论文信息: Xueyan Zou,UC Davis,NVIDIA
代码链接:https://github.com/MaureenZOU/
整体框架:这篇文章是前几天BMVC2020获得best paper award 的一篇文章,这篇文章提出了一个plugin module ,用来提高CNN的鲁棒性。在图像分类、图像分割、目标检测等任务上都能带来1+个点的提升。对于cnn,众所周知存在一个比较明显的缺陷:即使图像移动几个pixel都可能导致分类识别任务结果发生改变,作者发现其中重要原因在于网络中被大量用来降低参数量的下采样层导致混叠(aliasing)问题,即高频信号在采样后退化为完全不同的部分现象。为此提出了这样一个content-aware anti-aliasing的模块,用于缓解下采样过程中带来的高频信息的退化问题。
下采样的问题
以一维信号的的降采样为例:
对于k=2,stride=2的maxpool操作而言,对输入信号移动一位数字,经过maxpool之后的输出结果是截然不同的。而在CNN中大量使用降采样来降低参数量,这种aliasing问题更为明显,标准解决方案是在下采样之前应用低通滤波器(例如,高斯模糊)。但是,在整个内容上应用相同的过滤器可能不是最佳选择,因为特征的频率可能会在空间位置和特征通道之间发生变化。可以看下作者在论文中给出的实验结果:

上图(a)输入图片;(b)直接4x下采样;(c)应用经过调整以匹配噪声频率的单个高斯滤波器后的下采样结果;(d)应用多个空间自适应高斯滤波后的下采样结果(具有很强的背景模糊和边界弱化能力)
解决方法
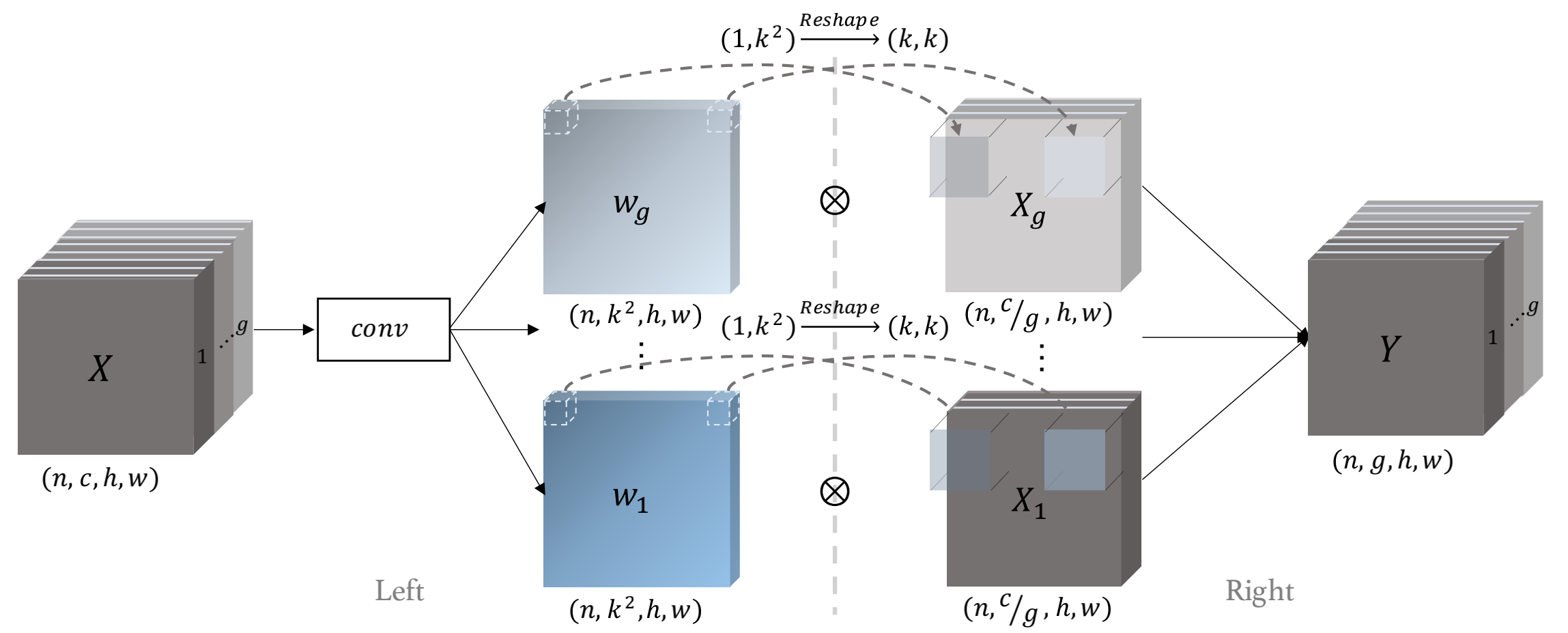
作者针对空间和通道分别生成低通滤波器用于缓解aliasing问题。基于空间自适应的低通滤波器就是一个简单的分组卷积操作:
在论文中也有提及,为了避免权重为负数,作者取了一个softmax操作。
之后对上面生成的权重进行分组再和输入进行一次卷积操作,最终输出Y:
具体可以看下作者放出来的代码:
1 | class Downsample_PASA_group_softmax(nn.Module): |
作者分别在分类,检测,分割任务上均有验证其有效性,均能提高1个点左右。具体实验结果可以看原论文,这里就不贴上来了。
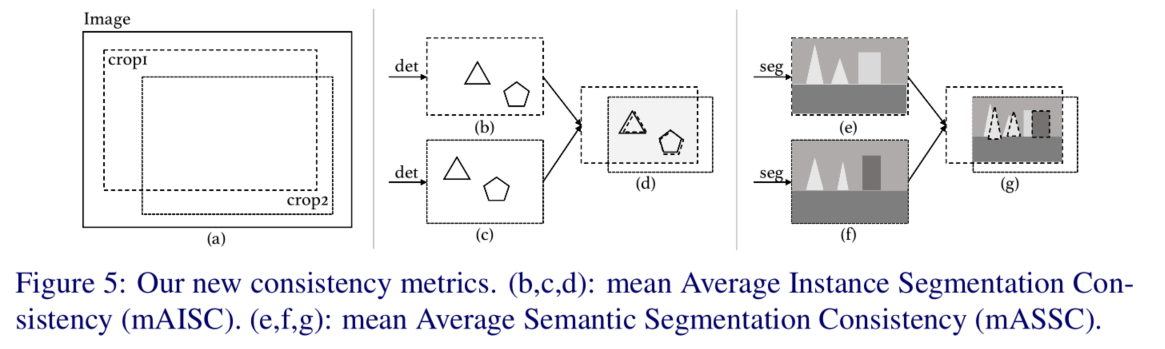
一致性指标
作者为了验证该方法的有效性,针对不同任务提出了一系列的一致性指标。比如针对分类任务的一致性指标计算如下:
X表示输入图像,$h{1}, w{1}, h{2}, w{2}$ 表示偏移量。$F(\cdot)$ 表示模型输出的top1的类别标签。具体代码实现可以看下面:
1 | ... |
1 | def agreement_correct(output0, output1, target): |
agreement_correct 是统计一致性指标的函数,具体可看出来统计方法是分别对输入图像随机偏移off0和off1 然后统计在该偏移量下,两者输出一致且和gt一致的比例。对于检测分割任务,作者也提出了相应的一致性指标计算方法:mAISC和mAISC这两个指标。具体计算如下图。