论文信息:He Kaiming ,ICCV2017 best paper,2017 coco object detection,2017 coco instance segmentation winner.
整体框架:mask rcnn 在Faster RCNN的基础上,使用FCN来增加一个mask branch,从而解决instance segmentation问题,而且这个还能从一点程度上提高object detection的检测效果。此外,该网络框架通用性强,使用灵活,通过关键点分支,还可以实现关键点检测。
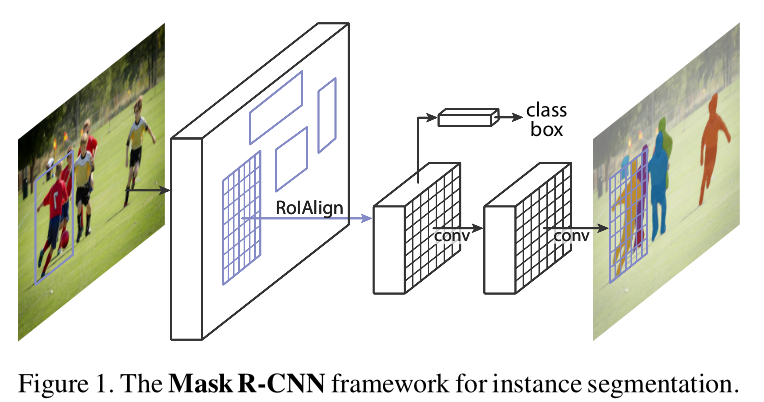
分割主要分为两种:Semantic segmentation和Instance segmentation。前者是语义分割,用于对不同种类的目标进行分割,区分的仅仅是不同种类之间的差异;后者是实例分割,是在前者的基础上,不仅仅要区分不同种类之前的差异,还要区分开同种类目标的不同个体。如下如所示

如果认为instance segmentation=detection +semantic segmentation,就会产生一些错误,比如图中person3和person4的交集部分都是属于“人”,那么该如何区分交集部分的像素是属于person3还是person4?现有大多数instance segmentation 算法都很难完全解决这问题,无论是COCO2015(MNC)还是COCO2016(FCIS)实例分割的winner都是很难完全解决这个问题。而mask rcnn的提出就是解决instance segmentation的这个问题。
2.Faster RCNN与Mask RCNN的区别
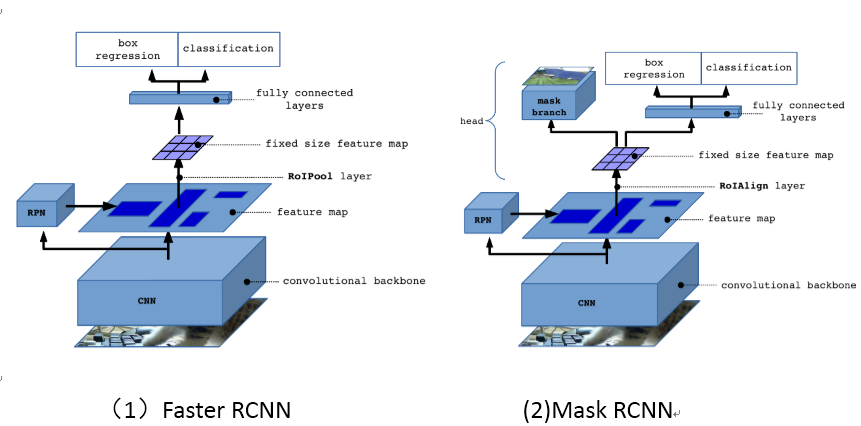
从上图可以看出有两个区别:(1)RoIPool layer 和RoIAlign layer;(2)RoI特征前者用于分类+回归,而后者用于分类+回归+mask分割;
至于RoIPool和RoIAlign的区别,有时间再细讲。总之,RoIAlign的提出就是为了解决RoIPool的两次量化操作导致的不匹配问题(misalignment),而这个是直接影响分割的效果。
3.网络结构
从上图(2)可以看出,mask rcnn主要有两部分组成:backbone+head。
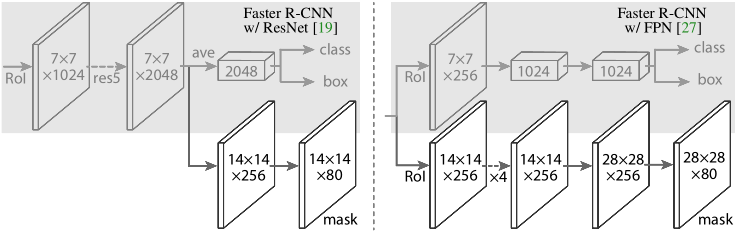
上图是作者给出的基于两个不同backbone的mask rcnn网络的head部分。前者是基于ResNet-C4,后者是基于FPN。Mask branch分支部分都是通过FCN实现的。之所以用FCN去实现,是因为使用FCN不会像FC层那样会丢失空间信息(spatial
layout),而且这样可以避免使用FC带来的参数的增加。
注:14*14*80中,80指的是类别,因为在物体检测时已经得到类别,所以直接选择对应类别的那个14*14特征图,然后resize到检测box尺寸就是最终结果。
3.训练
Stage1 训练RPN:这个金额训练Faster RCNN是一样的;
Loss function= binary loss+ box smooth L1 loss
Stage2 训练Mask RCNN:
Loss function= class loss + box loss + mask loss
注:每个ROI都会预测K个m*m大小的mask输出。M通常等于14或28,K是类别个数。使用sigmoid作为激活函数,并没有使用sofmax,这需要注意。训练的时候,只把第k个m*m的预测的mask加入到loss中去。
Mask loss中使用的是sigmoid(binary cross entropy loss),为什么不使用softmax?(像传统的FCN那样)
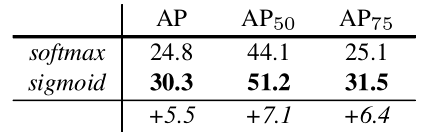
作者通过实验对比发现,sigmoid的结果比softmax结果大约高5.5AP。
4.实验结果

5.通用性
此外mask rcnn除了能产生mask之外,也可以用于检测人体关键点,只需要增加一个人体关键点的分支就OK。
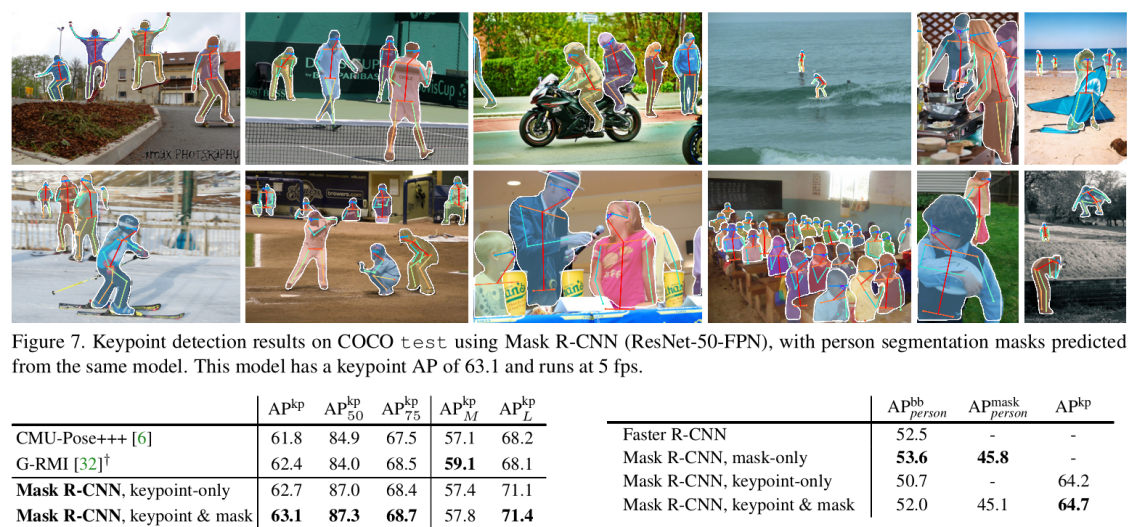
整个文章的大致内容就这些,上面只是蜻蜓点水的随便的介绍了mask rcnn的内容。具体细节可以去参考原文。
6.最后
这周使用自己的数据集训练,总的实验结果来说还是不错的。下面是我的实验结果和mask rcnn的实验结果。
我的实验结果


从右图可以看出,最右边分割的时候漏掉了一个商品。也就是说在检测小目标时MNC还是存在一点的局限性的。
Mask RCNN的结果


不得不说,mask rcnn太强大了。