最近逛知乎上了解到低延迟目标检测这个方向,这个方向解决的是视觉任务工程化过程中存在一个痛点问题,如何解决延迟和误报的情况。拿视频中的目标检测问题来讲,我们通常会使用一个单帧检测器来检测视频中每一帧存在目标情况,静态上看可能会存在一些误检漏检情况,动态上表现为检测到的目标一闪一闪的情况,导致视觉效果很不友好。而低延迟目标检测的任务就是通过贝叶斯概率建模的方式融合多帧信息来解决这样的问题。
总体来说,对于任何检测任务来说,延迟和误报存在如下图的关系:
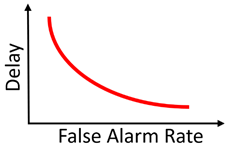
这个关系不难理解,不只是视觉问题,世间万物,更长的决策过程(delay)往往能带来更高的准确度,但是这个更长的决策过程也会带来更大的延迟。两者之间的平衡,对很多需要在线决策(online process)的系统来说非常重要。例如生物视觉,假定一个动物检测到掠食者就需要逃跑,如果追求低误报率,就要承担高延迟带来的风险,有可能检测到掠食者时为时已晚无法逃脱;如果追求低延迟,虽然相对安全,但是误报率高,有一点风吹草动就犹如惊弓之鸟。
低延迟检测思路
在视频物体检测中,如果使用上一帧的检测结果作为先验,将下一帧的检测结果输入贝叶斯框架,输出后验,那么总体来说,这个后验结果融合了两帧的信息,会比单帧更准。在这个思路下,理论上来说使用的帧数越多,检测越准。如以下单帧和多帧的对比:

但是同时更多的帧数会造成更长的延迟(延迟 := 物体被检测到的时刻 - 物体出现的时刻)。如何在保证物体检测精度的情况下,尽量降低延迟呢?我们参照QD理论进行如下建模:
假设一个物体在时刻$ts$出现在视频中,在 $t_e$离开视频,则这个物体的移动轨迹可以用时序上的一组检测框$b{ts,t_e}=(b{ts},b{ts+1},…,b{t_e})$表示。这样的一组检测框检测框序列,在目标追踪(Data association / tracking)领域被一些人称作tracklet。简单说,我们的算法目标是以低延迟判断检测框序列内是否含有物体。因此,我们称这样一组检测框序列为一个candidate。在quickest change detection框架下, 可以用如下似然比检验判断$t$时刻物体是否出现在该candidate内:
其中$Dt$代表一个单帧检测器在$I_t$上的检测结果,$T{0,i}$代表candidate中的内容从背景变为第类$i$物体(如行人)这一事件发生的时刻,$p_i(\bullet )=p(\bullet |l=l_i)$ 代表给定类别$i$的时候,$\bullet$ 事件发生的概率。由条件概率的独立性与,$p_i(\bullet |b_t)$类别$i$和检测框独$b_t$立,继而时序上各时刻检测结果的联合概率变成各时刻概率的连乘:
这里需要明确一下,上边公式中的条件概率并非简单的检测器输出的结果,具体如何计算$p$需要一套比较复杂的建模。由于这里只介绍低延迟检测的整体思路,关于$p$的建模待我有空时会附在文末,有兴趣的朋友可以直接去论文查阅。总之,我们可以对这个似然比取阈值,进行检测。阈值越高,结果越准,但是延迟越大,反之同理。由QD理论中递归算法(CuSum算法),我们可以对上述似然比取log,记为W。最终的检测流程可以参照如下框图。

整体流程为:
- (1)将已有但似然比未超过阈值的candidate做tracking进入下一帧;
- (2)在下一帧进行单帧检测,生成新的检测框,与前一帧tracking后的检测框合并到一起;
- (3)对这些candidate进行似然比检验,W超出阈值则输出检测结果,W小于零则去除该检测框,W大于零小于阈值则回到(1),进入下一帧。
这样一个检测框架,可以与任何单帧检测器结合。
代码实现
以上算法的具体实现过程,作者开源了一个简单的python实现,git地址在这里。这里主要看下核心的代码:
detection.py
1 | result = toolbox.initialize_result(num_cat) # 第一步,外循环,根据类别初始化result |
其中association.update的具体代码实现如下:
1 | import numpy as np |
其中,toolbox.combine_result的实现比较简单,对经过更新的轨迹信息和当前帧信息进行combine后经nms处理一下,代码如下:
1 | def combine_result(result, result_det, thre_nms): |
以上理论内容转自:计算机视觉中低延迟检测的相关理论和应用;