近年来,在NLP领域热度最高的技术莫过于prompt engineering ,想了解一个方向最快速的方法就是看有关这个方向的survey的paper。本文的内容主要参考CMU刘鹏飞的这篇论文:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing。这篇survey对于比较清晰的介绍了当前NLP中的范式发展,以及prompt的一些基础知识和prompt的设计方法。
NLP的范式发展
这篇论文总结总结了在NLP中的四次”范式“的“革命”:
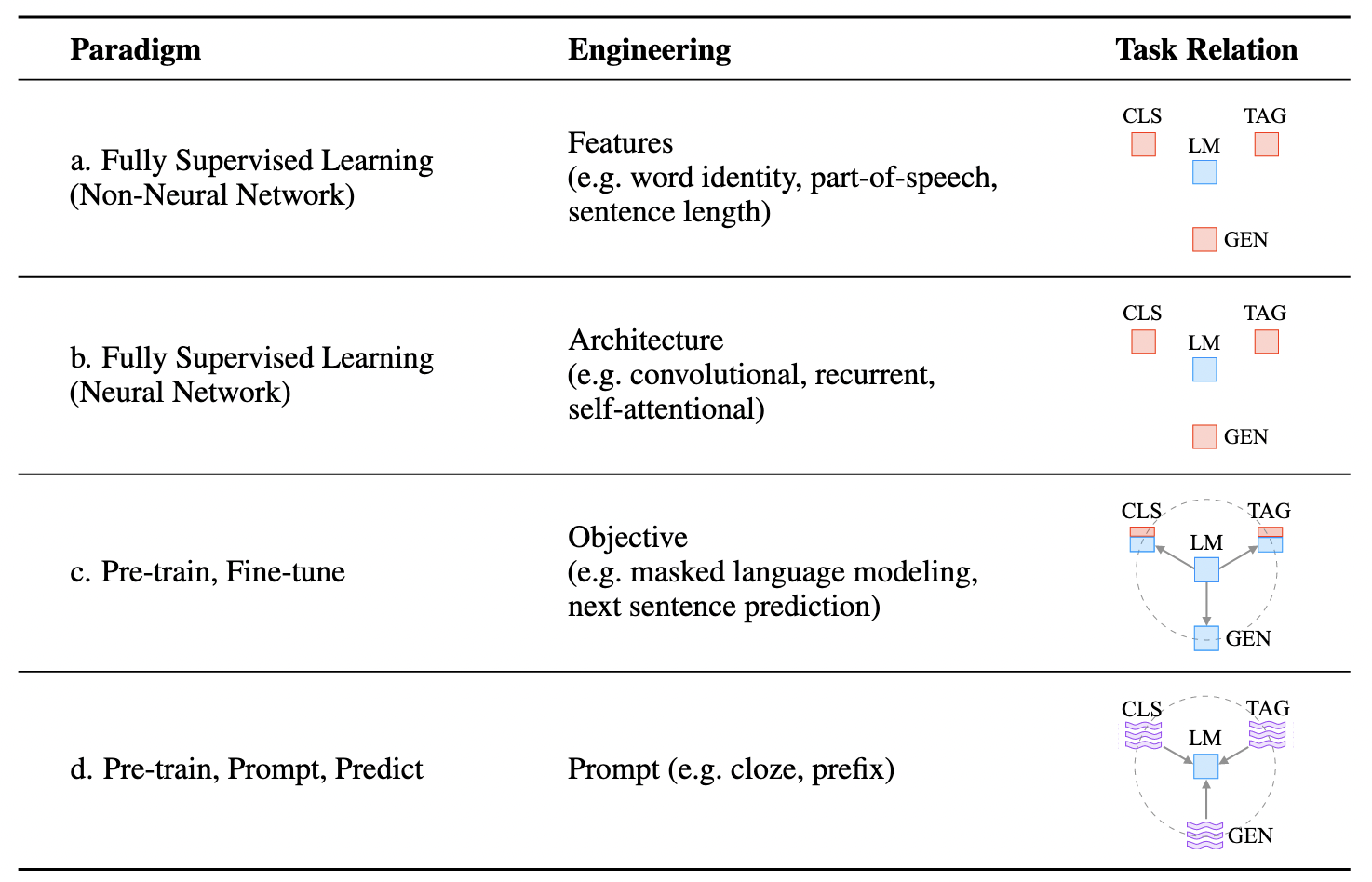
- 第一个范式:feature engineering,从原始数据中提取显著特征,并提供具有适当归纳偏差的模型,以便从这个有限的数据中学习;
- 第二个范式:architecture engineering,通过设计有利于学习这些特征的合适网络架构来提供归纳偏差
- 第三个范式:objective engineering,在大量的原始文本数据上对大模型进行pretrain学习通用特征,然后在下游任务上进行fine-tune,在这个范式中重点在于设计合适的pretrain和fine-tune的objective function;
- 第四个范式:prompt engineering,随着PLM体量不断增大,对其进行fine-tune对硬件、数据、耗时代价要求也在不断上涨。而prompt就是一个更小巧轻量、更普适高效的方法;
prompt是什么
prompt 说简单也简单,其实就是构建一个语言模版。融入了prompt的新模式大致可以归纳成”pre-train, prompt, and predict“。在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 “I love this movie.” 这句输入,可以在后面加上prompt “The movie is _“ 这样的形式,然后让PLM用表示情感的答案填空如 “great”、”fantastic” 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
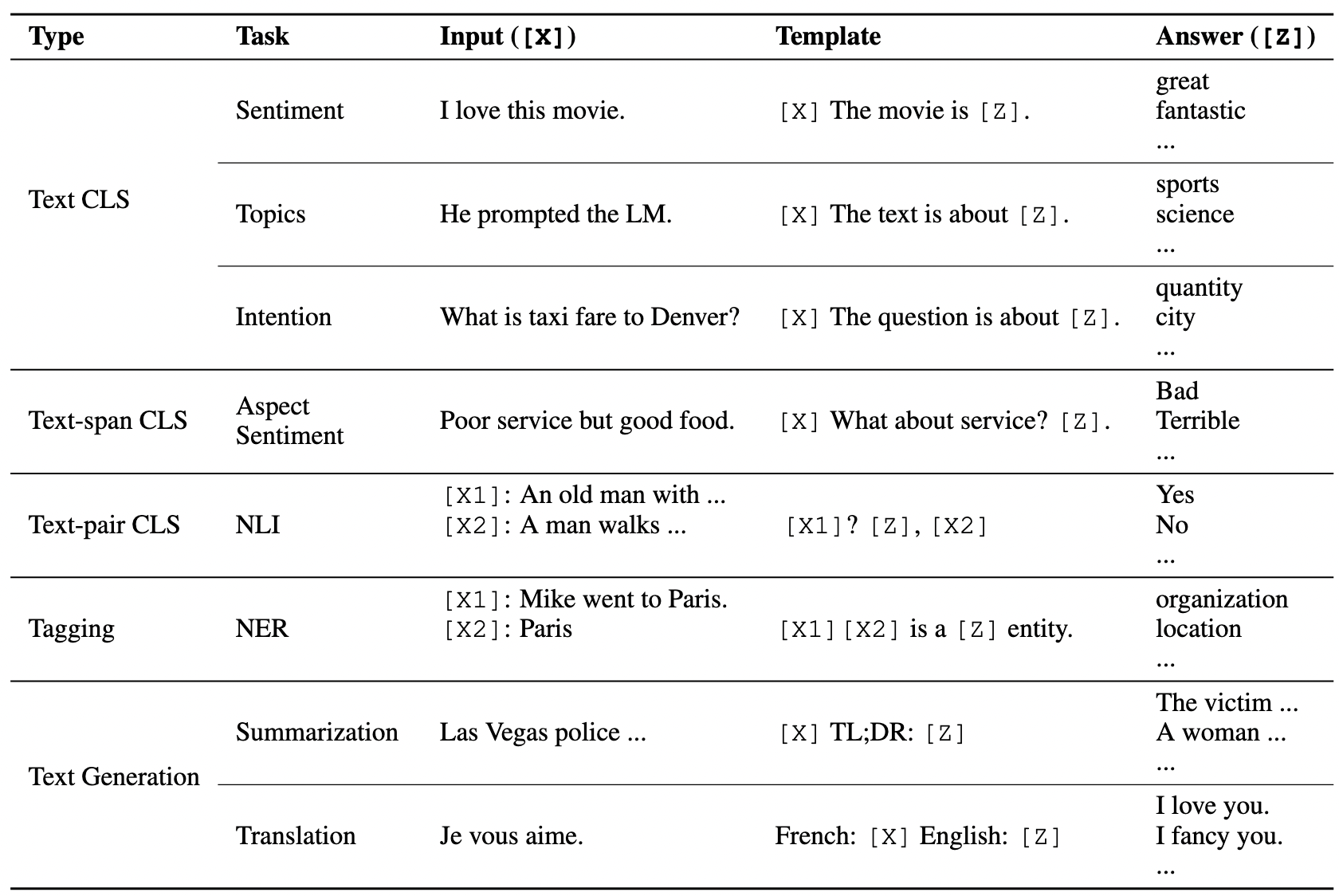
下表格是人工设计的prompt模板,其中[x]和[y]可以看作是数据和标签。可以看到,prompt的微小差别,其性能差异可大到20-30点,合适的prompt对于模型的效果至关重要。

prompt数学描述
对于传统有监督学习任务而言,我们的目标是对x/y进行建模,得到模型$P(y|x,\theta)$,x/y为对应的数据和标签,然而在现实世界中构建大量人工标注的x/y数据,往往费时费力,而且质量也无法保证。而基于prompt的方法则是通过试图学习LM来规避这个问题。LM可表示为$P(X|,\theta)$,是对文本x的直接建模,通过它来直接预测/生成y。这在一定程度上对$P(y|x,\theta)$的直接建模进行了”解耦“,这样也就不再依赖人工标注数据x/y了。对于输入文本$x$,有函数$f_{prompt}(x)$ 将$x$转化为prompt形式$x^{’}$ ,
该函数通常会进行两步操作:
- 使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入x的位置[X]和用于生成答案文本z的位置[Z].
- 把输入x填到[X]的位置。
还用前文提到的例子。在文本情感分类的任务中,假设输入是
1 | x = " I love this movie." |
使用的模板是
1 | " [X] Overall, it was a [Z] movie." |
那么得到的x′就应该是 “I love this movie. Overall it was a [Z] movie.”
在实际的研究中,prompts应该有空位置来填充答案,这个位置一般在句中或者句末。如果在句中,一般称这种prompt为cloze prompt;如果在句末,一般称这种prompt为prefix prompt。[X]和[Z]的位置以及数量都可能对结果造成影响,因此可以根据需要灵活调整。上面讲的都是简单的情感分类任务的 Prompt 设计,读者看到这里自然而然的会想到,其他 NLP 任务的 Prompt 如何设计呢?实际上刘鹏飞大神在他的论文中给我们提供了一些参考
prompt设计
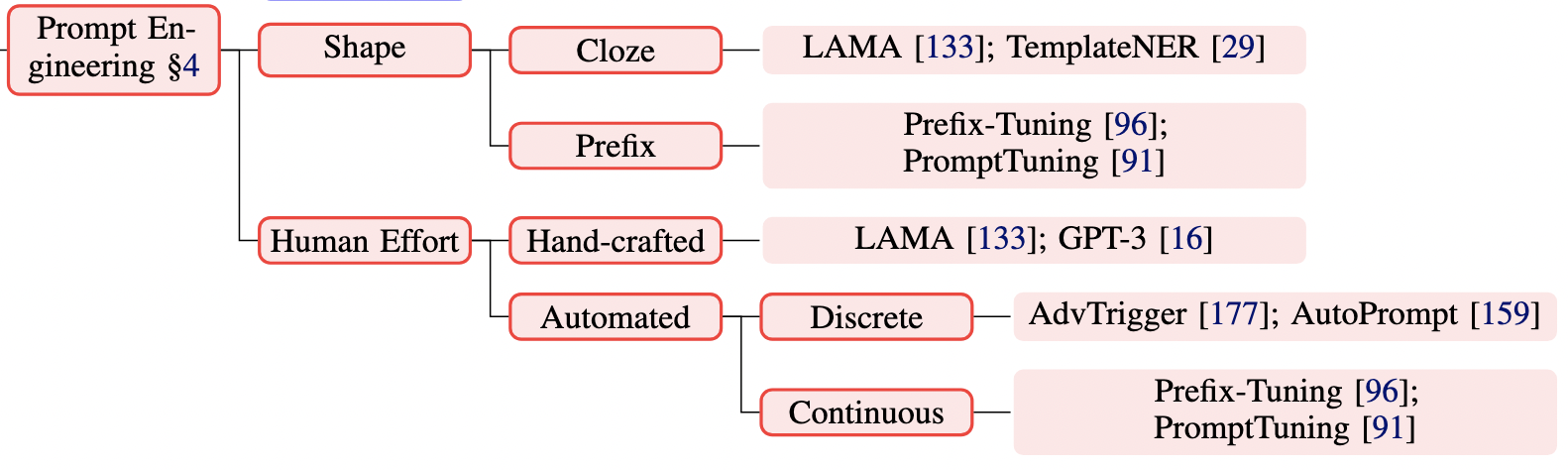
如上图所示,prompt主要从俩方面进行设计:形状以及手工/自动设计。
prompt shape
prompt的形状主要有两种:cloze prompt,与 Maksed Language Model 的训练方式非常类似,因此对于 MLM 任务来说,Cloze Prompt 更合适;对于生成任务或者使用自回归 LM 解决的任务,Prefix Prompt 更合适;
Hand-crafted
Prompt 的模板最开始是人工设计的,人工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的「模板」。人工设计模板的优点是直观,但缺点是需要很多实验、经验以及语言专业知识。下图是 GPT Understands, Too 论文中的一个实验结果。
Automated
为了解决人工设计模板的缺点,许多研究员开始探究如何自动学习到合适的模板。自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散的prompt是使用具体的words/tokens,而连续的prompt则是基于embeddings来表示prompts。这里主要介绍一下连续的prompt。连续型prompts去掉了两个约束条件:
- relax the constraint that the embeddings of template words be the embeddings of natural language words;
- Remove the restriction that the template is parameterized by the pre-trained LM’s parameters;
连续prompts好处是模板中的embedding可以是整个词表的embedding,而不再是有限的一些embedding,此外,模板的参数也不再是直接取PLM的参数,而是由独立的参数,可通过下游任务的数据训练进行调整。目前的连续prompts方法大致可以分为下面几种:
Prefix Tuning
prefix tuning 最开始由 Li 在Prefix-Tuning: Optimizing Continuous Prompts for Generation 这篇论文中提出来的,是一种在输入句子前添加一组连续型向量的方法,该方法保持 PLM 的参数不动,仅训练前缀(Prefix)向量。它的形式化定义是,在给定一个可训练的前缀矩阵$M_{\phi}$和一个固定的参数化为$\theta$的PLM的对数似然目标上进行优化,
也是属于一种PEFT方法,我会在下一篇博客中详细介绍这个方法。
Tuning Initialized with Discrete Prompts
这类方法中连续prompts是用已有的prompts初始化的,已有的prompts可以是手工设计的,也可以是之前搜索发现的离散prompts。Zhong 等人先用一个离散prompt搜索方法定义了一个模板,然后基于该模板初始化虚拟的token,最后微调这些token的embedding以提高准确率。
Hard-Soft Prompt Hybrid Tuning
这类方法可以说是手工设计和自动学习的结合,它通常不单纯使用可学习的prompt模板,而是在手工设计的模板中插入一些可学习的embedding。
最后
本文只是简单地介绍了一下prompt原理,详细可看原文。此外,如何使用prompt预训练大模型可以参考b站上这个视频,讲解地比较通俗易懂,【2022-陈蕴侬-如何prompt预训练大模型】 https://www.bilibili.com/video/BV1sh41137Xd/?share_source=copy_web&vd_source=b031a2a5b0a629cd338ab1f2c16ed732