和上一篇文章一样,本文依旧是介绍参数高效微调(Parameter-Efficient Fine-Tuning,PEFT) 方法:LoRA: Low-Rank Adaptation of Large Language Models,这篇论文是发表在ICLR2022上一篇论文,微软的工作,用于解决大模型finetune的问题。下面详细介绍LoRA工作原理。
LoRA
title:LoRA: Low-Rank Adaptation of Large Language Models
author:Edward J. Hu, Yelong Shen, Phillip Wallis
现有的解决大模型finetune的方法有很多,比如部分fine-tune、adapter以及prompting等。但这些方法大多存在如下问题:
- Adapter 引入额外的inference latency(增加了层数);
- prefix-tuning比较难于训练;
- 模型性能不如全参数fine-tuning;
Adapter Layers Introduce Inference Latency
显然,增加模型层数会增加inference的时长:
While one can reduce the overall latency by pruning layers or exploiting multi-task settings , there is no direct ways to bypass the extra compute in adapter layers;

从上图可以看出,对于线上batch size为1,sequence length比较短的情况,inference latency的变化比例会更明显。
Directly Optimizing the Prompt is Hard
与Prefix-Tuning的难于训练相比,LoRA则更容易训练:
We observe that prefix tuning is difficult to optimize and that its performance changes non-monotonically in trainable parameters, confirming similar observations in the original paper
模型性能不如Full fine-tuning
预留一些sequence做adaption会让处理下游任务的可用sequence长度变少,一定程度上会影响模型性能:
More fundamentally, reserving a part of the sequence length for adaptation necessarily reduces the sequence length available to process a downstream task, which we suspect makes tuning the prompt less performant compared to other methods.
LoRA
先来看下LoRA的motivation:
A neural network contains many dense layers which perform matrix multiplication. The weight matrices in these layers typically have full-rank. When adapting to a specific task, the pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace.
虽然,预训练的大模型有着较多参数,但是应用于下游任务时,其实模型主要依赖low intrinsic dimension,那adaption应该也依赖于此,所以提出了Low-Rank Adaptation (LoRA)。
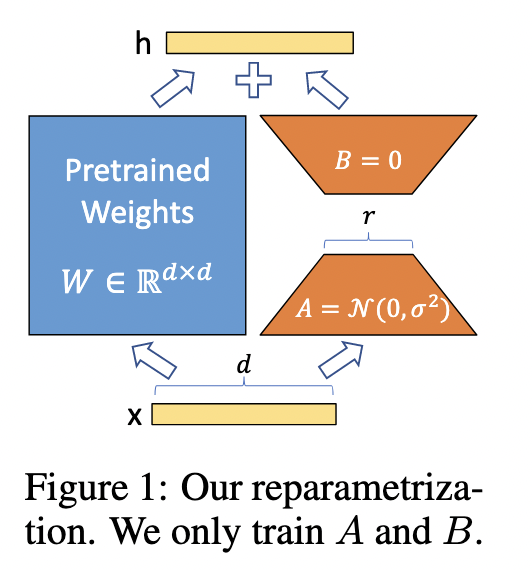
如上图所示,LoRA的思想很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank 。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证开始训练时,此旁路矩阵依然是0矩阵。
具体来说,假设预训练的参数矩阵为$W_0$,它的更新可表示为:
有点类似于残差连接,使用旁路的更新来模型full fine-tuning。并且full fine-tuning可以看作时LoRA的特例。
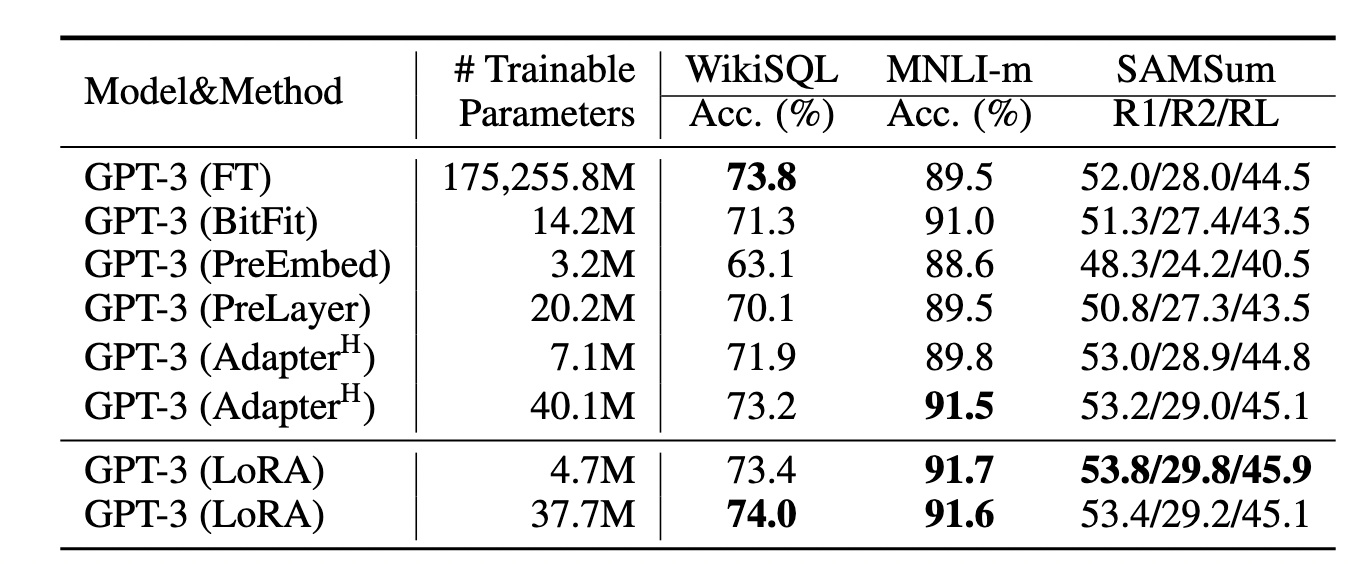
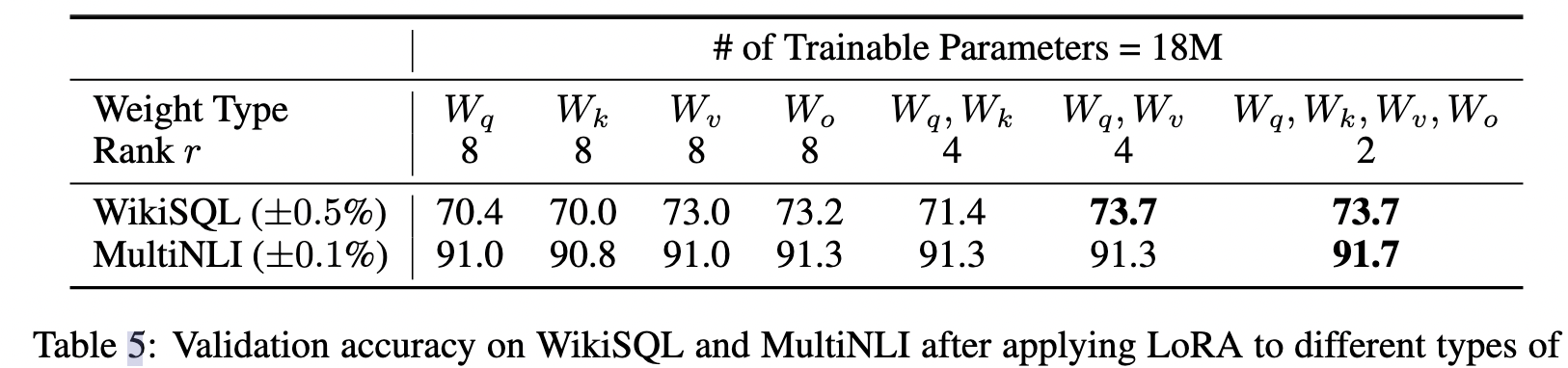
LoRA与transformer的结合也很简单,在transformer中,在self-attention中有四个权重矩阵$W_q,W_k,W_v,W_o$以及俩个MLP权重。作者仅在self-attention的计算中应用LoRA,而不动MLP模块。对于加在哪个权重参数上,作者做了一系列ablation study,如下表所示:
当部署在生产中时,我们可以显式计算和存储 W = W0 + BA 并像往常一样执行推理,几乎未引入额外的inference latency。
通过实验也发现,众多数据集上LoRA在只训练极少量参数的前提下,达到了匹配full fine-tuning,是一种高效的参数更新方法。相比Adapter, BitFit,LoRA在较少训练参数时就能保证比较稳定的效果。