论文信息:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
代码链接:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
整体信息:这是google research 发表在ICLR2022上有关CLIP在下游任务-目标检测任务上的应用。使用CLIP模型实现zero-shot场景下的目标检测任务。比较有想象意义的是,通过一句话就可以检测出图像中需要的指定目标。在之前CLIP图文多模态对比预训练方法详解中也有提及过这篇工作。
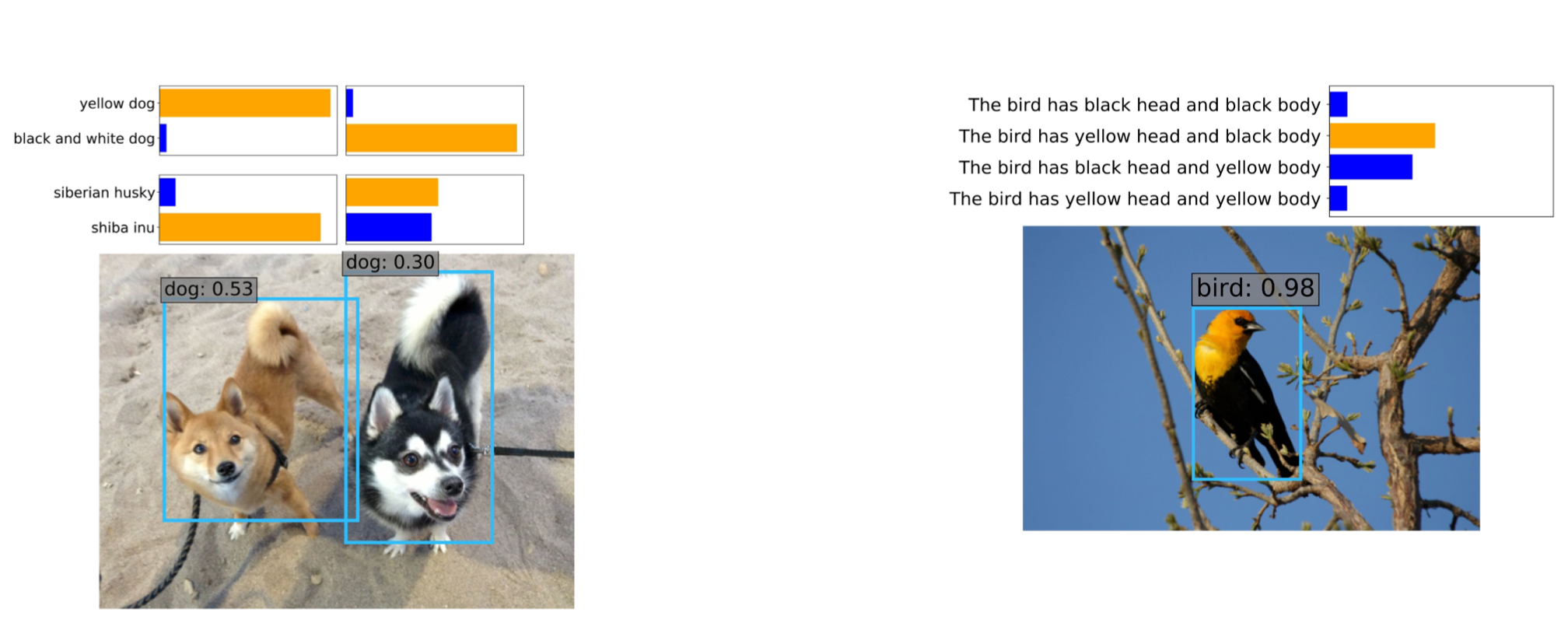
上图展示的是ViLD的检测结果。其中只有toy类别是训练过程中见到的类别,但zero-shot detection还检测到其他的属性,比如toy种类和颜色等。
zero-shot detection
顾名思义,这个任务就是,对于任意一个新类别,一张训练图像都不给的情况下,训练出来的检测器也能检测这个类别。zero-shot detection的setting通常是,将数据集依据类别划分为俩部分:base类别和novel类别,base类别用于训练,novel类别在训练过程中不可见。该任务的目标在于,在novel类别上获得较好性能的同时还需要保持base类别的性能;在这篇文章中使用的是LVIS数据集进行实验对比分析,将common和frequency俩类别作为base类,将rare类别作为novel类。
常规方法

如上图展示的是zero-shot detection with cropped regions,具体地,使用在二阶段检测方法比如Mask-RCNN获得proposal之后,对每个proposal都crop & resize 然后输入到CLIP-image-encoder中获得image-embedding,与对应类别的text-embedding进行对比,获取类别信息。该方法的的缺点是比较慢,需要one-by-one地处理每个object proposal,而且CLIP-text-encoder没有充分利用base类别的文本信息。
ViLD方法
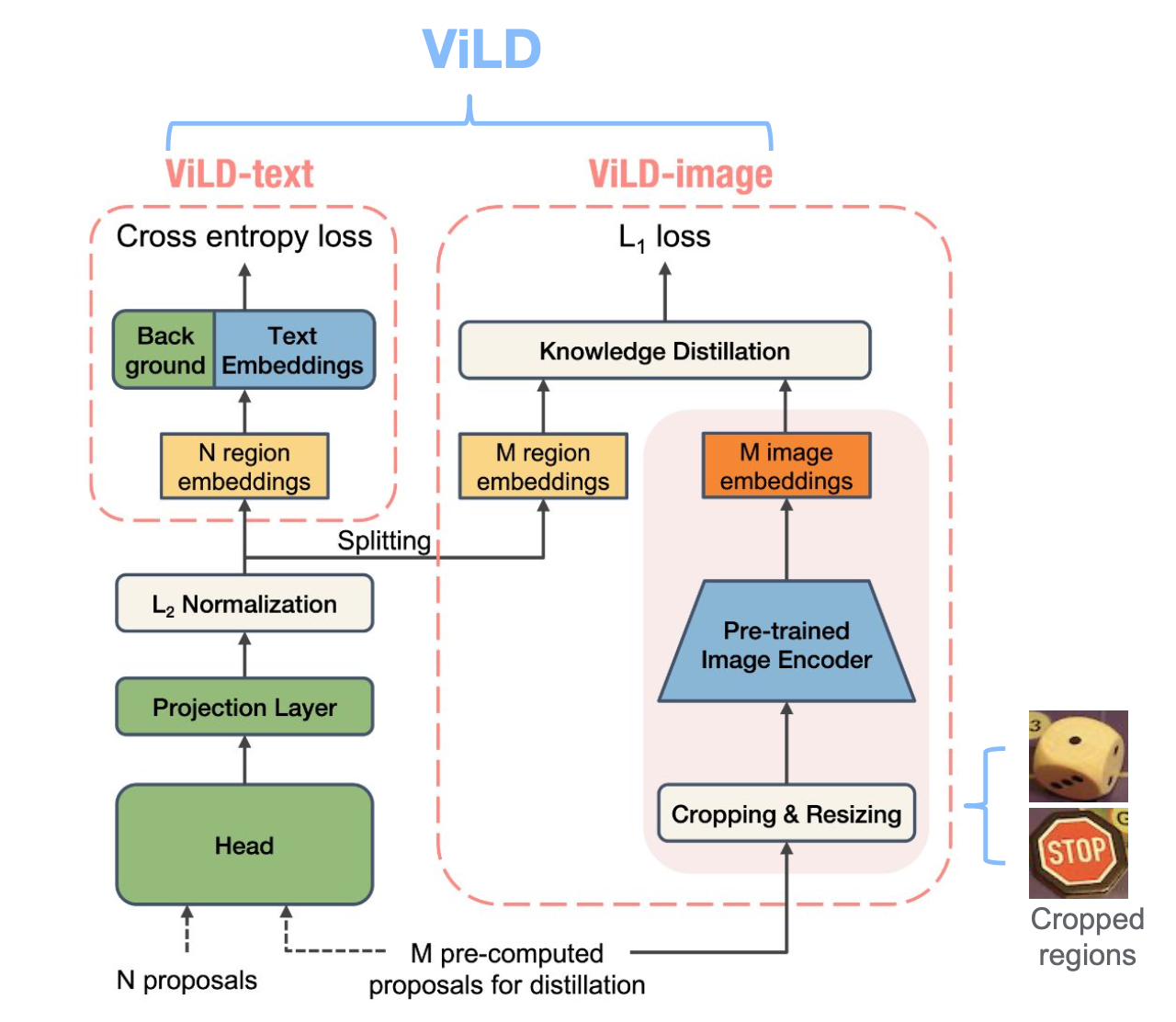
上图展示的是ViLD方法的pipeline。具体地,在ViLD中包含俩部分:ViLD-text用于学习文本embedding和ViLD-image用于学习图像embedding。在ViLD-text中,将base类别文本送入CLIP-text-encoder中获得text embedding,然后用于classify目标区域,在ViLD-image中会将对应的proposal送入CLIP-image-encoder中获得图像embedding,对经过roi align之后的region embedding 进行知识蒸馏;相比于ViLD-text,ViLD-image蒸馏了base+novel的信息,因为proposal网络输出的proposal可能会包含novel,而ViLD-text只使用了base类的文本信息;
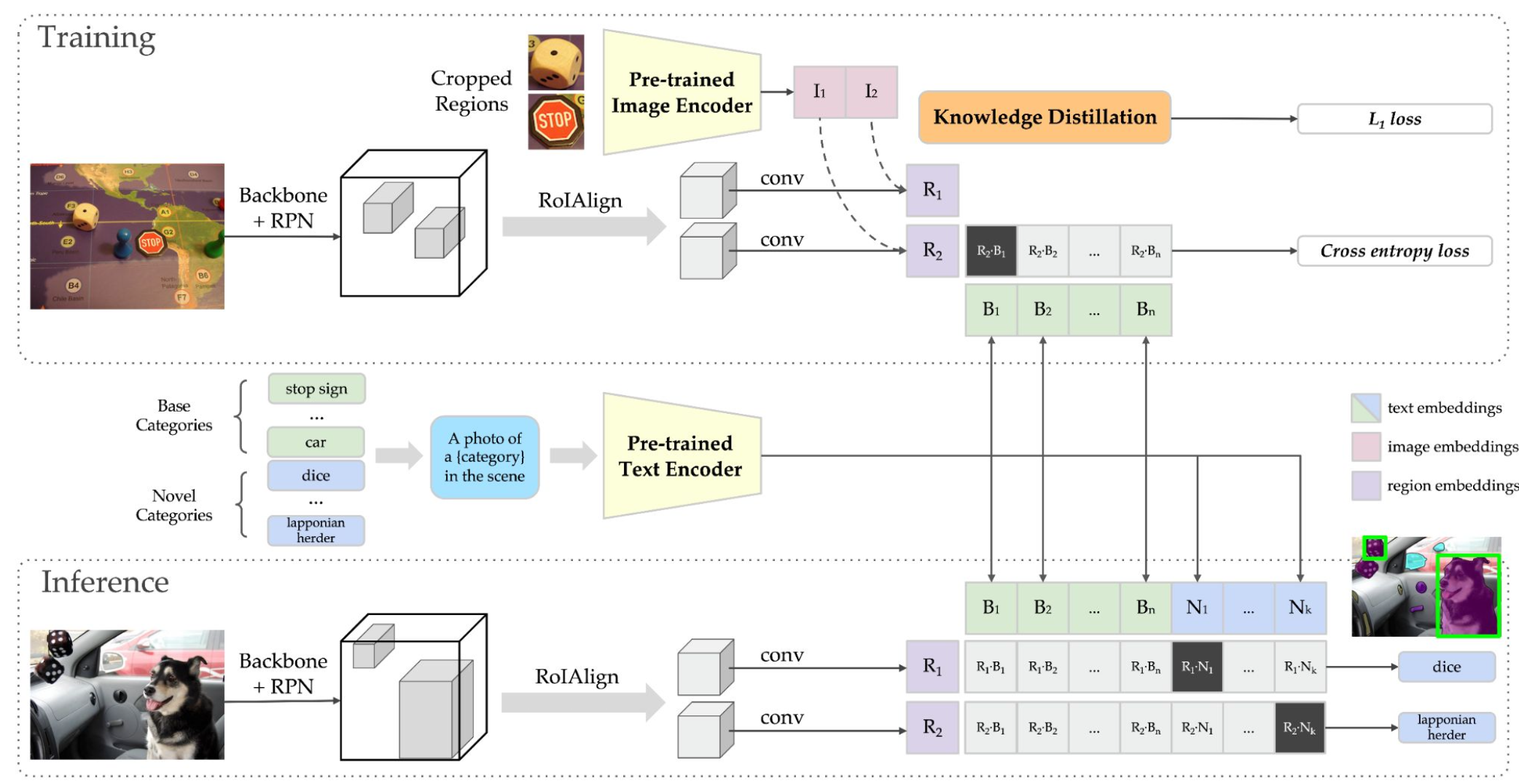
上图展示的是ViLD的训练和推理流程。相比于mask-rcnn,修改地是rcnn的分类分支;具体地,在训练过程中,在获取分类监督信号上包括俩部分:用CLIP获得image embedding蒸馏region embedding,以及用CLIP获得text embedding监督region embedding;总的损失如下公式所示:
在推理过程,只需要将region embedding和text embedding(base+novel)进行对比即可得到类别信息。
实验
数据集:实验使用的是LVIS v1.0(1203类别),其中frequent(f: 405个类别)和common(c: 461个类别)作为base类,其余rare(r: 337个类别)作为novel类。
目标proposal:由于训练过程中只使用了base类训练,下表展示的是仅使用base类训练时的RPN召回率和使用base+novel时的RPN召回率,从上可以看出二者相差1-2个点。因此可以看出RPN是具备从base类上泛化到novel。

Ablation:作者在paper中做了较为详尽的ablation study实验,这里只提及一些证明idea有效的关键实验分析。
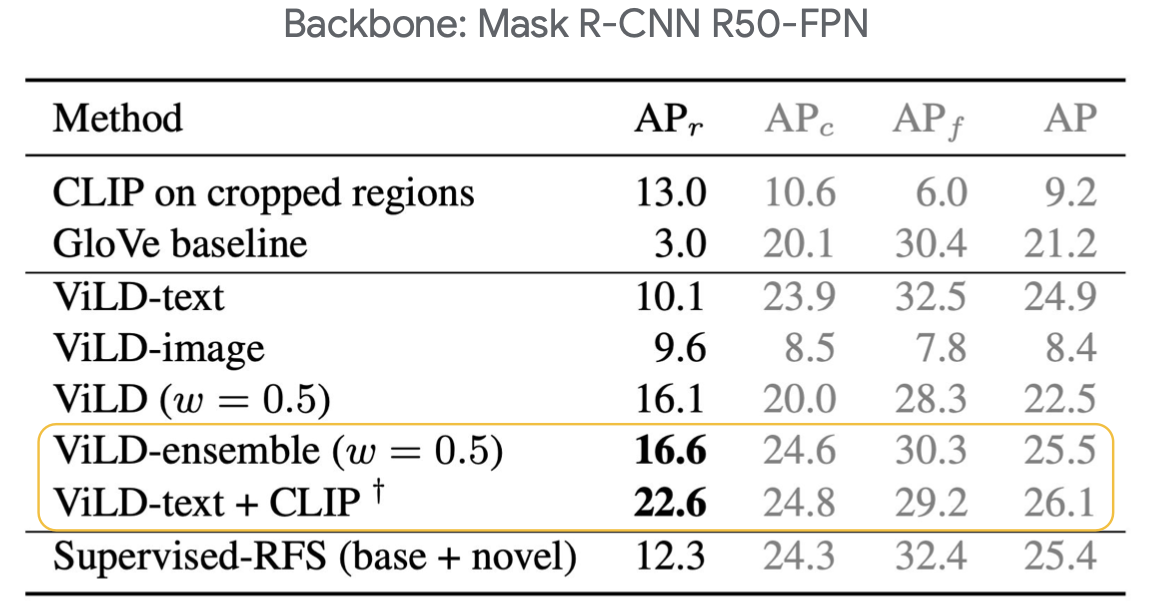
上表格中,CLIP on cropped regions就是前面介绍的常规方法,该方法在APr上可以达到13.0,ViLD-text和ViLD-image表示分别使用单一监督信号。ViLD(w=0.5)表示同时使用ViLD-text和ViLD-image监督训练。ViLD-text相比CLIP on cropped regions在APr上下降了3个点,说明使用base类信息监督ViLD-text在novel上的泛化性有所下降。ViLD(w=0.5)相比于ViLD-text和ViLD-image都提升幅度明显。ViLD-ensemble(w=0.5)表示同时使用ViLD-text和ViLD-image监督训练同时,在base预测上,倾向于ViLD-text,在novel预测上使用vice versa投票决定。可以看出ViLD-ensemble(w=0.5)方式在base类别上提升明显。
Transfer to other detection datasets:这个是证明在不同数据集之间的一个迁移有效性。只需要替换类别 text embedding,无需进行fine-tune。

在不进行任何fine-tune下,ViLD在COCO数据集上就可以取得36.6AP,与fine-tune条件下AP只相差不到3个点。
最后
作者也在离线交互式检测上也做过一些实验,输入文本信息,就可以检测出对应的目标。这个还挺有意思的,随意说一句话就能检测到图像的指定目标。