论文信息: Going Deeper with Nested U-Structure for Salient Object Detection
代码链接:https://github.com/NathanUA/U-2-Net
整体信息: 这是发表在PR2020上的一篇关于显著性检测的文章,作者是秦雪彬。从标题上可以看到本文的一个idea是设计了一个deeper的U型结构的网络解决显著性目标检测问题。作者认为,目前显著性目标检测有两种主流思路,一为多层次深层特征集成multi-level deep feature integration,一为多尺度特征提取Multi-scale feature extraction。多层次深层特征集成方法主要集中在开发更好的多层次特征聚合策略上。而多尺度特征提取这一类方法旨在设计更新的模块,从主干网获取的特征中同时提取局部和全局信息。而几乎所有上述方法,都是为了更好地利用现有的图像分类的Backbones生成的特征映射。而作者另辟蹊径,提出了一种新颖而简单的结构,它直接逐级提取多尺度特征,用于显著目标检测,而不是利用这些主干的特征来开发和添加更复杂的模块和策略。下图是该方法与其他方法的一个比较:
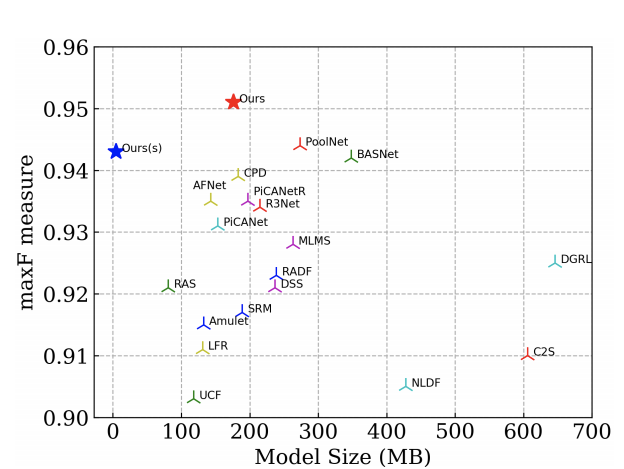
显著性检测
在讲这篇文章之前,有必要先了解显著性检测这个任务。
显著性检测,就是使用图像处理技术和计算机视觉算法来定位图片中最“显著”的区域。显著区域就是指图片中引人注目的区域或比较重要的区域,例如人眼在观看一幅图片时会首先关注的区域。例如下图,我们人眼一眼看过去首先注意到的不是草坪,而是躺在草坪上的内马尔,内马尔所在的区域就是显著性区域。这种自动定位图像或场景重要区域的过程称为显着性检测。

显著性检测和图像分割区别
这个任务和图像分割十分类似,区别在于:
- 1.目标数量:显著性目标检测一般只检一个目标,一般目标检测不会限制数量;
- 目标类别: 显著性目标检测不关心目标类别,只关心显著性强的目标,一般目标检测会得到目标位置和类别;
- 问题建模不同:显著性目标检测,很早期的时候是通过对一些共性的特征建模,比如该目标一般在图像中心,一般是什么样的颜色分布等等。一般目标检测问题,则是希望特征能够更好的把目标表达出来,越细节越好,特征越丰富约好,因为要区分类别
- groundtruth定义不同:两者互有交集,也有不同;前者,往往定义的是一些显著性较强的目标,比如行人,动物等等,而且前者是不输出类别标签信息;后者,gt标签定义是明确的,可以严格的输出对应类别标签;
其实,说白了,显著性检测等同于是一个二分类的语义分割模型,此外,显著的区域 不一定就是 目标,目标很可能不是显著的;
方法设计
Residual U-blocks
了解了显著性检测这个任务之后,来具体了解一下这篇文章的具体方法设计。作者设计一种Residual U-blocks,用于捕获 intra-stage 的 multi-scales 特征。
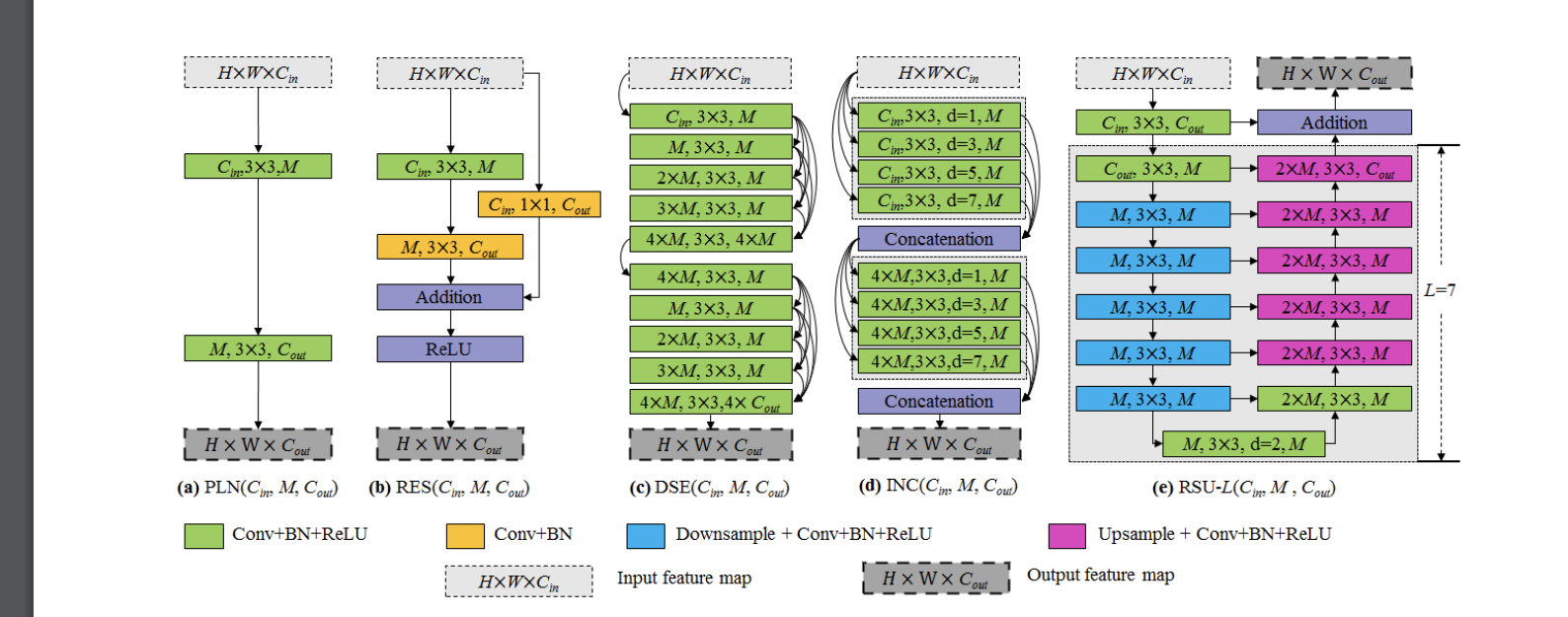
上图为普通卷积block,Res-like block,Inception-like block,Dense-like block和Residual U-blocks的对比图,明显可以看出Residual U-blocks是受了U-Net的启发。
Residual U-blocks有以下三部分组成:
- 一个输入卷积层,它将输入的feature map x (H × W × $C{in}$)转换成中间feature map $F_1(x)$,$F_1(x)$通道数为$C{out}$。这是一个用于局部特征提取的普通卷积层。
- 一个U-like的对称的encoder-decoder结构,高度为L,以中间feature map $F_1(x)$为输入,去学习提取和编码多尺度文本信息$U(F_1(x))$,U表示类U-Net结构。更大L会得到更深层的U-block(RSU),更多的池操作,更大的感受野和更丰富的局部和全局特征。配置此参数允许从具有任意空间分辨率的输入特征图中提取多尺度特征。从逐渐降采样特征映射中提取多尺度特征,并通过渐进上采样、合并和卷积等方法将其编码到高分辨率的特征图中。这一过程减少了大尺度直接上采样造成的细节损失。
- 一种残差连接,它通过求和来融合局部特征和多尺度特征:$F_1(x) + U(F_1(x))$。
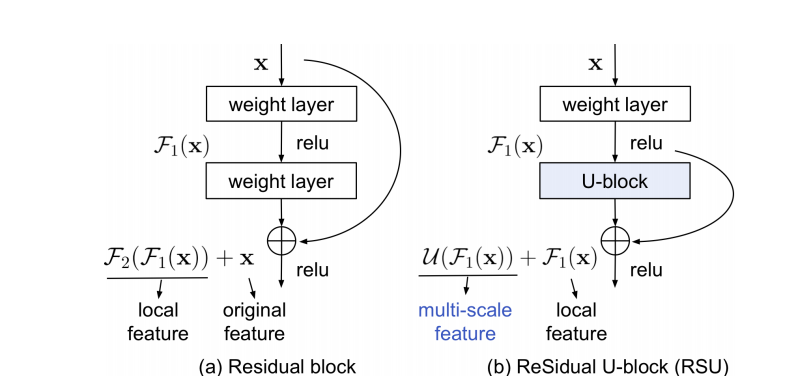
RSU与Res block的主要设计区别在于RSU用U-Net结构代替了普通的单流卷积,用一个权重层(weight layer)形成的局部特征来代替原始特征。这种设计的变更使网络能够从多个尺度直接从每个残差块提取特征。更值得注意的是,U结构的计算开销很小,因为大多数操作都是在下采样的特征映射上进行的。
U^2-Net的结构
U^2-Net的网络结构如下:
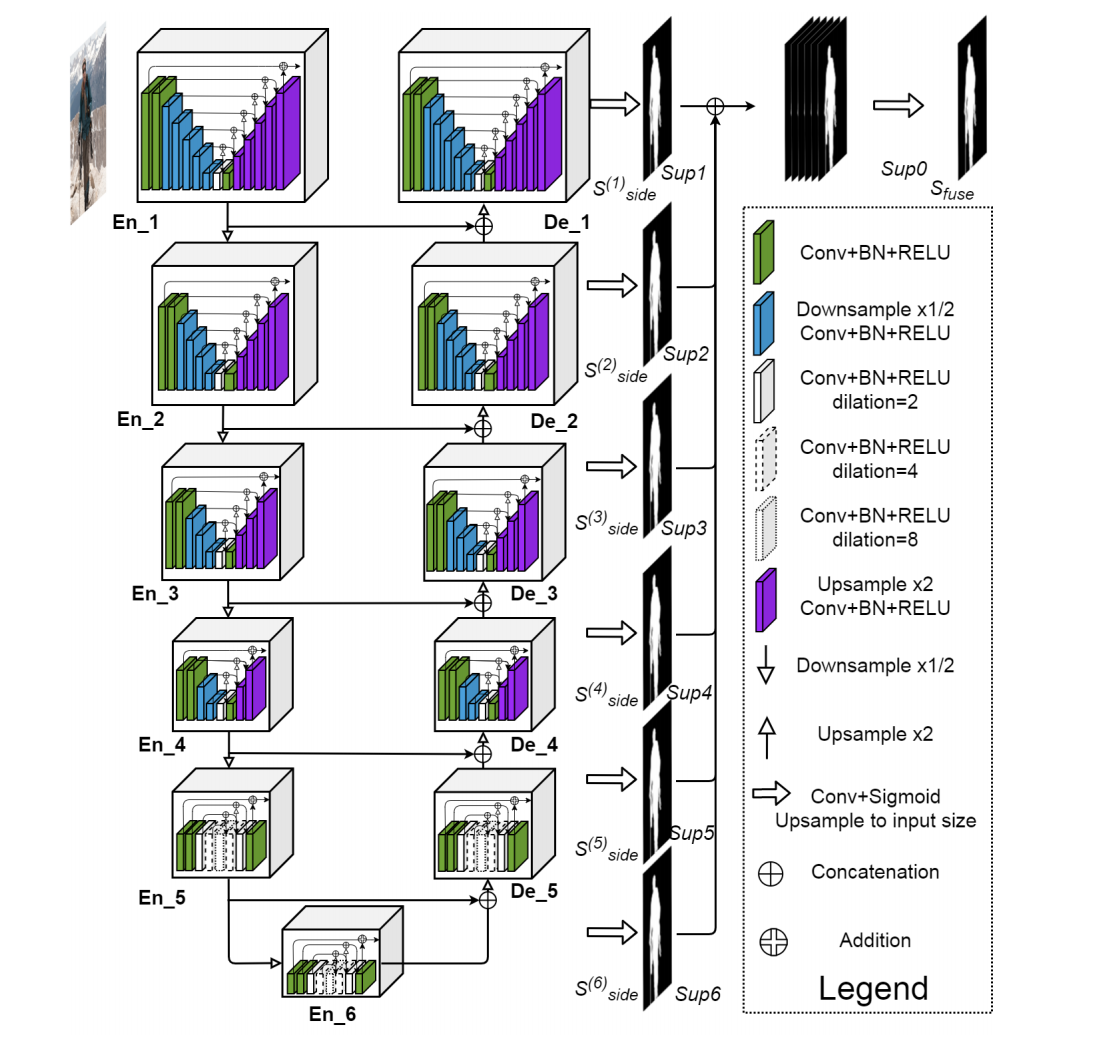
与U-Net的网络结构做一个对比:

直观上可以发现,U^2-Net的每一个Block都是一个U-Net结构的模块,即上述Residual U-blocks。当然,你也可以继续Going Deeper, 每个Block里面的U-Net的子Block仍然可以是一个U-Net结构,命名为U^3-Net。
损失函数设计
类似于HED算法的deep supervision方式,作者设计了如下函数:
其中,M=6, 为U2Net 的 Sup1, Sup2, …, Sup6 stage.$w{\text {side}}^{(m)}$ $l{\text {side}}^{(m)}$ 为对应的损失函数输出和权重;$w{f u s e} \ell{f u s e}$ 为融合的损失函数和权重;对于每一个$l$使用的都是标准的BCE Loss:
实验可视化
所提出的模型是使用DUTS-TR数据集进行训练,该数据集包含大约10000个样本图像,并使用标准数据增强技术进行扩充。研究人员在6个用于突出目标检测的基准数据集上评估了该模型:DUT-OMRON、DUTS-TE、HKU-IS、ECSSD、PASCAL-S和SOD。评价结果表明,在这6个基准点上,新模型与现有方法具有相当好的性能。

U^2-Net的实现是开源的,并提供了两种不同的预训练模型:U2Net(176.3M的较大模型,在GTX 1080Ti GPU上为30 FPS),以及U2NetP(4.7M小模型,最高可达到40 FPS)。代码和预训练模型都可以在Github。下面是我直接用作者开源的模型跑出来的结果,抠图效果很好,精细到发丝的那种。

总结
该论文的优势在于:
- 提出RSU模块,融合不同尺度感受野的特征,来捕捉不同尺度的上下文信息;
- 基于 RSU 模块的 池化(pooling) 操作,在不显著增加计算成本的前提下,增加了整个网络结构的深度(depth).