这篇文章介绍多模态预训练的一个系列-BLIP,以及针对BLIP改进和延续的一些相关工作。
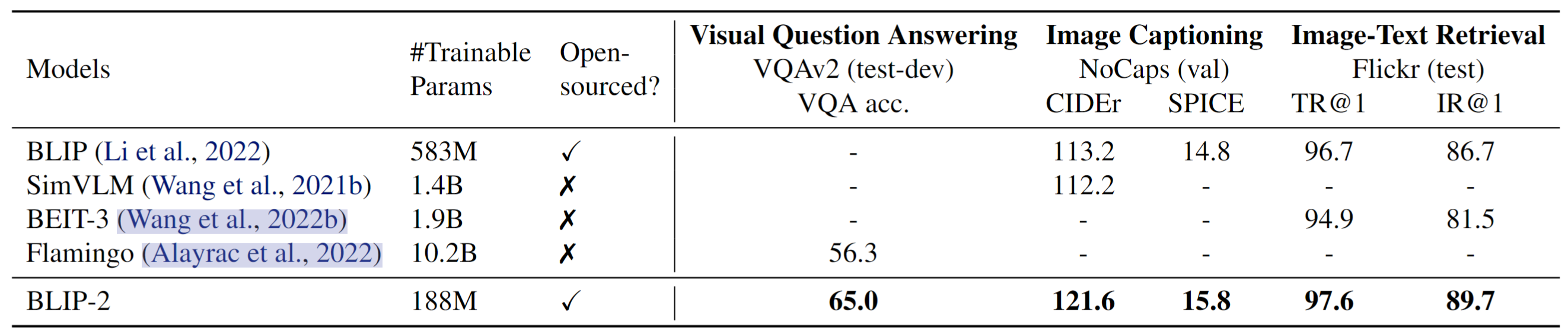
BLIP
这篇也是做的多模态预训练任务,之前的工作都是在于统一vision-language的理解任务,这篇工作同时支持理解和生成任务。这篇文章的作者和ALBEF的作者是同一人。
motivation
模型角度:现有方法分为encoder-based model和encoder-decoder model, 都存在一些问题,前者无法支持下游的生成任务,例如CLIP不支持image-caption;后者比如SimVLM在image-text retreval上效果差。
数据角度:使用互联网上爬取到的图像文本对,含有很多噪声;
BLIP
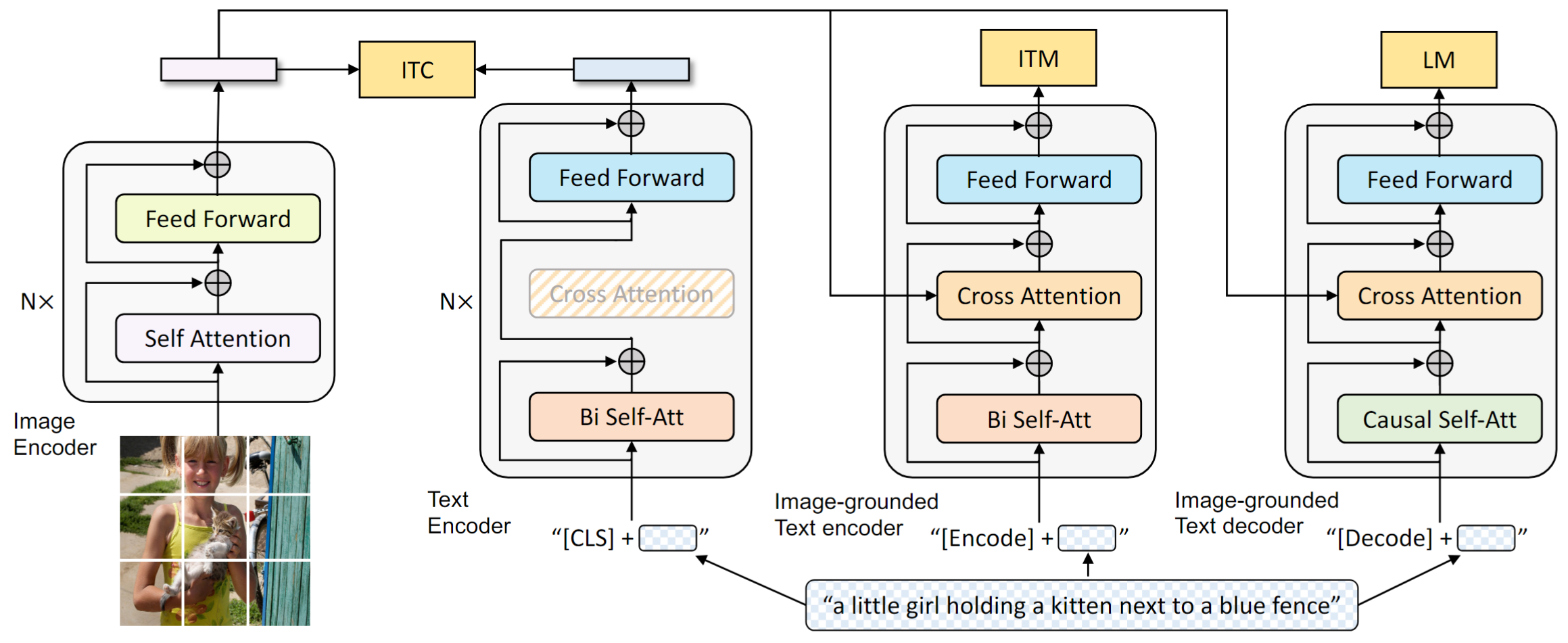
上图的模型结构中包含了四个部分image encoder, text encoder, image-grounded text encoder, image-grounded text decoder. image encoder, text encoder分别使用的是ViT和Bert提取图像特征和文本特征。image-grounded text encoder引入图像特征做cross attention,用来做图像文本匹配(ITM)任务。 image-grounded text decoder不同于前者,将self attention替换成causal self-attention用于语言模型任务。
需要注意的是,与text相关的text encoder和Image-grounded Text encoder的共有结构特征是共享的,为了标记差异,在文本的开头分别用”[CLS]”和”[Encoder]”标记。而Image-grounded Text decoder中使用”[Decoder]”。
Pre-training Objectives
在预训练中有三个目标函数,两个是基于理解的预训练任务以及一个基于生成的预训练任务。计算量比较大的image encoder只需要运算一次。
- Image-Text Contrastive Loss(ITC):目的都是为了对齐视觉和文本模态的特征;
- Image-Text Matching Loss (ITM):判断图像和文本是否匹配,二分类任务;
- Language Modeling Loss (LM):不同于MLM任务,这里使用的是NTP;
CapFilt
在BLIP中为了提升预训练数据的质量,作者设计了CapFlit,在预训练任务中包含生成字幕的预训练任务也有判断图文是否匹配的预训练任务,因此可以让模型生成图片的描述(Captioner),再通过Filter用于判断图像和文本是否匹配。如下图,原始的图文不匹配,在最终预训练时会被过滤掉,而Captioner生成的文本和图片匹配,则在最终预训练时会保留生成的数据。
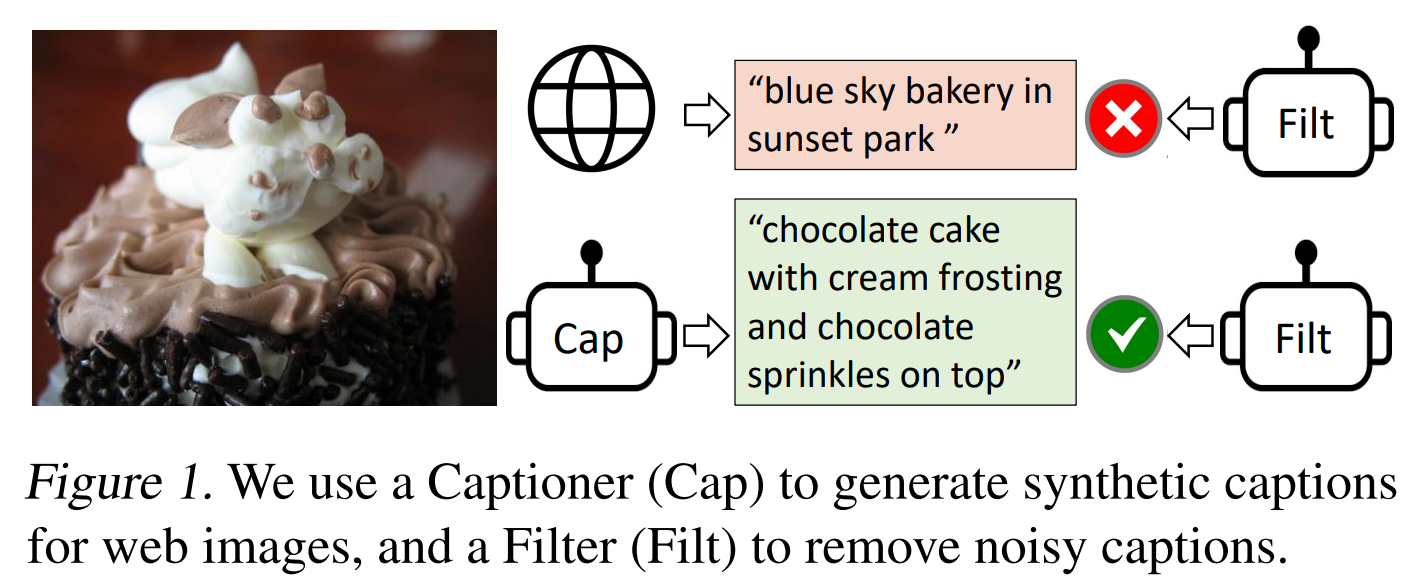
文中也展示了一些对比的case,从case上看合成的caption比直接从web爬取的caption质量明显好很多。

BLIP-2
同样出自Junnan Li, BLIP2新增了一个Querying Transformer (Q-Former),BLIP2训练需要two stage训练。第一个预训练阶段,我们执行vision-language representation learning,强制Q-Former学习与文本最相关的视觉表示。在第二个预训练阶段,我们通过将Q-Former的输出连接到冻结的LLM来执行视觉到语言的生成 学习,并训练Q-Former,使其输出视觉表示可以被LLM解释。如下图所示:
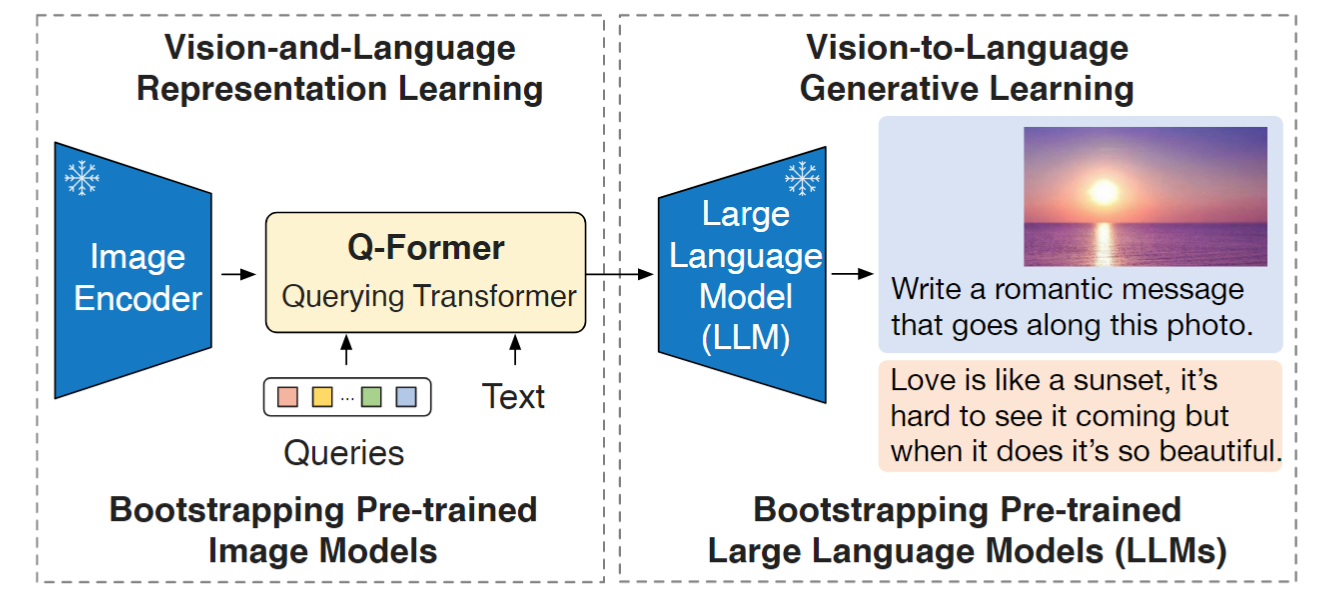
motivation
- The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models;
- Pre-trained vision models offer high-quality visual representation.
- Pre-trained language models, in particular large language models (LLMs), offer strong language generation and zero-shot transfer abilities.
一方面,现有的视觉-语言预训练模型越做越大,使得计算成本不断增加;另一方面,预训练的视觉模型/语言模型具有很强的能力,因此作者想到使用frozen的预训练的视觉/语言模型来做视觉-语言对齐的预训练任务。
method
训练Q-Former需要两步,分别是vision-language representation learning stage和vision-to-language generative learning stage。
- vision-language representation learning stage
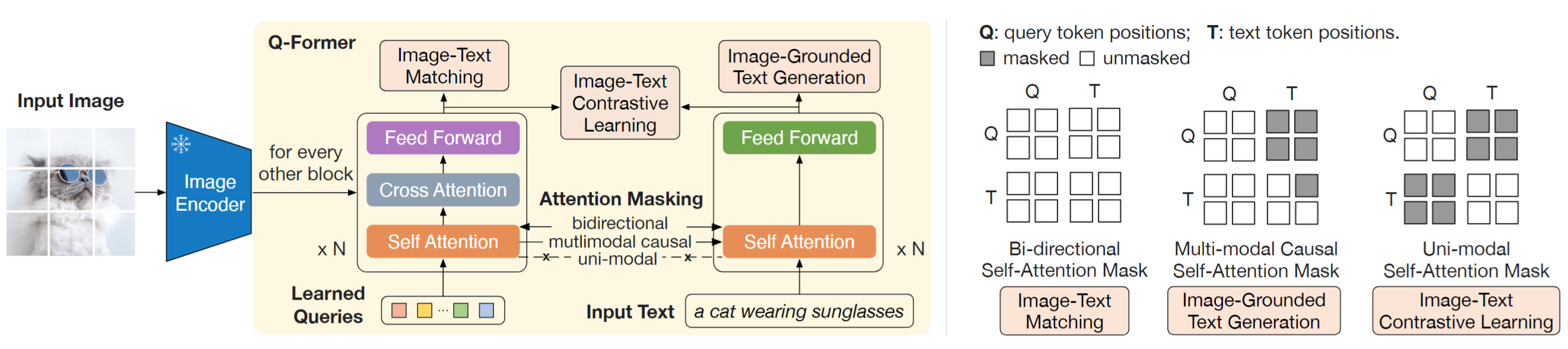
QFormer由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层。QFormer使用= BERTbase 的预训练权重初始化,而交叉注意力层是随机初始化。 Q-Former 总共包含 188M 参数。QFormer拥有 32个query,768维,是远小于ViT-L/14的 257x1024维度的。image encoder是冻结的。和BLIP类似,有三个优化函数:
- Image-Text Contrastive Loss(ITC):目的都是为了对齐image representation和text representation;这里的image representation是输出的query representation(32x768),text representation是text transformer CLS token。计算互信息最大的那个query做梯度反传。为了防止信息泄露,query和text不能互相看见。
- Image-Text Matching Loss (ITM):同BLIP,query和text互相都可以看见,做了更细粒度的匹配。
- Image-grounded Text Generation:训练Q-Former在给定图像情况下,生成文字。这里没有显式输入图像信息,而是与learnable query进行交互,text 可以看到query 和 当前和历史的text,query还是只能看到query。这里强迫了learnable query必须summary图像的抽象信息。
- vision-to-language generative learning stage
在第一个阶段,已经训练得到了一个Q-Former,可以提取图像全局特征和重要的信息。第二个阶段,Q-Former被接入到LLM上,获取生成语言的能力。
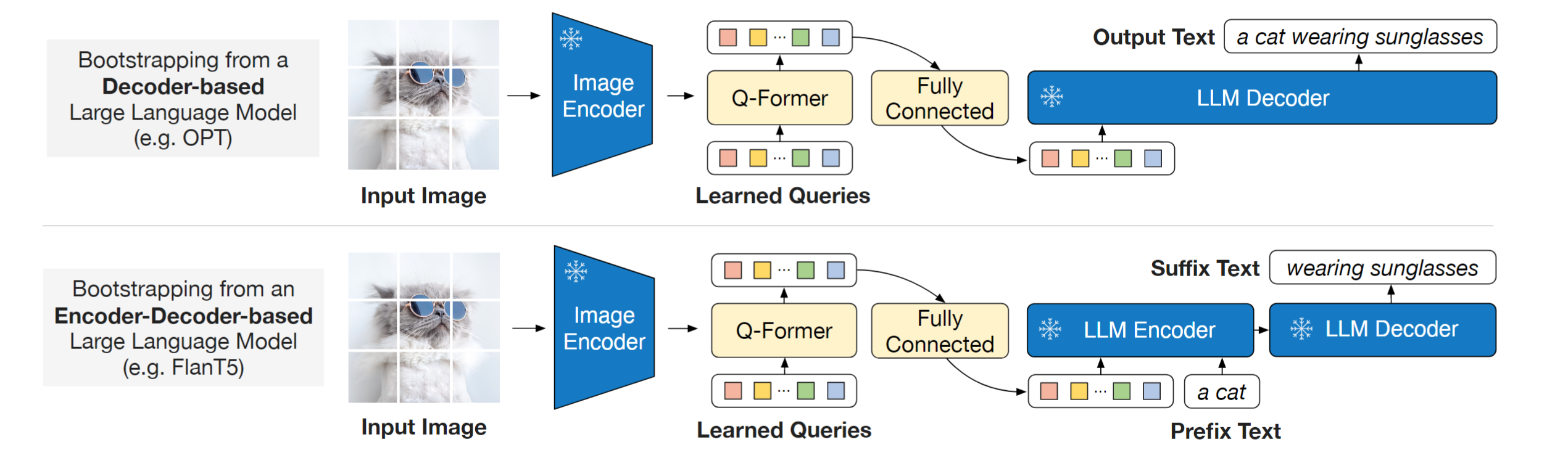
首先使用一个FC对齐Q-Former的维度和LLM text embedding维度。然后可以把图像浓缩信息传入到LLM中,因为第一个阶段有ITG来监督文本的generation,因此这个图像info天然的可以直接用于LLM,第一阶段已经做了微对齐。
experiments
微调带来了第一个好处就是机器成本下降,文中提到”For example, using a single 16-A100(40G) machine, our largest model with ViT-g and FlanT5-XXL requires less than 6 days for the first stage and less than 3 days for the second stage.”。 BLIP2 也展现了强大的zeroshot vision-language 任务。