Motivation
在此之前,VLP方法都是简单粗暴地将图像区域特征和文本特征连接起来作为模型的输入以进行预训练,并不为模型提供任何线索,希望模型能利用Transformer的自我注意机制,使用蛮力来学习图像文本语义对齐方式。检测器在图像上检测的object通常会出现在对应caption text中,因此作者提出使用检测出来的物体标签对应caption中的词建立一个关联。
Pipeline
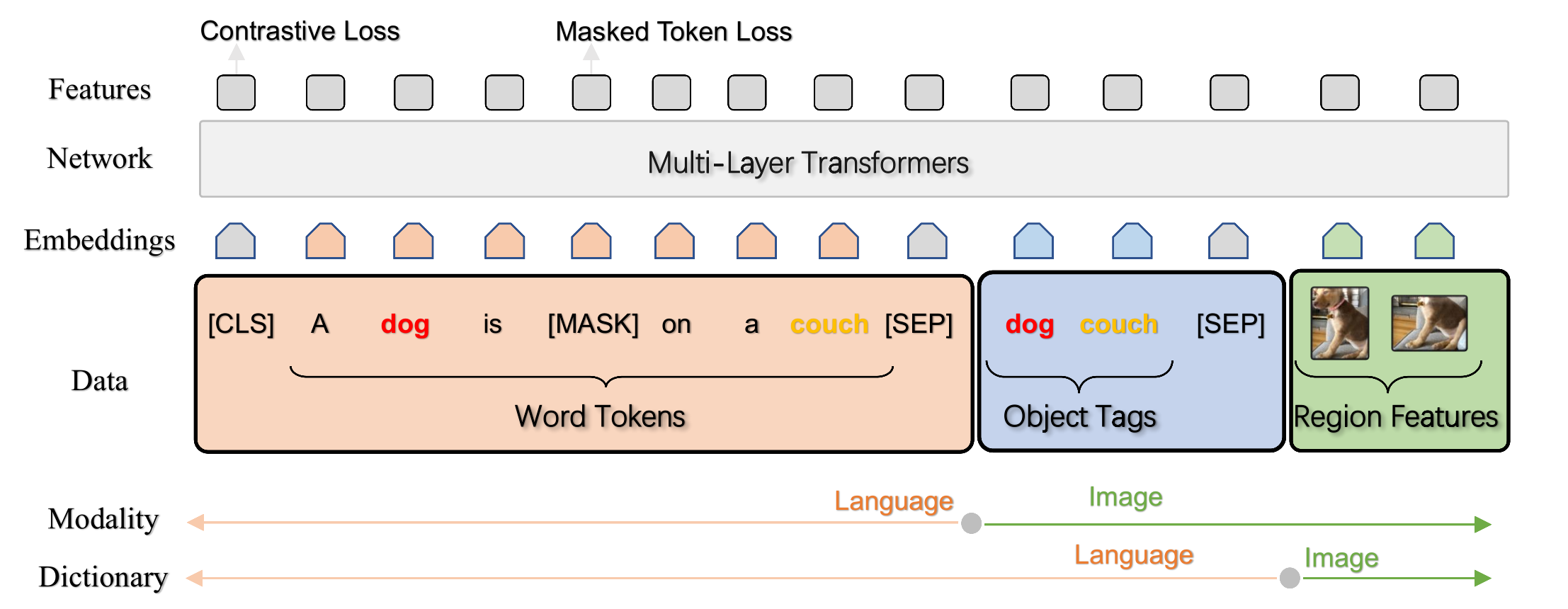
上图展示了OSCAR的pipeline,通过将对象标签作为anchor引入,Oscar在两个方面与现有的VLP不同:
- 输入表示:每个image-text样本定义为一个三元组(单词序列,物体标签,区域特征)。
- 目标函数:作者从两个不同的角度设计目标函数: modality视角(Contrastive Loss)和dictionary视角(Masked Token Loss)。
注意,在这里object tag输入的embedding是使用同一词表得到word embedding。
Experiments

Oscar在六项任务上均达到了SOTA。在大多数任务上,Osacr的base model要优于以前方法的large model,其表明Oscar具有很高的参数利用效率,这是因为object tag的使用大大简化了图像和文本之间语义对齐的学习。
在这之后,原班作者在Oscar基础上针对检测模型部分提出了VinVL,聚焦于提升检测模型提取视觉语义特征能力。
METER
这是微软在CVPR2022上的有关VLP的工作。本文提出了METER,一个end2end的VLP框架,并从visual encoder、text encoder、Multimodal Fusion、结构设计以及与预训练目标函数上对VLP做了详细实验分析。METER在VQAv2上取得sota结果。
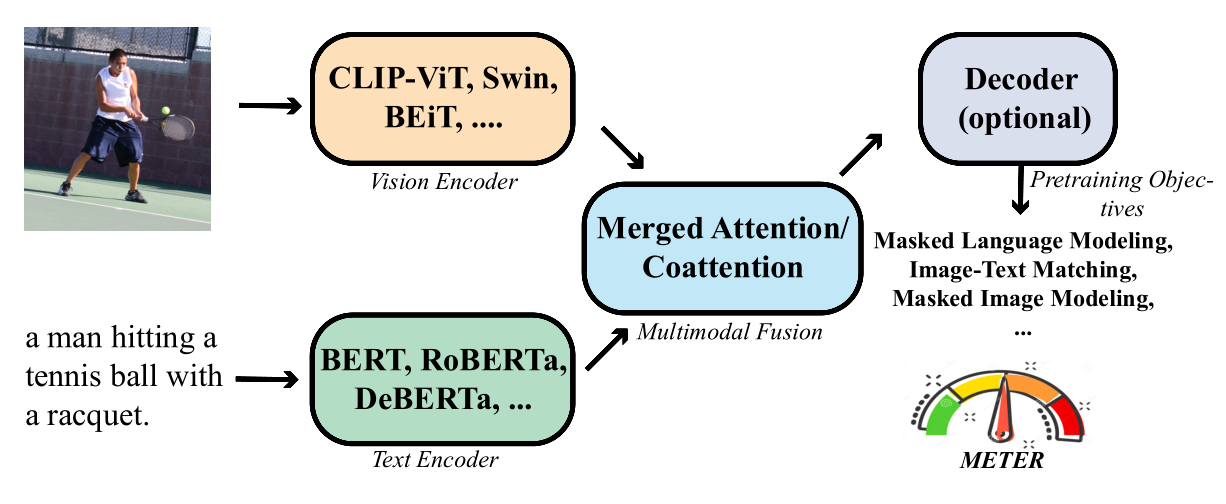
Glossary of VLP Models
以往基于OD(object detector)的VLP方法需要freeze object detector,限制了VLP模型能力,而且提取region特征时间代价较大。近期大多使用的ViT做visual encoder的VLP方法相比VinVL(OD)性能存在差距,为缩小差距本文提出METER,探索如何设计VLP模型。作者对现有VLP工作根据visual encoder、text encoder、Multimodal Fusion、Decoder以及预训练目标函数进行分类划分。

METER
总体结构:输入图片和文本对,图片经过visual encoder(CLIP-ViT,Swin,BEiT等)编码,文本经过text encoder(BERT,RoBERTa,DeBERTA等)编码,之后两者经过多模态融合模块(Merged Attention/Co-Attention)进行模态信息交互,最后经过一个可选的解码器输出结果。在论文中,作者对VLP模型各个模块都进行了分类和阐述,在实验部分进行了综合性分析并得到了每个部分最好的一个结构,从和产生METER最终结构。
Vsual Encoder: CLIP-ViT-224/16,Swin Transformer
Text Encoder:Roberta
Multimodal Fusion: Co-attention(如下图所示)
Pre-training Objectives:MLM(masked language modeling )+ITM(image-text matching)
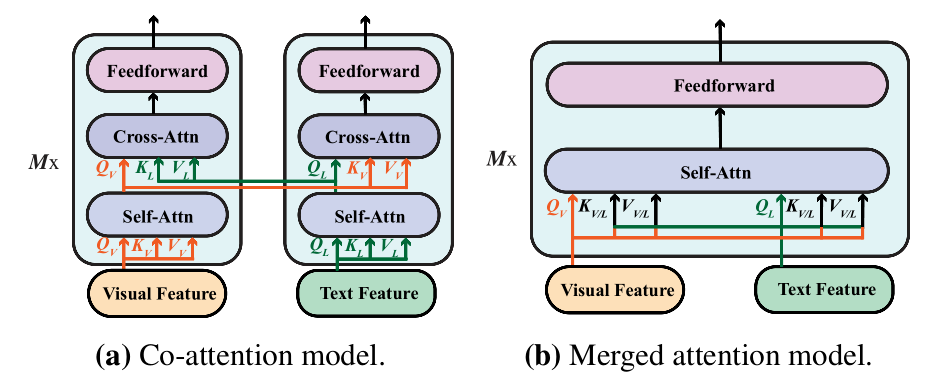
上图展示的是多模态融合模块的结构,在METER中,使用的是Co-Attention,Co-Attention中包含了堆叠的6层transformer layers,每层包含了一个self-attention,一个co-attention和一个前馈网络。没有decoder和编码器参数共享。
Experiments
在预训练数据方面,作者仅使用了COCO, Conceptual Captions, SBU Captions and Visual Genome,总共4M图片数据。在多个下游任务上进行验证,其中包括VQAv2,visual reasoning(NLVR2), visual entailment(SNLI-VE)和image-text retrieval(COO, Flickr30k)。作者实验做的非常详细,推荐去看原文。
Conclusion
(1)MERTER是Vision transformer + Text transformer结构
(2)在METER中Vision encoder用CLIP-ViT或者Swim transformer,Text encoder用Roberta,多模态融合用co-attention;
(3)在目标函数上,MLM+ITM都对VLP模型有帮助,但是MIM会带来负面影响;