论文信息:Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
代码链接:https://github.com/Sense-GVT/DeCLIP
整体信息:这是商汤科技发表在ICLR2022上关于多模态预训练的工作,在前面的文章中介绍过CLIP,是一种基于对比文本-图像对的预训练方法,该方法需要在大量的图像-文本对数据集进行训练,在CLIP工作上就使用了4亿的图像-文本对数据,数百张卡进行预训练。为了提高训练效率,这篇工作提出了DeCLIP(Data Efficiency CLIP)方法,在较少数据下依旧可以取得不错的效果。
具体方法
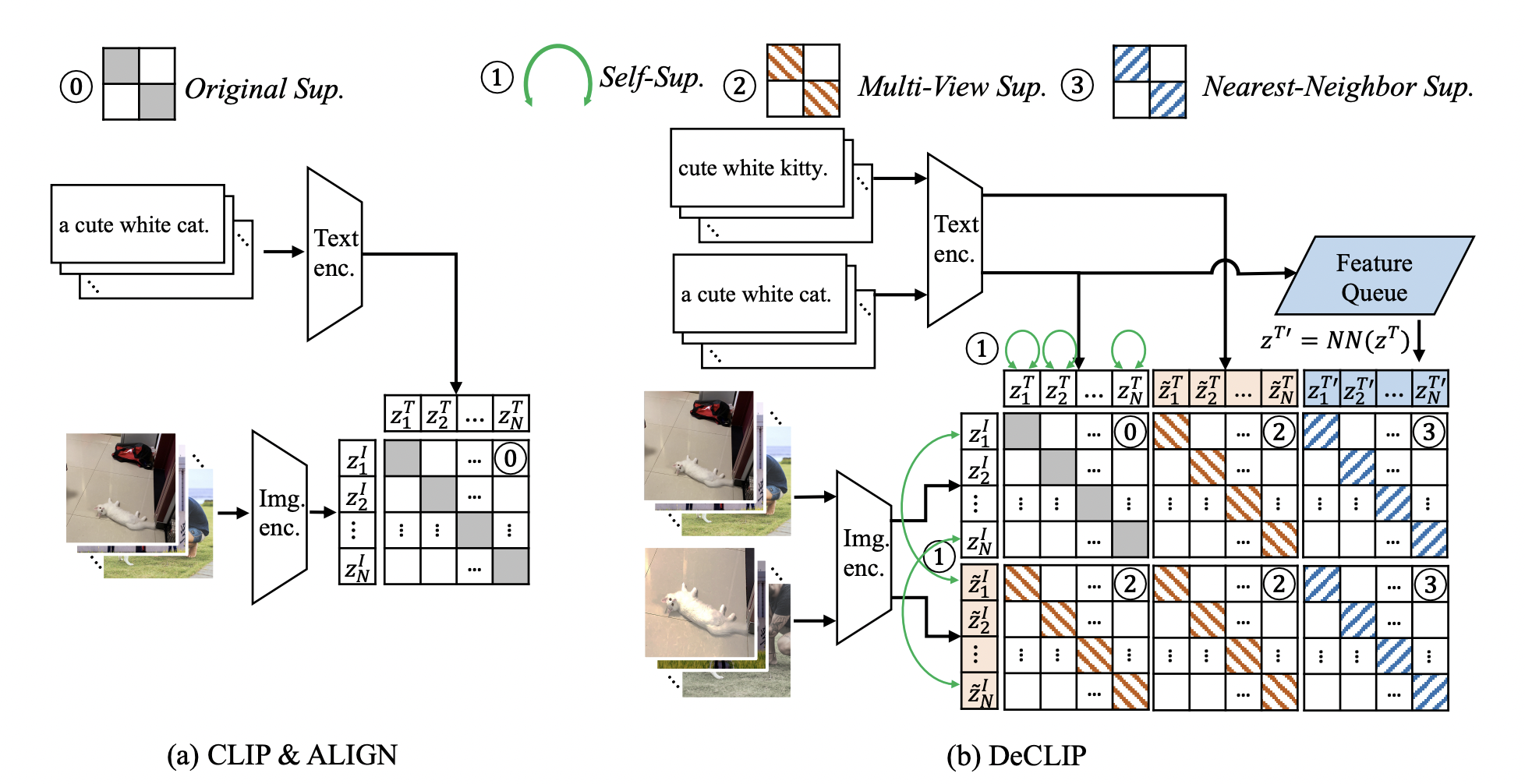
上图,直观地,展示的是CLIP和DeCLIP方法的差异。CLIP是直接学习原始图片与对应的文本信息,使用俩个encoder分别编码图像信息和文本信息。图像encoder一般是resnet或者ViT,文本encoder一般使用transformer。之后将俩个embedding映射到相同的空间中,使用对比学习的思想进行训练。从方法上看,其实只使用了图像-文本对匹配的一种监督信号进行训练。假设batch size是N,共计N个图像-文本对$\left{\left(x{i}^{I}, x{i}^{T}\right)\right}$,损失函数InfoNCE如下:
不同于CLIP,在DeCLIP方法中,使用了更多的自监督信号:1. 单模态的自监督学习;2. 跨模态的多视角监督学习;3. 最近邻监督学习;具体地,
单模态自监督学习(self-supervision within each modality, SS),包括使用SimSiam作为图像的自监督信号,和使用掩码语言模型MLM作为文本的自监督信号;
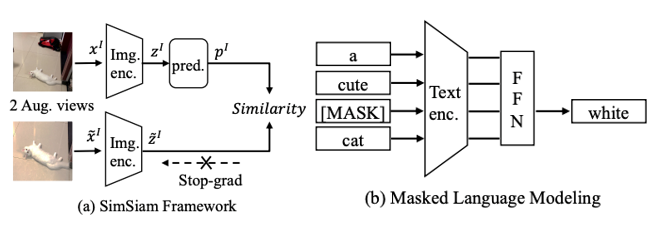
(a)图像自监督:同一张图片进过数据增强获得俩个view:$(x^{I}, \tilde{x}^{I})$,将经过数据增强后的结果经过相同的encoder得到俩个embedding向量$(z^{I}, \tilde{z}^{I})$,之后将其中一个embedding向量$x^{I}$再经过一个perd层得到向量$p^{I}$,训练时让$p^{I}$和$\tilde{x}^{I}$ 尽量接近;
(b)文本自监督:文本自监督使用的是MLM方法,即随机mask掉文本中15%的token,然后利用前后token预测被mask掉的token;
跨模态多视角监督学习(Multi-View Supervision, MVS):CLIP只使用的原始图像-文本对$\left(z^{I}, z^{T}\right)$,计算infoNCE损失,而DeCLIP中使用的是增强后的文本和图像计算infoNCE损失:$\left(z^{I}, z^{T}\right), \quad\left(\tilde{z}^{I}, z^{T}\right),\left(z^{I}, \tilde{z}^{T}\right), \quad\left(\tilde{z}^{I}, \tilde{z}^{T}\right)$ ,相比CLIP多了3个监督信息;
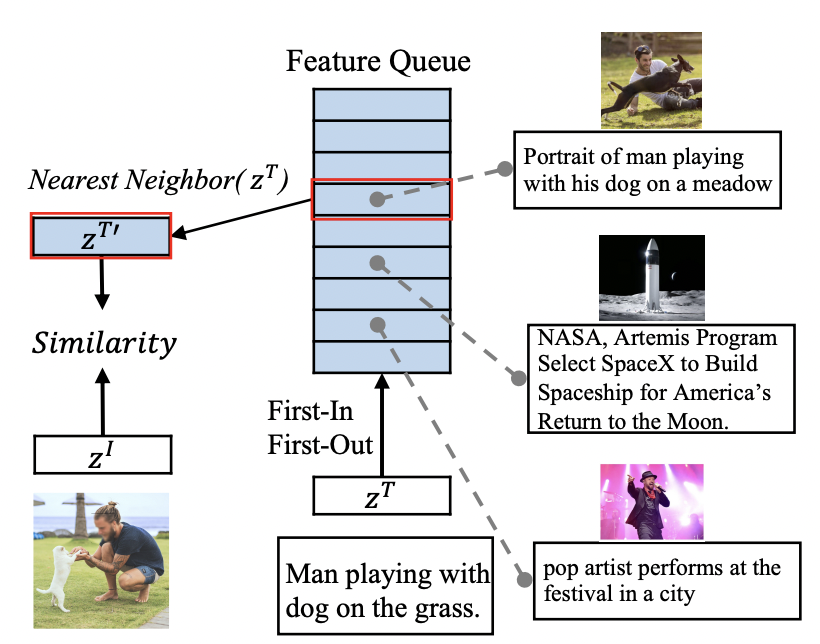
最近邻监督学习(Nearest-Neighbor Supervision, NNS):考虑到相同的图像可能会有类似的语言描述,因此选择语言描述相似的图文进行对比学习,通过维护一个先入先出的队列来模拟整个数据的分布,从队列中选择最相似的句子作为正样本$z^{T^{\prime}}$,之后使用InfoNCE计算最近邻损失:$\left(z^{I}, z^{T^{\prime}}\right),\left(\tilde{z}^{I}, z^{T^{\prime}}\right)$;
在损失函数层面上,对以上三种不同监督的损失进行加权求和,得到最终的loss,具体地,如下所示:
数据集
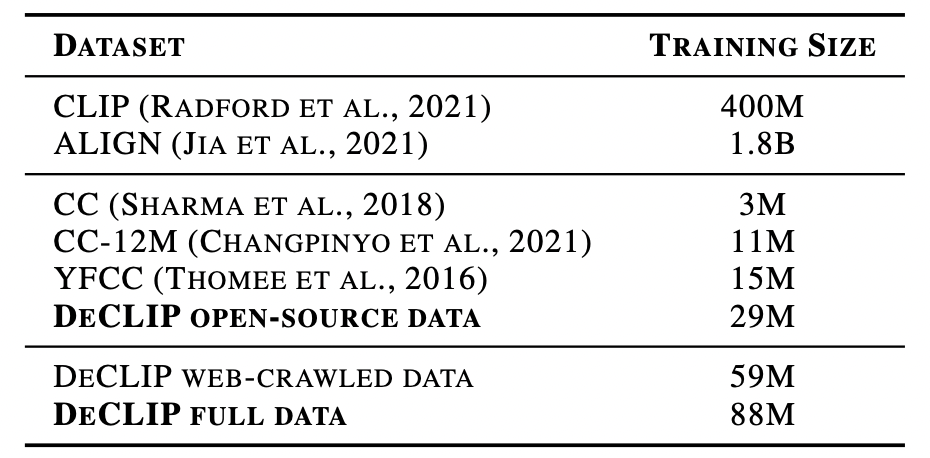
在DeCLIP中,数据集包含俩部分:开源数据集29M和网络下载的数据集59M,总共88M训练数据,相比于CLIP使用的400M数据少很多。
实验
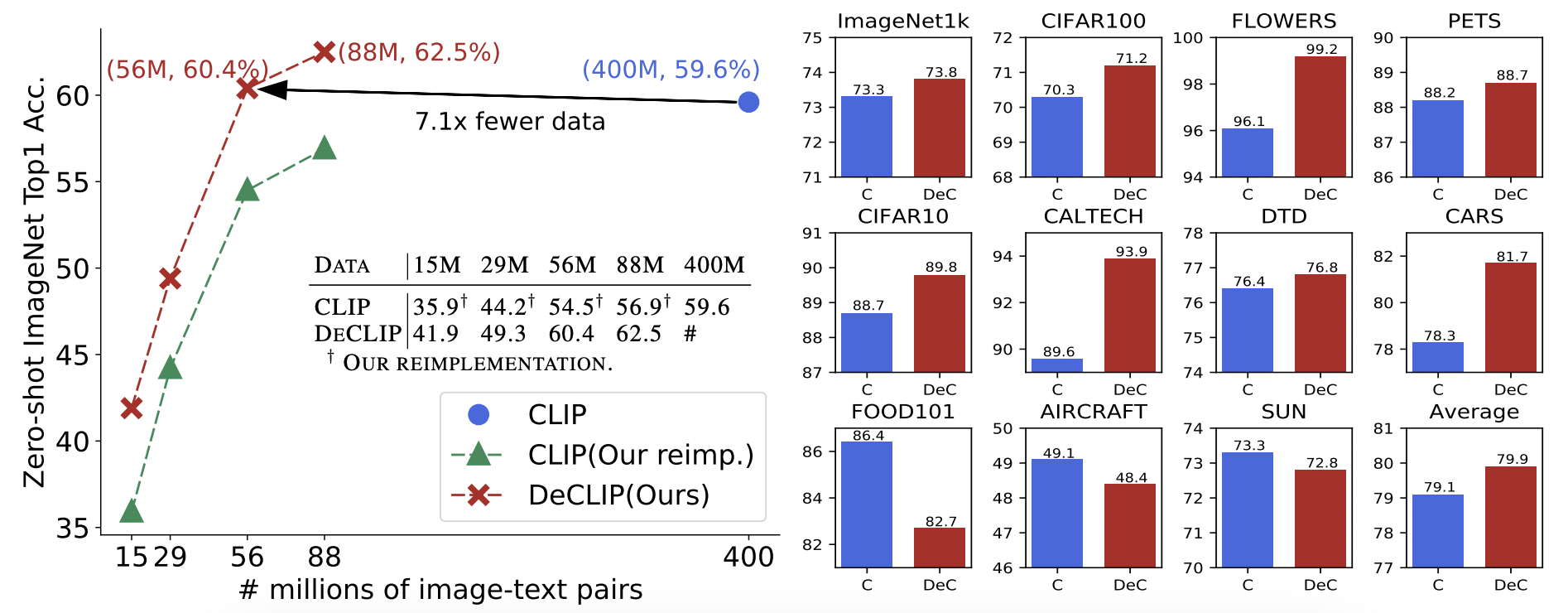
Zero-shot准确率;
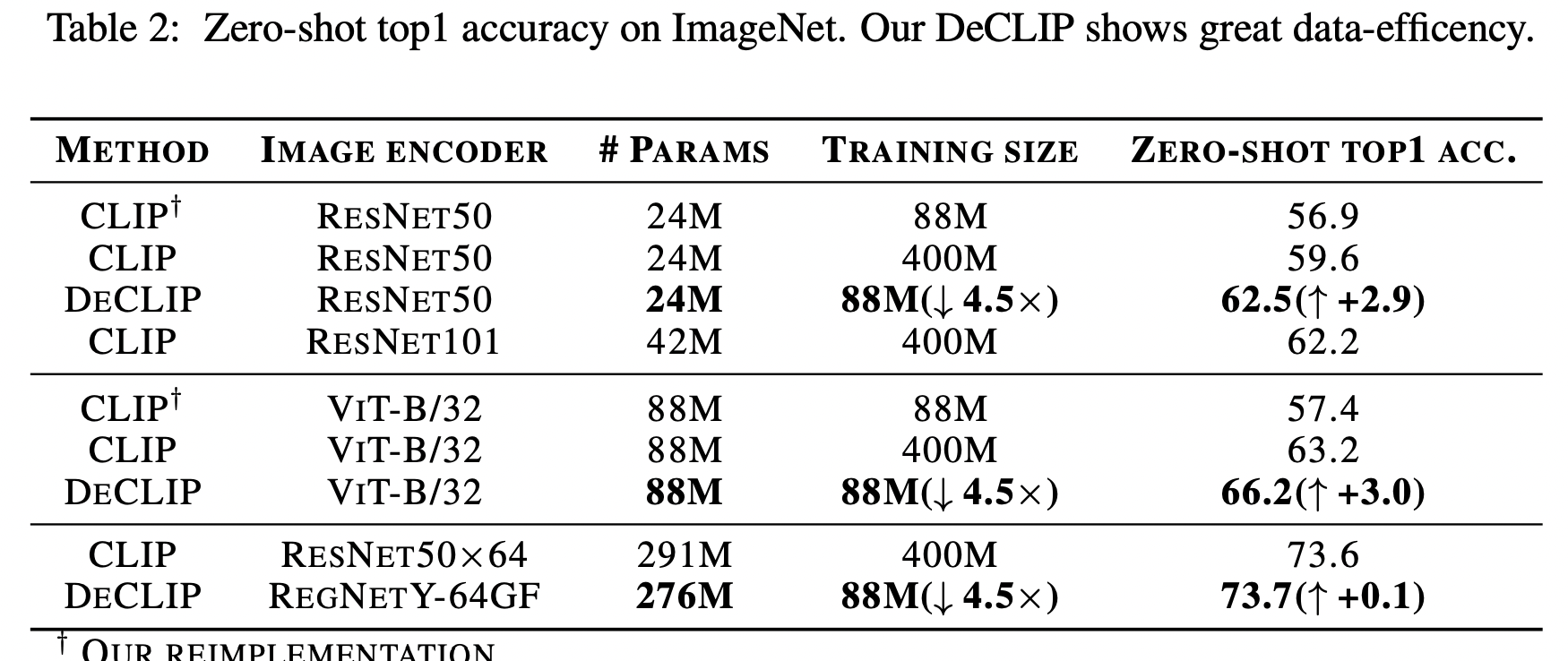
相比于CLIP,使用更少的训练数据,得到了更高的准确率;
下游任务表现;
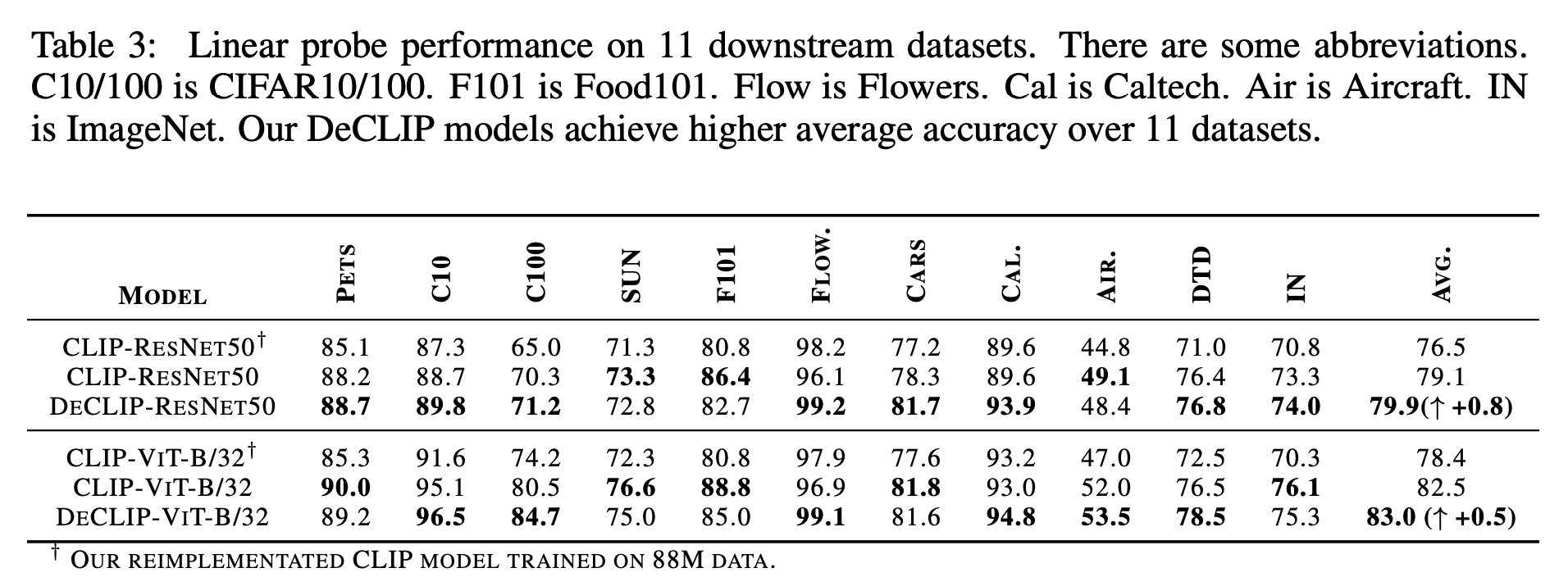
在resnet和ViT俩种不同的encoder上,都证明了DeCLIP学习到的特征表示相比CLIP要强;
Ablation study
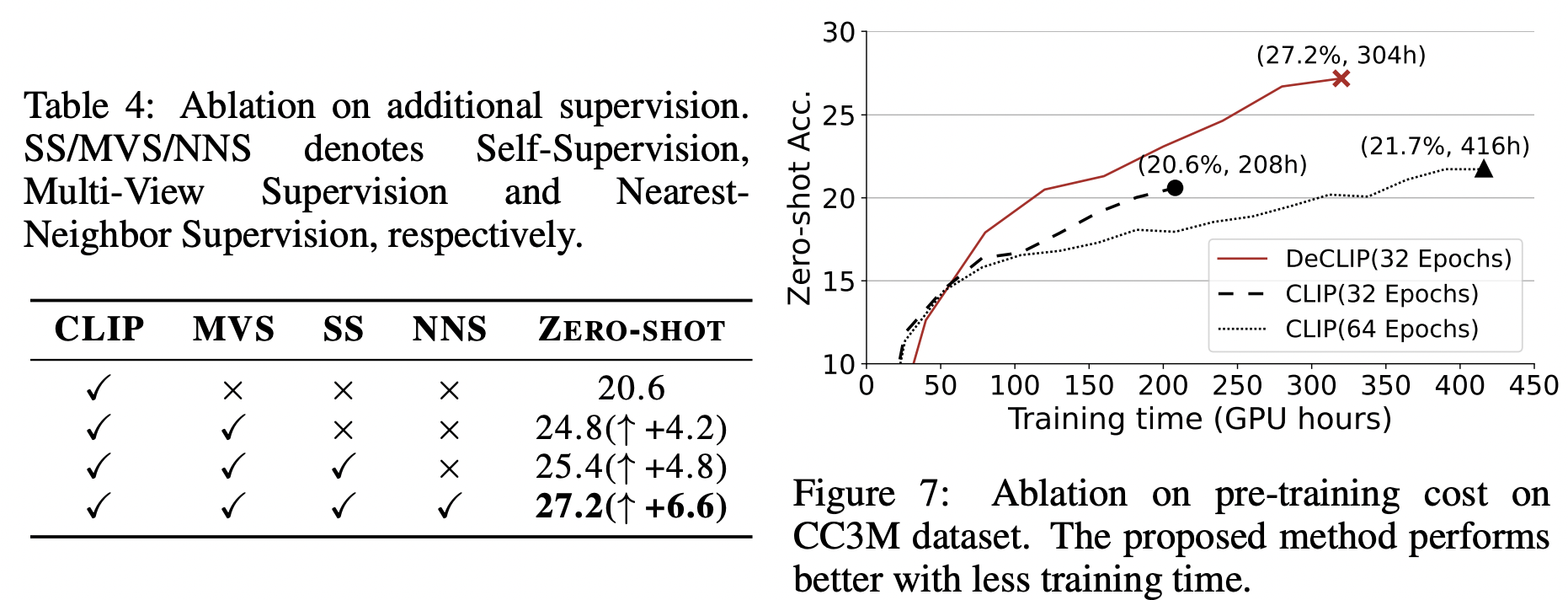
如上图证明了使用多种监督信息可有效的提升zero-shot准确率,而且相比于CLIP,DeCLIP的训练效率更高;
最后
作者还在DeCLIP的基础上提出了CLIP-benchmark,其中包含了高质量的YFCC15M-V2数据集,而且复现了CLIP系列的相关方法(CLIP,DeCLIP,FILIP,DeCLIP,DeFILIP)。目前代码均已开源在这里。