训练流程
训练流程的包装过程大致如下:tools/train.py->apis/train.py->mmcv/runner.py->mmcv/hook.py(后面是分散的), 其中 runner 维护了数据信息,优化器, 日志系统, 训练 loop 中的各节点信息, 模型保存, 学习率等. 另外补充一点, 以上包装过程, 在 mmdet 中无处不在, 包括 mmcv 的代码也是对日常频繁使用的函数进行了统一封装。
训练逻辑
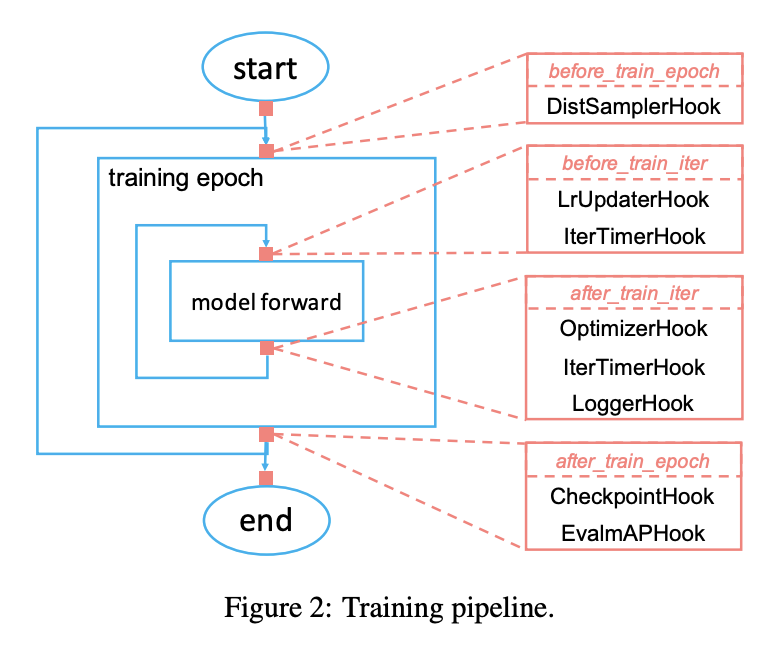
图见2, 注意它的四个层级. 代码上, 主要查看 apis/train.py, mmcv 中的runner 相关文件. 核心围绕 Runner,Hook 两个类. Runner 将模型, 批处理函数 batch_pro cessor, 优化器作为基本属性, 训练过程中与训练状态, 各节点相关的信息被记录在mode,_hooks,_epoch,_iter,_inner_iter,_max_epochs, _max_iters中,这些信息维护了训练过程中插入不同 hook 的操作方式. 理清训练流程只需看 Runner 的成员函数 run. 在 run 里会根据 mode 按配置中 workflow 的 epoch 循环调用 train 和 val 函数, 跑完所有的 epoch. 比如train:
1 | class EpochBasedRunner(BaseRunner): |
上面需要说明的是自定义 hook 类, 自定义 hook 类需继承 mmcv 的Hook 类, 其默认了 6+8+4 个成员函数, 也即2所示的 6 个层级节点, 外加 2*4 个区分 train 和 val 的节点记录函数, 以及 4 个边界检查函数. 从train.py 中容易看出, 在训练之前, 已经将需要的 hook 函数注册到 Runner的 self._hook 中了, 包括从配置文件解析的优化器, 学习率调整函数, 模型保存, 一个 batch 的时间记录等 (注册 hook 算子在 self._hook 中按优先级升序排列). 这里的 call_hook 函数定义如下:
1 | class BaseRunner(metaclass=ABCMeta): |
容易看出, 在训练的不同节点, 将从注册列表中调用实现了该节点函数的类成员函数. 比如
1 |
|
将在每个 train_iter 后实现反向传播和参数更新。学习率优化相对复杂一点, 其基类 LrUpdaterHook, 实现了 before_run,before_train_epoch, before_train_iter 三个 hook 函数, 意义自明. . 这里选一个余弦式变化, 稍作说明:
1 | def annealing_cos(start, end, factor, weight=1): |
从 get_lr 可以看到, 学习率变换周期有两种,epoch->max_epoch, 或者更大的 iter->max_iter, 后者表明一个 epoch 内不同 batch 的学习率可以不同, 因为没有什么理论, 所有这两种方式都行. 其中 base_lr 为初始学习率,target_lr 为学习率衰减的上界, 而当前学习率即为返回值.