论文信息: End to End Object Detection with Transformers
代码链接: https://github.com/facebookresearch/detr
整体信息: 这是FAIR最近新出了一篇用transformer做检测的文章。相比于以往所有的检测方法不同的是,没有使用先验知识比如anchor设计,以及后处理步骤比如nms等操作。而是使用transformer预测集合的形式,直接输出目标位置及类别信息。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型generalize到panoptic segmentation任务上,DETR表现甚至还超过了其他的baseline.
1.概览
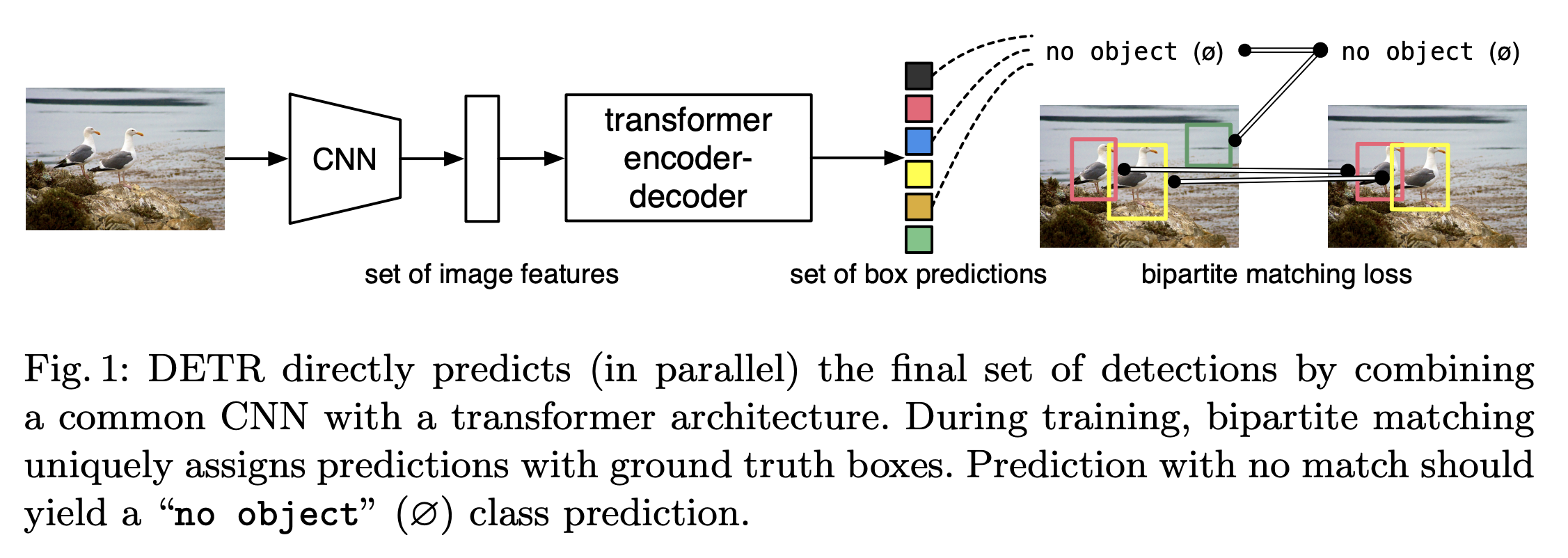
上图展示的是DETR的整体结构图。如上图所示,可以看出两个关键的部分:
- 使用transformer 的encoder-decoder结构生成N个 box predictions;其中N为事先设计的、远大于图像中object数的一个整数;
- 设计了bipartite matching loss,基于预测的box和gt box的二分图匹配计算loss,从而使得预测的box更接近gt box;
这篇文章的撰写风格比较诡异,不是按照正常的网络结构的先后顺序来介绍各个部分。而是先介绍了bipartite matching loss,再介绍transformer的encoder和decoder。为了便于理解,我这里还是按照网络结构的先后顺序来介绍各个模块。
2.Transformer
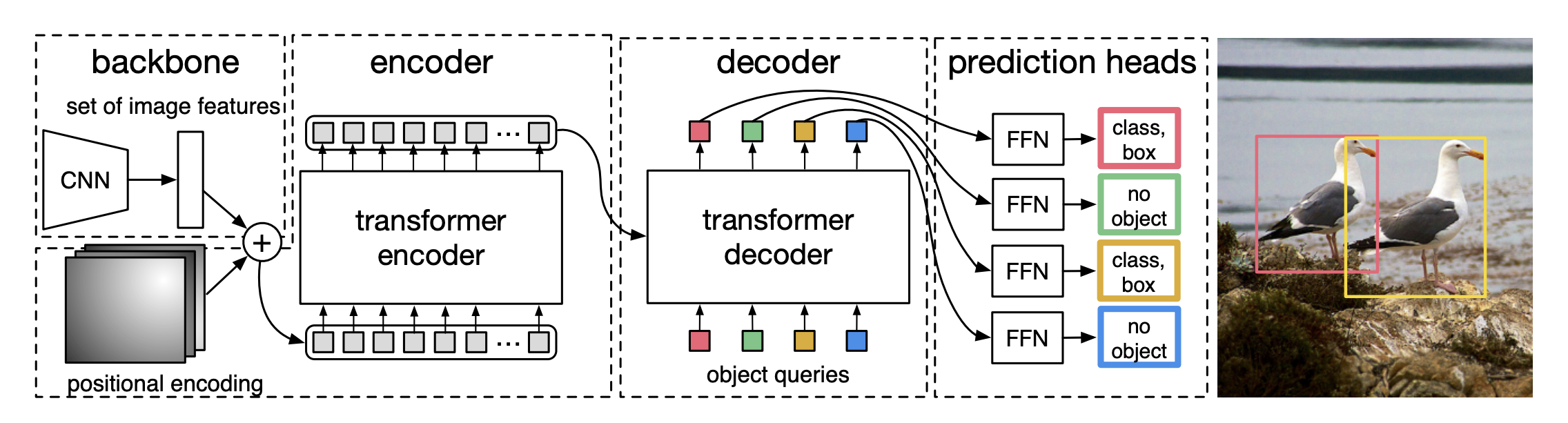
上图展示的是transformer的结构,其中包括encoder、decoder以及FFN三部分。
2.1 Transformer Encoder
如上图左侧所示,在DETR中,首先输入图片 $x{\mathrm{img}} \in \mathbb{R}^{3 \times H{0} \times W{0}}$ 经过CNN backbone处理后,输出feature map$f \in \mathbb{R}^{C \times H \times W}$ ,一般 $C=2048,H, W=\frac{H{0}}{32}, \frac{W_{0}}{32}$ 。然后将backbone输出的feature map和position encoding相加,输入Transformer Encoder中处理,得到用于输入到Transformer Decoder的image embedding。由于Transformer的输入为序列化数据,因此会对backbone输出的feature map做进一步处理转化为序列化数据,具体处理包括如下:
- 维度压缩:使用1x1卷积将feature map 维度从C压缩为d,生成新的feature map $z_{0} \in \mathbb{R}^{d \times H \times W}$ ;
- 转化为序列化数据:将空间的维度(高和宽)压缩为一个维度,即把上一步得到的$d \times H \times W$维的feature map通过reshape成$d \times H W$维的feature map;
- 加上positoin encoding: 由于transformer模型是permutation-invariant(转置不变性,也可以理解为和位置无关),而显然图像中目标是具有空间信息的,与原图的位置有关,所以需要加上position encoding反映位置信息。具体生成的方法后续补充讲解。
2.2 Transformer Decoder
这部分的话,有两个输入,一个是Transformer Encoder的输出,另一个是object queries。这里讲一下object queries,object queries有N个,N是一个事先设定的、比远远大于image中object个数的一个整数),输入Transformer Decoder后分别得到N个 output embedding,然后经过FFN处理之后,输出N个box的位置和类别信息。object queries具体是什么,论文阐述的很模糊。
2.3 FFN
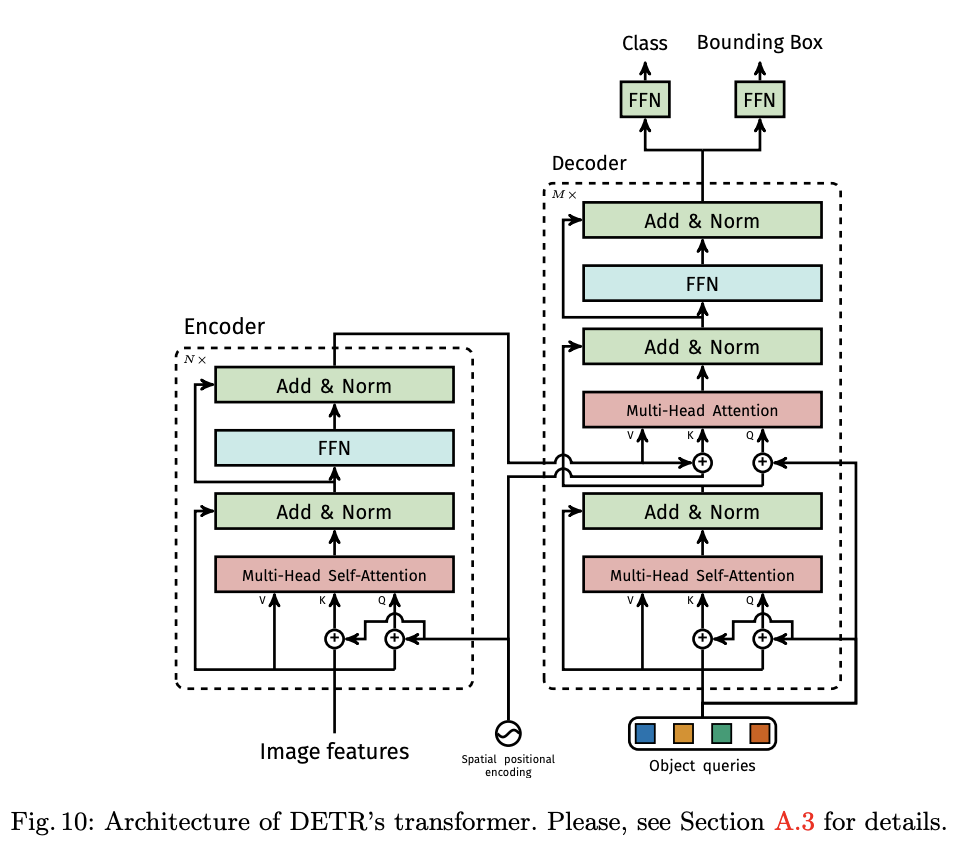
这个是网络结构最后的输出部分,在DETR中,其实有两种FFN:一种预测bounding box的中心位置、高和宽,第二种预测class标签。下图是更细节的DETR Transformer结构,大家感兴趣可以仔细看一下。
3. Loss设计
前面讲到transformer经过FFN之后会预测输出N个prediction boxes,其中,N是事先设计好的一个远大于image objects的正整数。通过得到这N个prediction boxes和image objects的最优二分图匹配,通过计算配对的box pair的loss来对模型进行优化。
3.1 最优二分图匹配
假设对于一张图来说,image objects的个数为m,由于N是事先设计好的一个远大于m的正整数,所以 N>>m,即生成的prediction boxes的数量会远远大于image objects 数量。这样怎么做匹配?
为了解决这个问题,作者人为构造了一个新的物体类别 $\varnothing$ (表示没有物体)并加入image objects中,上面所说到的多出来的N-m个个prediction embedding就会和类别 $\varnothing$ 配对。这样就可以将prediction boxes和image objects的配对看作两个等容量的集合的二分图匹配了。
设计好匹配的cost,就可以使用匈牙利算法快速地找到使cost最小的二分图匹配方案了。cost计算如下:
对应单个prediction box和image object匹配cost $\mathcal{L}{\operatorname{match}}\left(y{i}, \hat{y}_{\sigma(i)}\right)$计算如下:
其中,
$c_i$ 第i个image object的class标签,$\sigma(i)$ 表示与第i个image object匹配的prediction box的index;
$\mathbb{1}{c{i} \neq \varnothing}$ 是一个函数,当 $c_{i} \neq \phi$ 时为1,否则为0;
$\hat{p}{\sigma(i)}\left(c{i}\right)$ 表示Transformer预测第$\sigma(i)$ 个prediction box为类别$c_i$ 的概率;
$b{i}, \hat{b}{\sigma(i)}$ 分别为第i个image object和第$\sigma(i)$ 个prediction box的位置向量;
$\mathcal{L}{\mathrm{box}}\left(b{i}, \hat{b}_{\sigma(i)}\right)$ 计算的是ground truth box和prediction box之间的距离;具体计算方式论文有提及:
计算box的距离实验的IOU loss以及L1 loss。
这样,我们就完全定义好了每对prediction box和 image object 配对时的cost。再利用匈牙利算法即可得到二分图最优匹配。
3.2 计算set prediction loss
上面我们得到了prediction boxes和image objects之间的最优匹配。这里我们基于这个最优匹配,来计算set prediction loss,即评价Transformer生成这些prediction boxes的效果好坏。 set prediction loss的计算如下:
其中,$\hat{\sigma}$ 为最优匹配。将第 i个image object匹配到第$\hat{\sigma}(i)$ 个prediction boxes。这里值得注意的是,和上面计算cost不太一样的地方是这里计算分类概率使用的是log对数的形式;将匹配到类别 $\varnothing$ 的概率考虑进去了,而前面cost的计算中则直接将其置为0了;
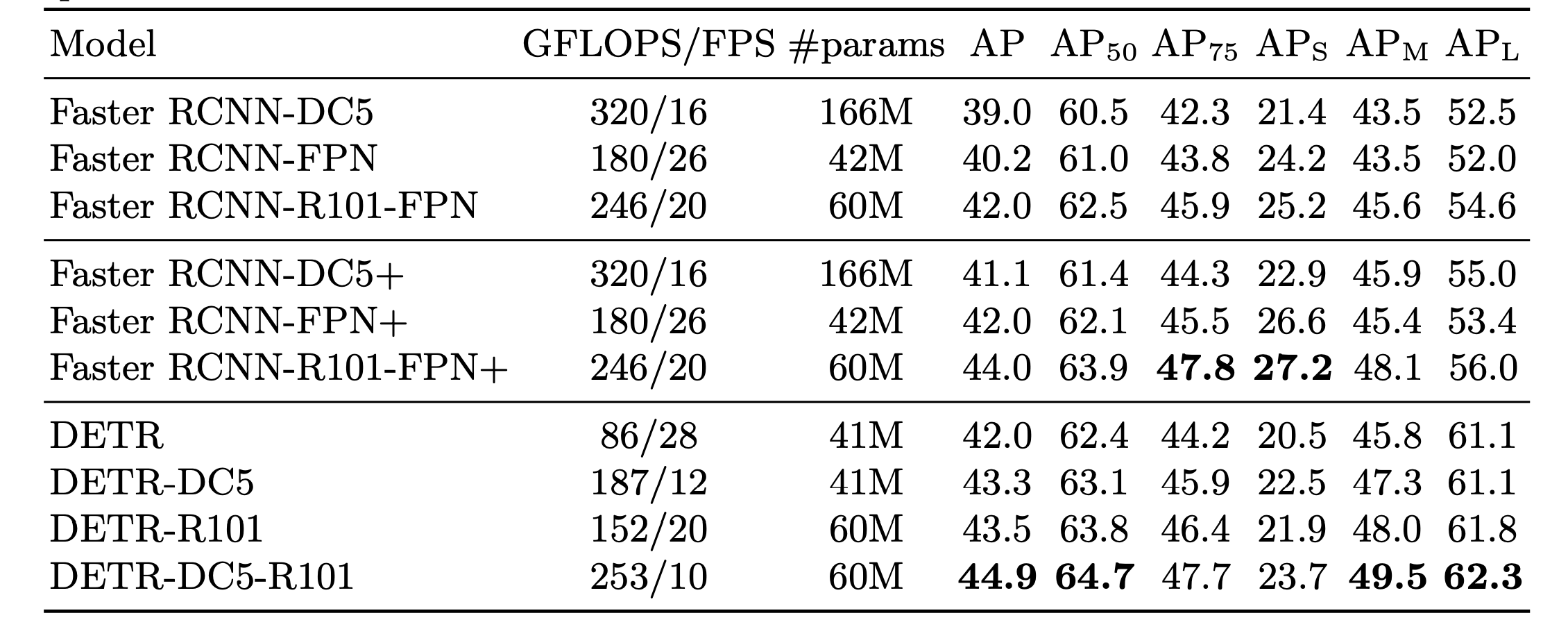
4.实验
论文中实验细节较多,而且实验结果也比较solid,这里不细讲,有兴趣的可以直接看原文,这里贴一张在coco上实验结果对比: