在NLP任务中,在大模型上进行Fine-tuning是一种有效地迁移学习方法。尤其是,BERT、RoBERTa等模型的提出为NLP的下游任务的解决提供了极大的便利。但在大模型上对下游任务进行fine-tuning时,大模型参数动辄数十亿,存储和训练这种大模型是十分昂贵且耗时的。而且需要庞大计算资源。参数高效微调(Parameter-Efficient Fine-Tuning,PEFT) 方法旨在解决这两个问题,PEFT 方法仅微调少量 (额外) 模型参数,同时冻结预训练大模型 的大部分参数,从而大大降低了计算和存储成本。这也克服了灾难性遗忘 的问题, PEFT 方法在小数据集上也可以取得和全参数fine-tune一样的效果。下文详细介绍一下 参数高效微调方法中的Adapter以及Adapter Fusion。
Adapter
Title: Parameter-Efficient Transfer Learning for NLP
Author: Neil Houlsby(Google Research).etc
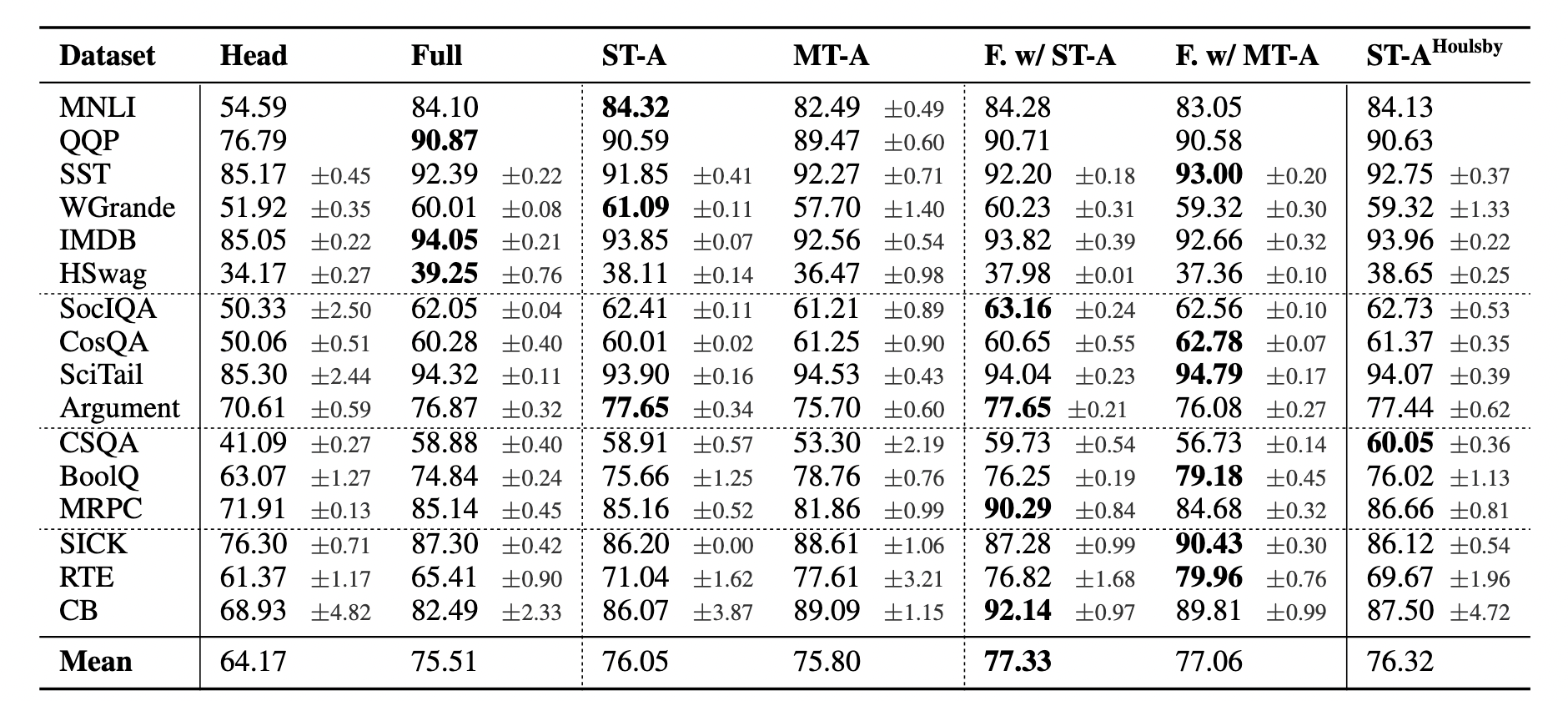
这篇论文是发表在ICML2019,改论文中提出了Adapter,通过在大模型中插入adapter module,训练时只需训练adapter module,相比于全参数fine-tuning,Adapter只需要训练较少参数即可取得全参数fine-tuning相当的结果。先直观感受一下,Adapter和fine-tune的指标比较,如下图所示:
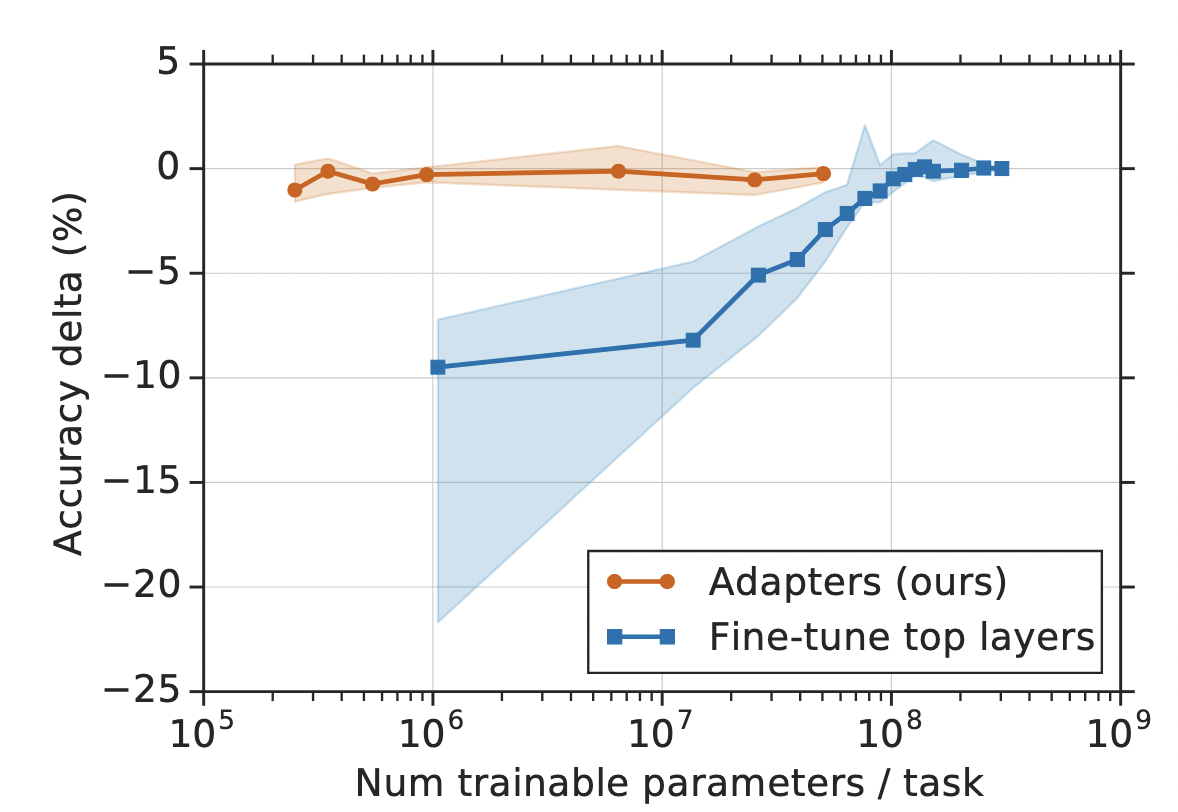
下图展示的是adapter module 结构以及插入transformer layer后的结构。
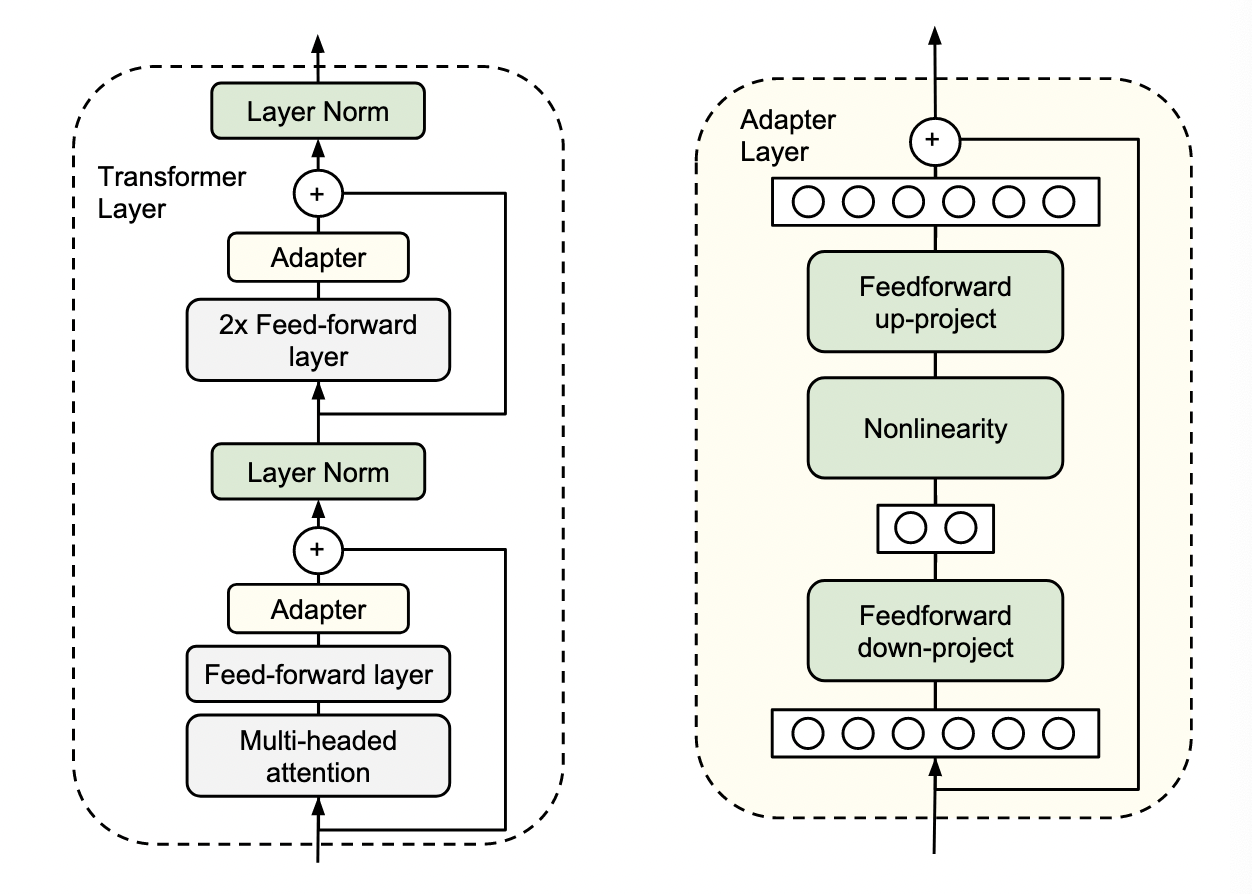
在在Adapter内部,它的输入h通过矩阵乘法Wdown,先将特征维度缩小,然后通过一个非线形层$f$,再通过矩阵乘法Wup将特征维度放大到跟adapter输入一样的尺寸,最后通过一个跨层连接,将adapter的输入跟上述结果加到一起作为最终adapter的输出,即下图形式。
至于adapter引进的模型参数,假设adapter的输入的特征维度是d,而中间的特征维度是m,那么新增的模型参数有:down-project的参数Wdown 为dxm+m,Wup的参数mxd+d,总共2md+m+d,由于m远小于d,所以真实情况下,一般新增的模型参数都只占语言模型全部参数量的0.5%~8%。同时要注意到,针对下游任务训练需要更新的参数除了adapter引入的模型参数外,还有adapter层后面紧随着的layer normalization层参数需要更新,每个layer normalization层只有均值跟方差需要更新,所以需要更新的参数是2d。(由于插入了具体任务的adapter模块,所以输入的均值跟方差发生了变化,就需要重新训练)
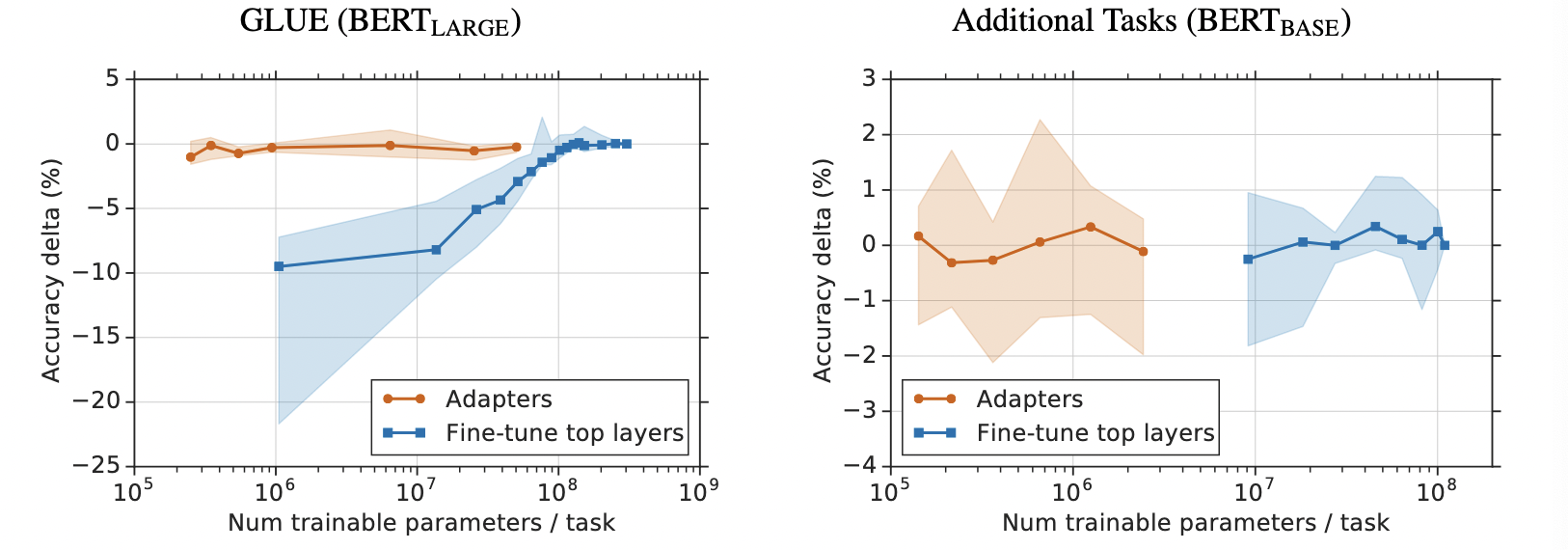
通过实验,可以发现只训练少量参数的adapter方法的效果可以媲美finetune语言模型全部参数的传统做法。这也验证了adapter是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。同时,可以看到不同数据集上adapter最佳的中间层特征维度m不尽相同。

为了进一步探究adapter的参数效率跟模型性能的关系,论文做了进一步的实验,同时比对了fine-tune的方式(只更新最后几层的参数或者只更新layer normalization的参数),从结果可以看出adapter是一种更加高效的参数更新方式,同时效果也非常可观,通过引入0.5%~5%的模型参数可以达到不落后先进模型1%的性能。
Adapter Fusion
Title: AdapterFusion: Non-Destructive Task Composition for Transfer Learning
Author: Jonas Pfeiffer(UKP Lab).etc
这是2020年5月份挂载arxiv上的一篇论文,被EACL 2021接收,这篇论文提出了一种adapter变种,Adapter Fusion,用于融合多任务信息。在了解Adapter Fusion之前,先看一下这个方法提出的任务背景。我们将C 定义为 N 个分类任务的集合,具有不同规模大小的标记数据和不同的损失函数:
其中,D表示标注数据,L表示损失函数。我们的目的是能够利用上述一组 N 个任务来改进目标任务m,$C_m=(D_m,L_m)$,如下所示,期望先从N个任务中学到一个模型参数(最右边参数),然后利用该参数来学习特定任务m下的一个模型参数(最左边参数):
当前主流方法在处理上述问题时,通常有两种方法:
(1)Sequential Fine-Tuning:顺序微调,在每个任务上顺序更新模型的所有权重,在每一步,模型都使用上一步学习的参数进行初始化;
(2)Multi-Task Learning (MTL):多任务学习,所有任务都是同时训练,学习一个共享表示,使模型能够更好地泛化每个任务;
前者方法容易发生灾难性遗忘问题(catastrophic forgetting),后者需要同时访问所有任务数据,不同数据集大小和损失函数各不相同,如何平衡具有较大挑战。为了为了解决上述问题,Adapter Fusion提出一个两阶段的学习策略,其中第一阶段是knowledge extraction stage,在不同任务下引入各自的adapter模块,用于学习特定任务的信息,而第二阶段是knowledge composition step,用于学习聚合多个任务的adapter。
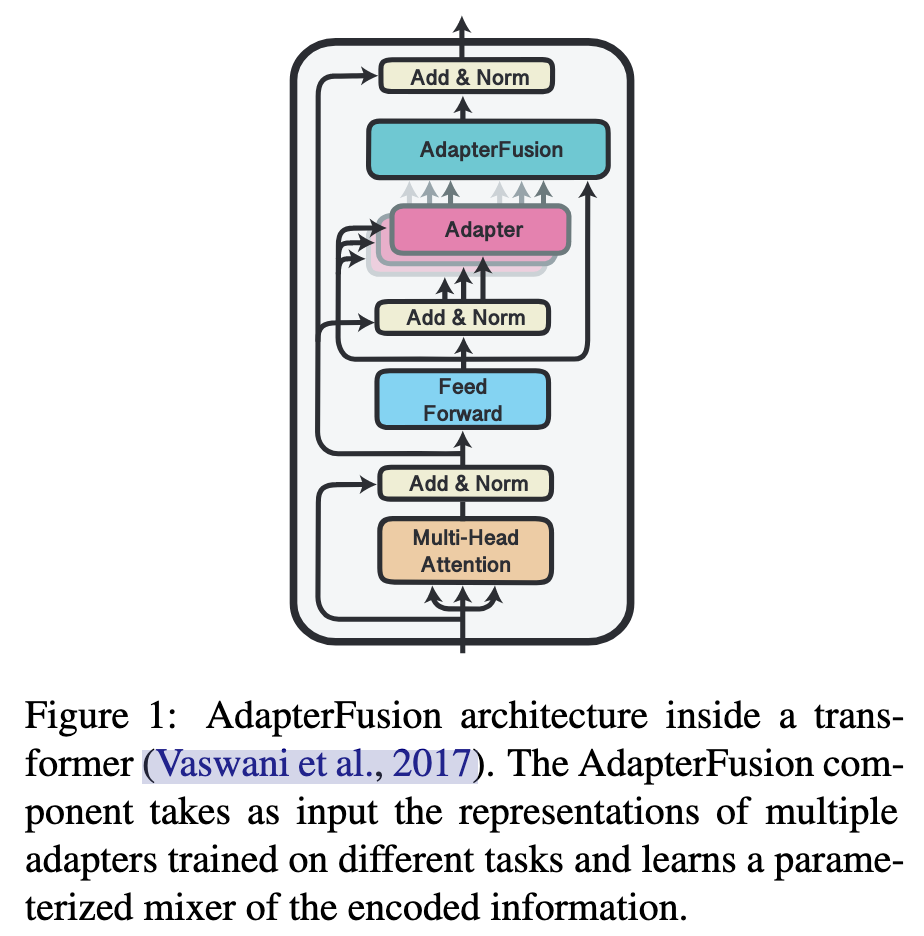
上图展示的是AdapterFusion在transformer中的结构,其中有多个Adapter模块,以及一个Adapter Fusion模块。后者用于融合前者信息。和上一篇论文提出的结构相比,这里去除了multi-head attn后面的Adapter模块。下面详细介绍Adapter Fusion提出的两阶段的学习策略。
(1)knowledge extraction stage
对于该阶段有俩种训练方式,Single-Task Adapters (ST-A),Multi-Task Adapters (MT-A)。
a. Single-Task Adapters (ST-A):对于N个任务,模型都分别独立进行优化,各个任务之间互不干扰,互不影响。对于其中第n个任务而言,相应的目标函数如下所示:
其中$\Phi$ 表示 adapter的权重参数,$\Theta_0$ 表示大模型的预训练参数。
b. Multi-Task Adapters (MT-A):N个任务通过多任务学习的方式,进行联合优化,相应的目标函数如下:
(2)knowledge composition step
对于第二阶段,就是adapter fusion大展身手的时候了。为了避免通过引入特定任务参数而带来的灾难性遗忘问题,adapter fusion提出了一个共享多任务信息的结构。针对特定任务m,adapter fusion联合了第一阶段训练的到的N个adapter信息。固定模型的预训练参数跟N个adapter的参数,新引入adapter fusion的参数,目标函数也是学习针对特定任务m的adapter fusion的参数$\Psi_m$:
Adapter fusion的具体结构就是一个attention,它的参数包括query,key, value的矩阵参数,在transformer的每一层都存在,它的query是transformer每个子模块的输出结果,它的key跟value则是N个任务的adapter的输出。通过adapter fusion,模型可以为不同的任务对应的adapter分配不同的权重,聚合N个任务的信息,从而为特定任务输出更合适的结果。
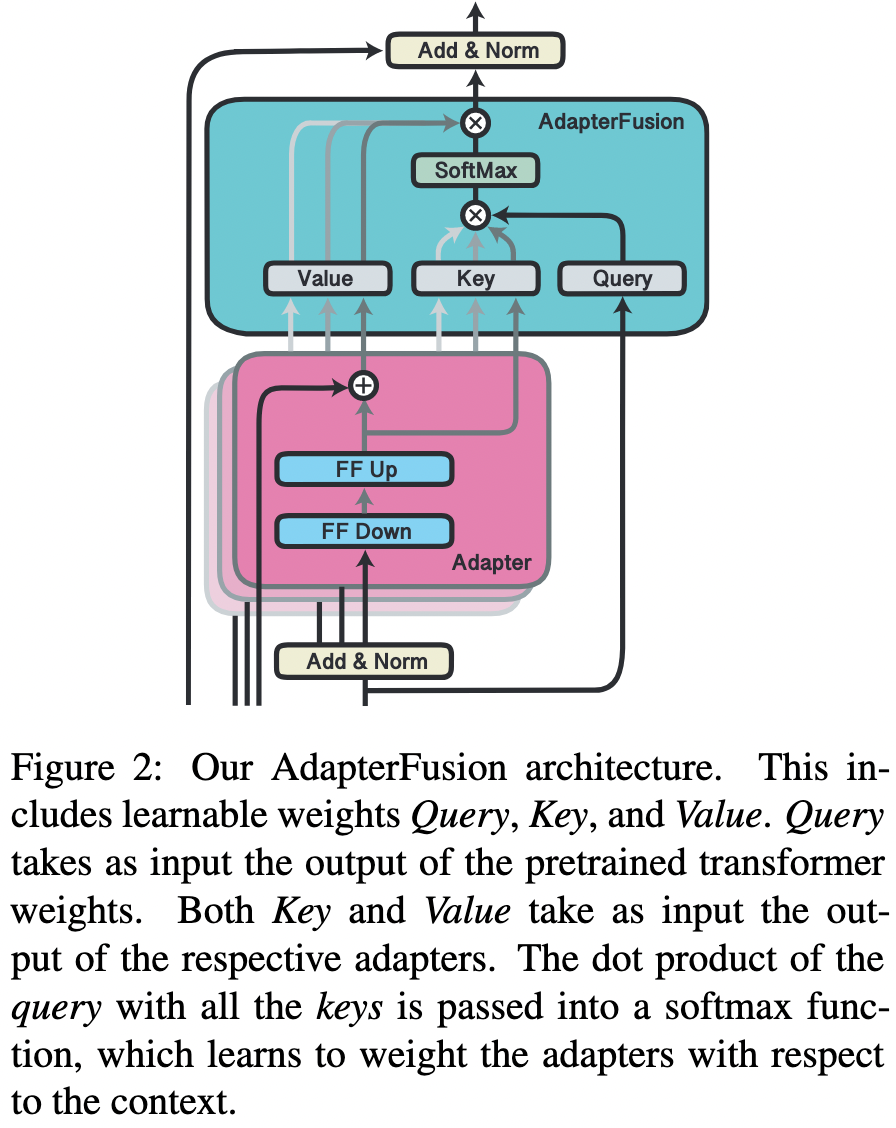
通过实验发现,第一阶段采用ST-A+第二阶段Adapter fusion是最有效的方法,在多个数据集上的平均效果达到了最佳。关于MT-A+adapter fusion没有取得最佳的效果,在于第一阶段其实已经联合了多个任务的信息了,所以adapter fusion的作用没有那么明显,同时MT-A这种多任务联合训练的方式需要投入较多的成本,并不算一种高效的参数更新方式。