论文信息: Generalized Focal Loss && Generalized Focal Loss V2
代码链接: https://github.com/implus/GFocal && https://github.com/implus/GFocalV2
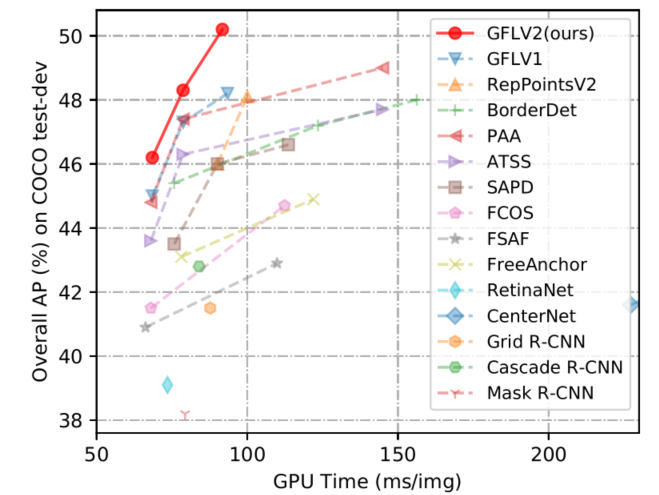
整体信息:这倆篇论文都是出自南理工的李翔,从定位质量估计和边框表示的角度上对现有检测方法进行改进。在任意one-stage检测器上都能涨1-2点。GFLv1解决的是目前检测方法存在的两个问题:1)在训练和推理的时候,分类和质量估计的不一致性;2)狄拉克分布针对复杂场景下(模糊和不确定性边界)存在不灵活的问题。GFLv2是在v1的基础上,进一步地,使用概率分布的方式评估检测框质量,相比v1更有效,v2在ATSS上可以无痛涨点2-3点。
GFLv1
方法的出发点主要是解决俩个问题:1)classification score 和 IoU/centerness score 训练测试不一致;2)bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty;
问题1:训练测试不一致性
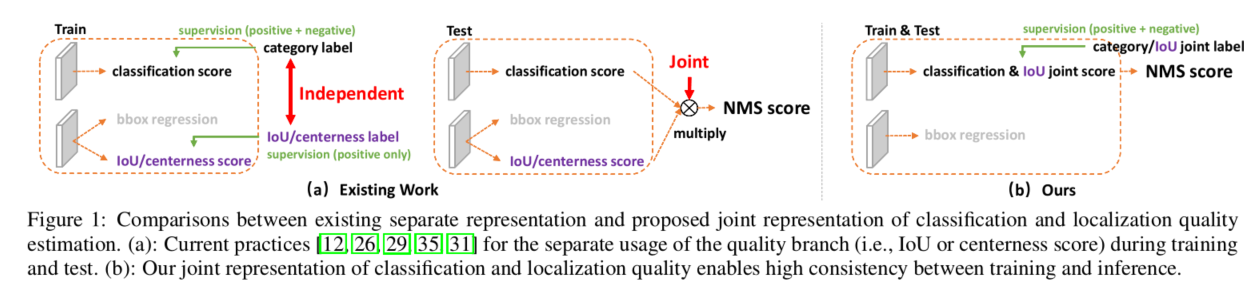
不一致主要体先在俩方面:
- 用法不一致。训练的时候,分类和质量估计各自训记几个儿的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap;
- 对象不一致。借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计(回归)通常就只针对正样本训练;
问题2:bbox regression不灵活,无法建模复杂场景
在复杂场景中,边界框的表示具有很强的不确定性,而现有的框回归本质都是建模了非常单一的狄拉克分布,非常不flexible。我们希望用一种general的分布去建模边界框的表示。问题二如图所示(比如被水模糊掉的滑板,以及严重遮挡的大象):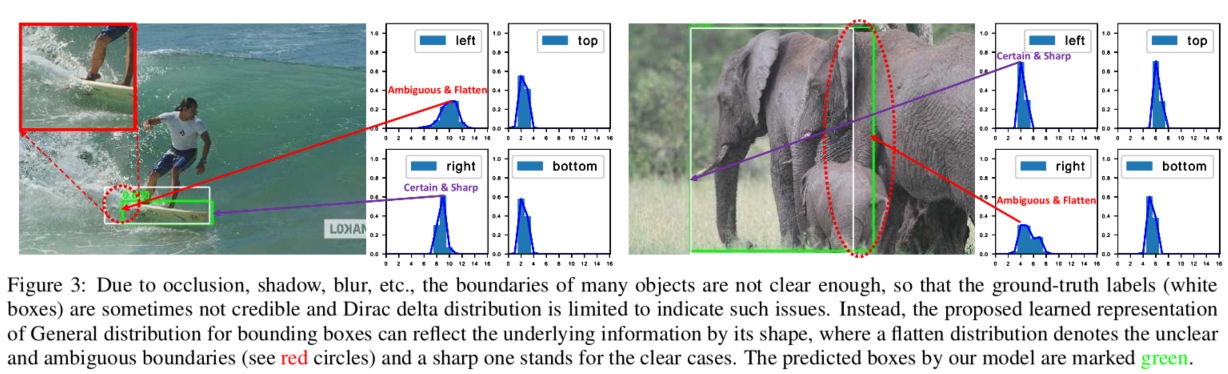
解决方法:
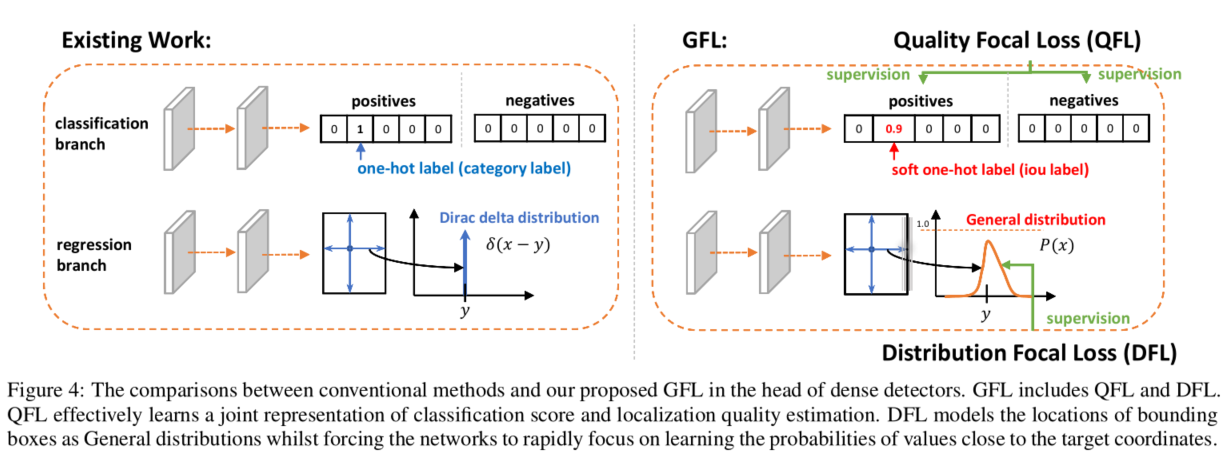
具体地,
分类
在分类分支上不再使用one-hot型类别标签监督,而是使用soft-one-hot 标签,标签值使用地iou值;如此,完美的将类别和位置信息结合利用起来了;传统地交叉熵、focal loss只能处理离散标签;因此作者在focal loss基础上提出 Quality Focal Loss,具体形式如下:
回归
考虑到真实的分布通常不会距离标注的位置太远,作者又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。Distribution Focal Loss:
其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。简单来讲,就是预测目标框边界附近地n个位置地概率值,然后基于概率值和n个位置进行加权,得到目标框边界值;目标的四个边框均采用上述操作,然后基于组合的目标框使用GIOU loss进行优化。
损失函数
上面是训练loss函数,第一部分是分类分支的QFL;第二部分是回归分支的GIOU loss和Distribution Focal Loss;
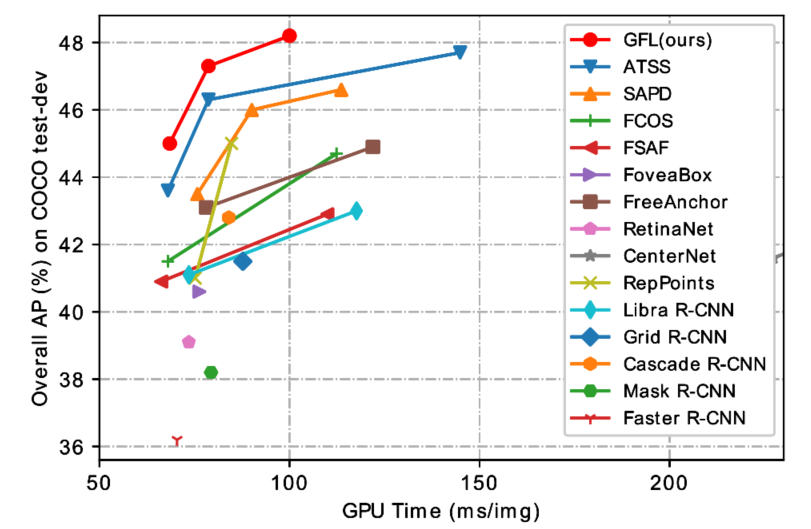
实验结果
GFLv2
问题:在GFLv1中,作者提出了对边界框进行一个一般化的分布表示建模。有了这个可以学习的表示之后,基本上那些非常清晰明确的边界,它的分布都很尖锐;而模糊定义不清的边界它们学习到的分布基本上会平下来,而且有的时候还经常出现双峰的情况。作者为了充分利用这分布,提出了GFLv2,利用分布形状的统计量去知道最终最终定位质量的估计。具体网络结构如下: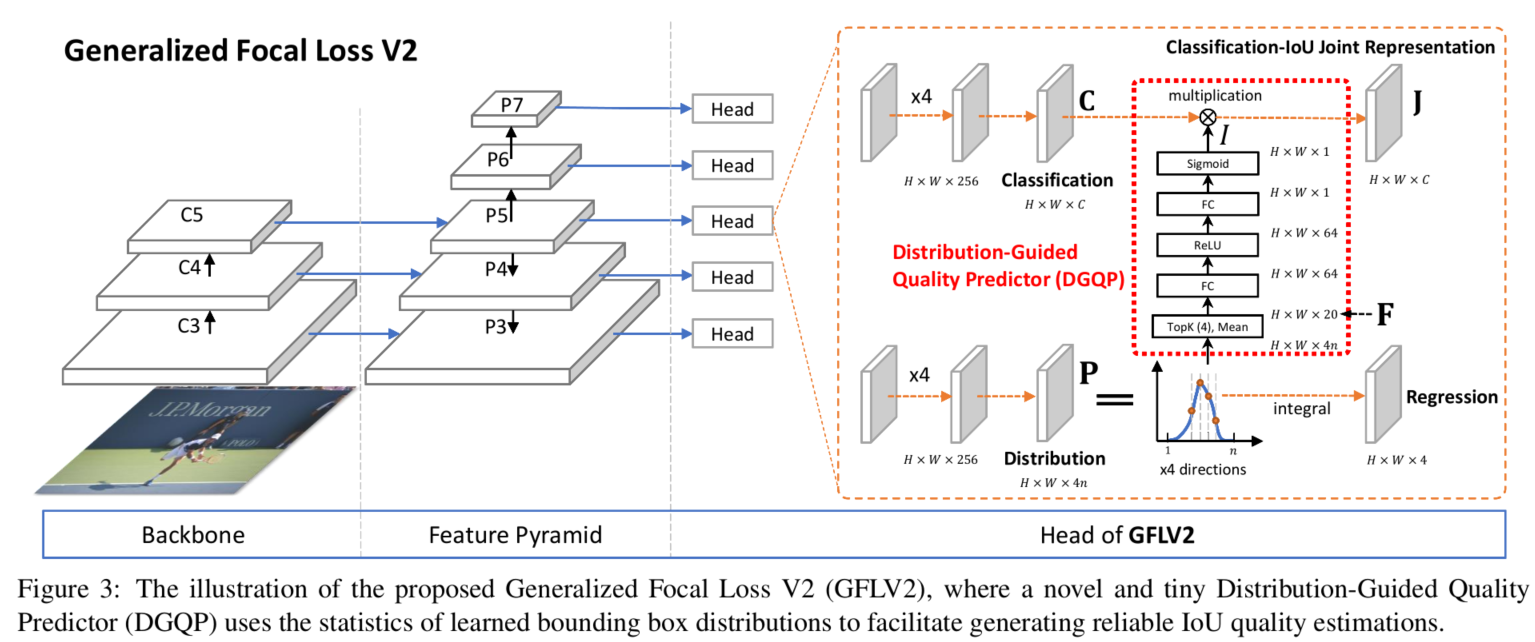
核心思路
直接取学习到的分布(分布是用离散化的多个和为1的回归数值表示的,详情参考GFLV1)的Topk数值。其实理解起来也不难,因为所有数值和为1,如果分布非常尖锐的话,Topk这几个数通常就会很大;反之Topk就会比较小。选择Topk还有一个重要的原因就是它可以使得我们的特征与对象的scale尽可能无关,如下图所示: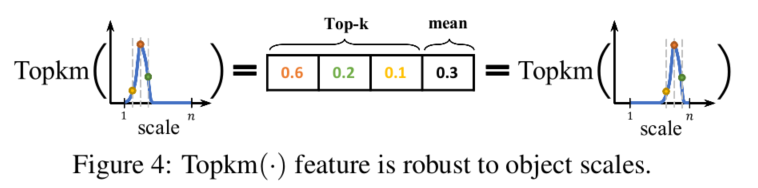
简单来说就是长得差不多形状的分布要出差不多结果的数值,不管它峰值时落在小scale还是大scale。我们把4条边的分布的Topk concat在一起形成一个维度非常低的输入特征向量(可能只有10+或20+),用这个向量再接一个非常小的fc层(通常维度为32、64),最后再变成一个Sigmoid之后的scalar乘到原来的分类表征中。具体model参考上图,其中红色框就是比GFLV1多出来的Distribution-Guided Quality Predictor部分,这也就是本文的核心。
实验结果