论文信息:CVPR2018, ETH Zurich Liming Wang (TSN作者)
代码链接:https://github.com/wanglimin/ARTNet
论文概述:由于训练two-stream网络计算成本大比较耗时,尤其是提取optical flow部分,3D卷积不用提取optical flow,直接对RGB volume输入提取spatial-temporal特征,但效果差于two-stream法,作者基于此,(1)提出了一种SMART block,这个模块以一种separate 方式提取volume 中的appearanceinformation和relation(motion) information。;(2)在C3D-ResNet的基础上通过stack这种SMART block构建了ARTNet;(3)在数据集上刷新了仅使用RGB输入的行为识别准确率。
框架对比:
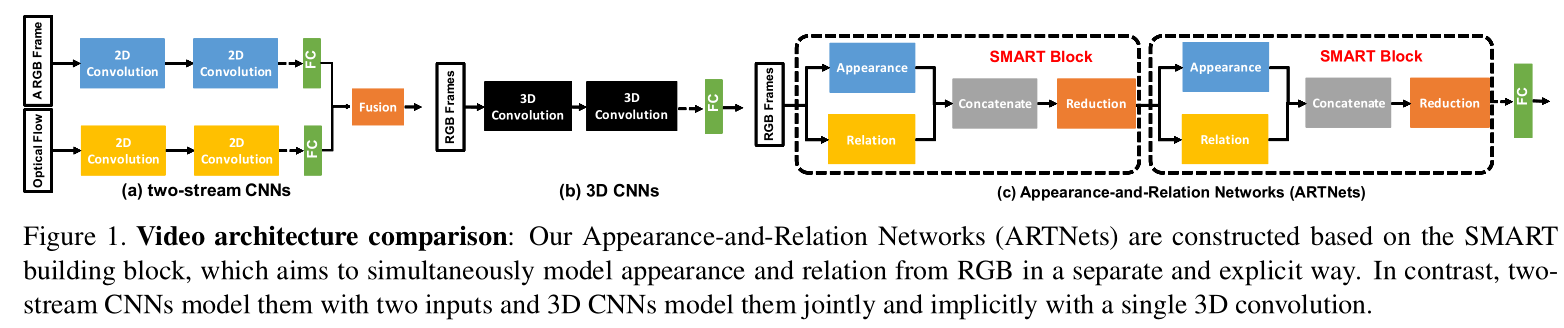
从上图可以看出,ARTNet是对前两者在结构上的一个很好的整合。
SMART block
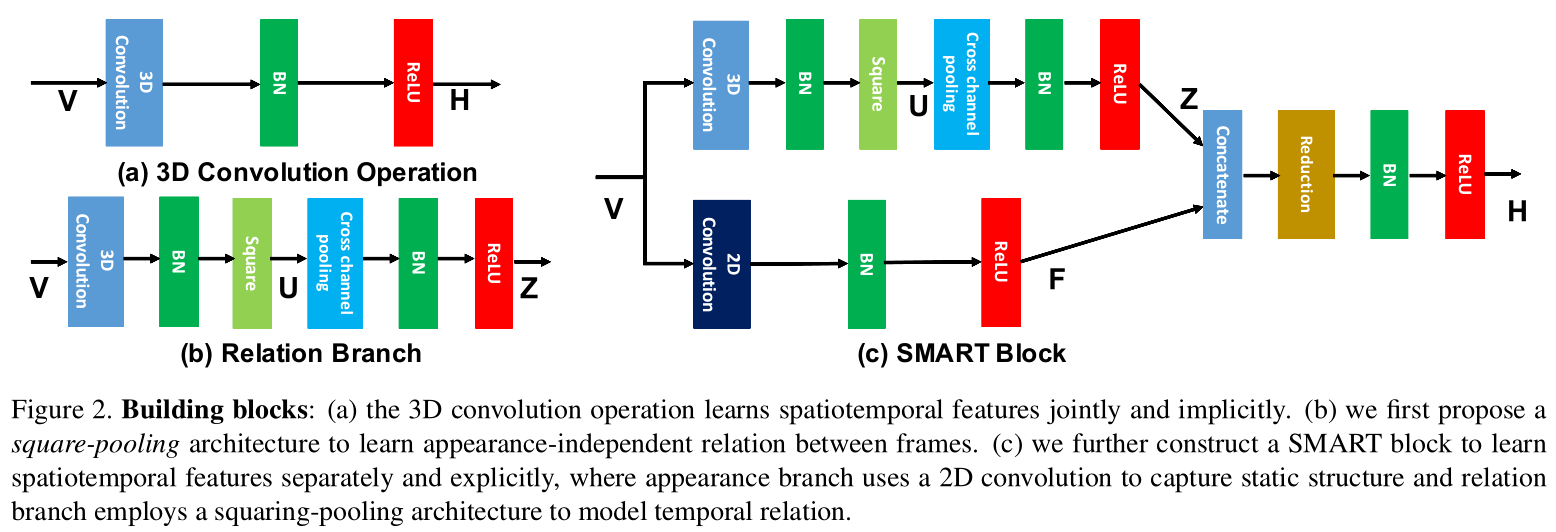
SMART block由两个branch组成:appearance branch 和relation branch。前者直接使用2Dconvolution 对每个frame提取spatial information;后者则是使用3D convolution +square pooling 的结构对multi-frame提取temporal dynamics。最后对两个branch进行concatenation。SMART block 输入是volume,输出依旧是volume。 Cross channel pooling和 采用1*1*1 convolution 实现。注:最后只要设置成同样的W,H,T,C,就可以进行concat。
实验结果:
由于采用了3D卷积,所以作者直接在C3D-ResNet上添加SMART进行实验。
Network
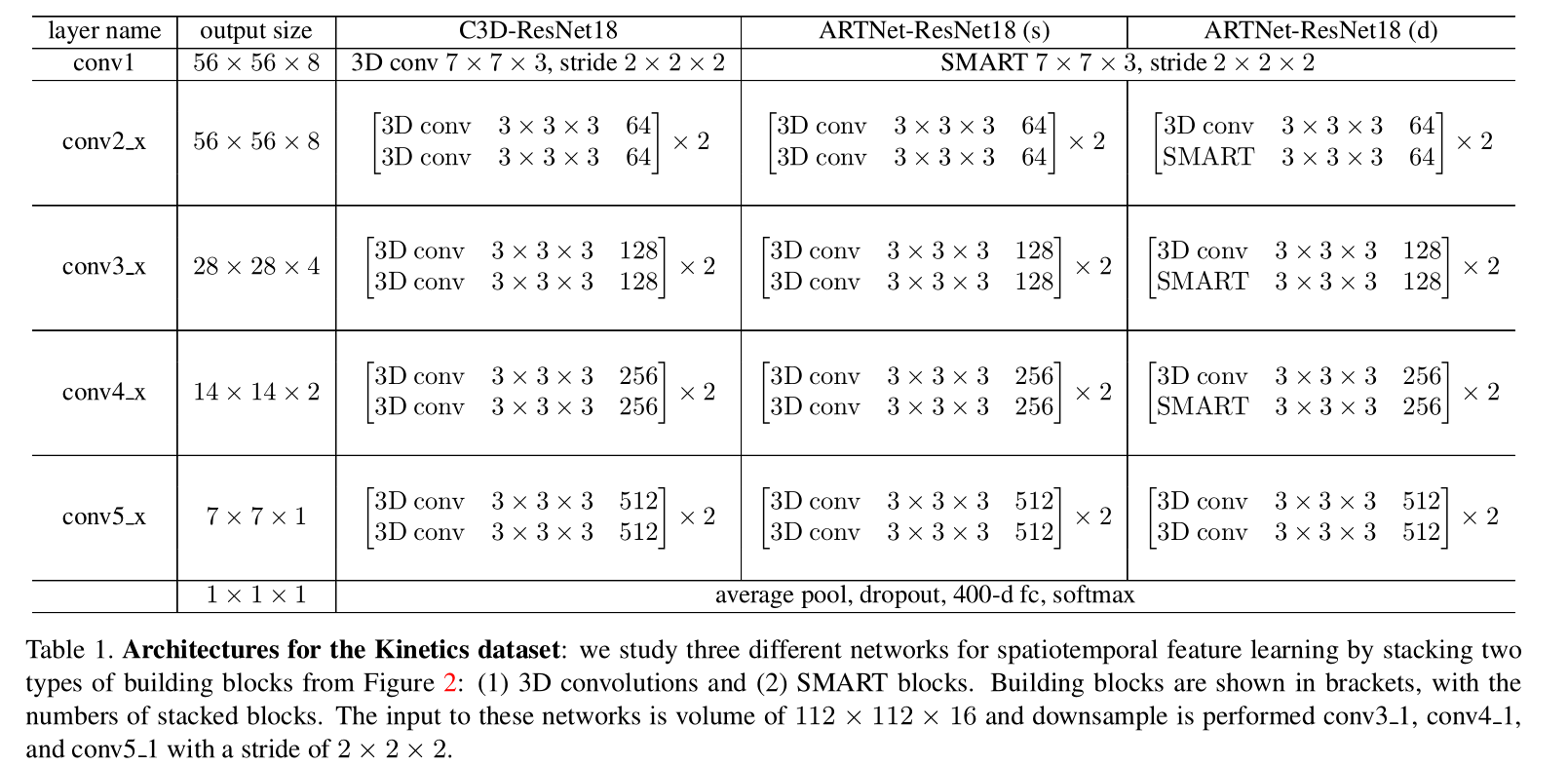
Training : Kinetics ,train from scratch。Testing:25 clips,每个clips有16 frame.
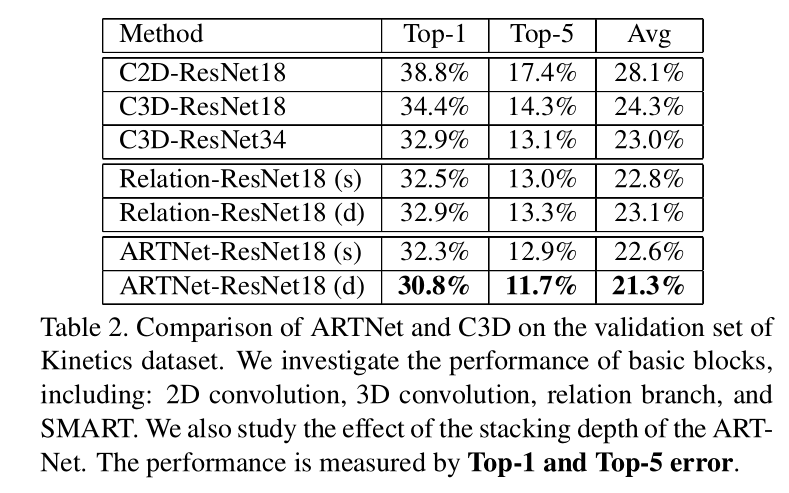
从测试结果来看,添加SMART 之后,performance都有不同程度的提高。而且,这里为了证明performance的提高并不是因为network 的depth的加深,作者还使用ARTNet-ResNet18和C3D-ResNet34比较可以看出,并不是由于网络加深而带来的效果的提升。作者还和其他state-of-the-art进行比较,
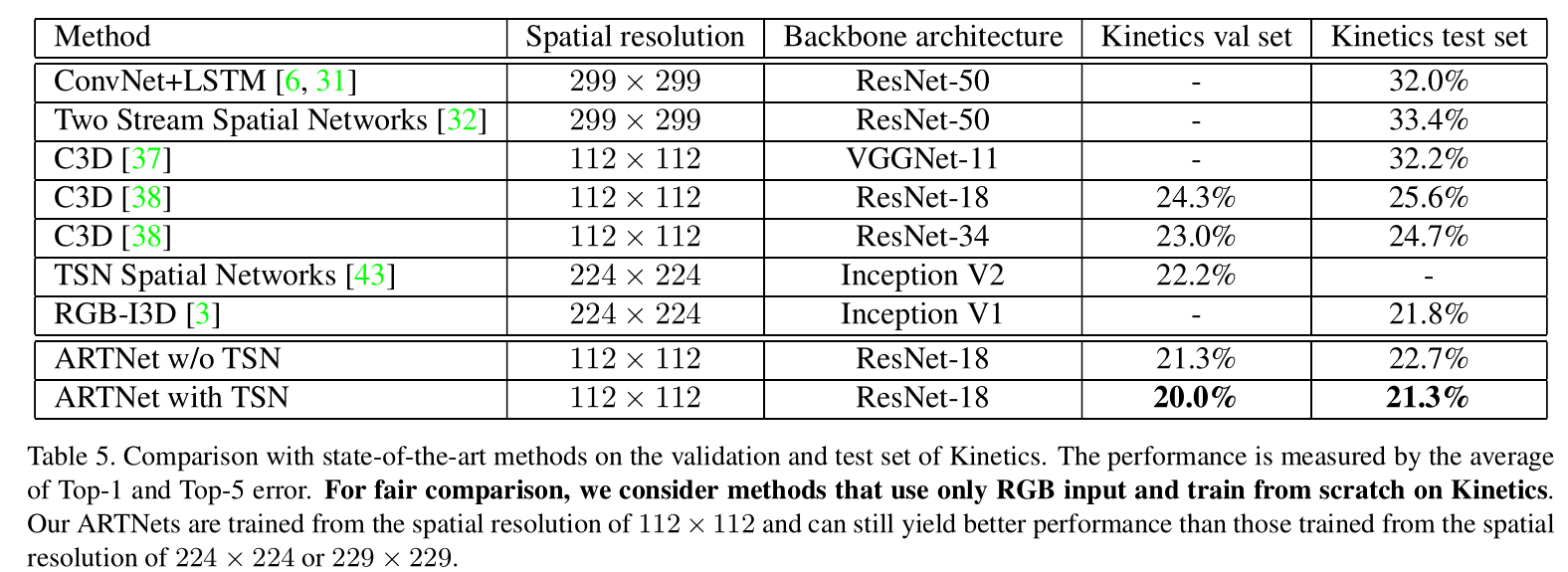
可以看出在仅仅只有RGB输入的时候,实验效果是优于所有其他方法的,比如I3D。
Generalization
为了测试网络的generalization ,作者还在action recognition数据集:UCF101和HMDB51上测试,下面是测试结果。
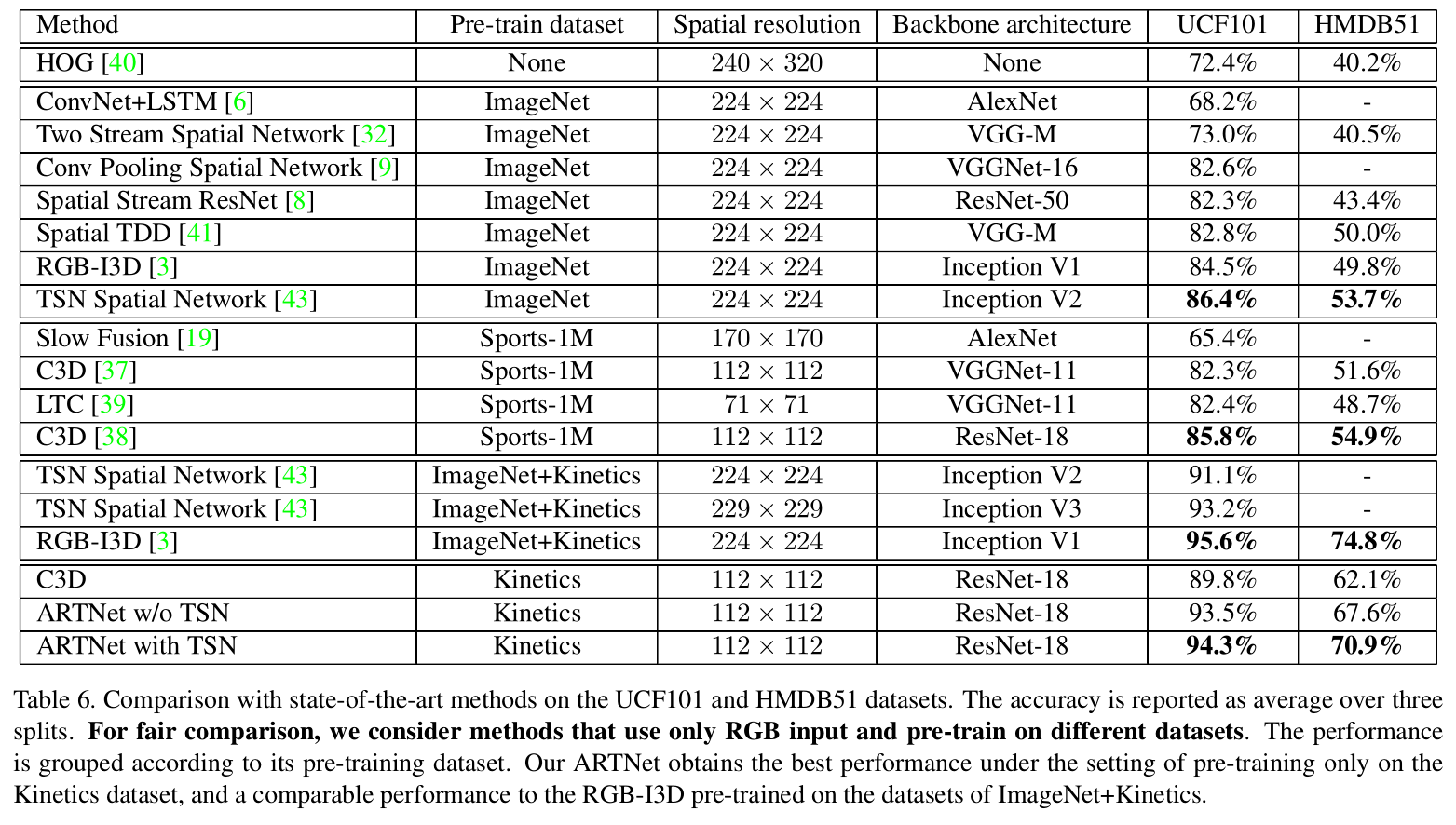
从实验结果可以看出,ARTNet和C3D比,在UCF101上提升了3.7%,在HMDB51上提升了5.5%。虽然比RGB-I3D相比要差点,但是ARTNet fine tuning 的数据集只用了Kinetics。
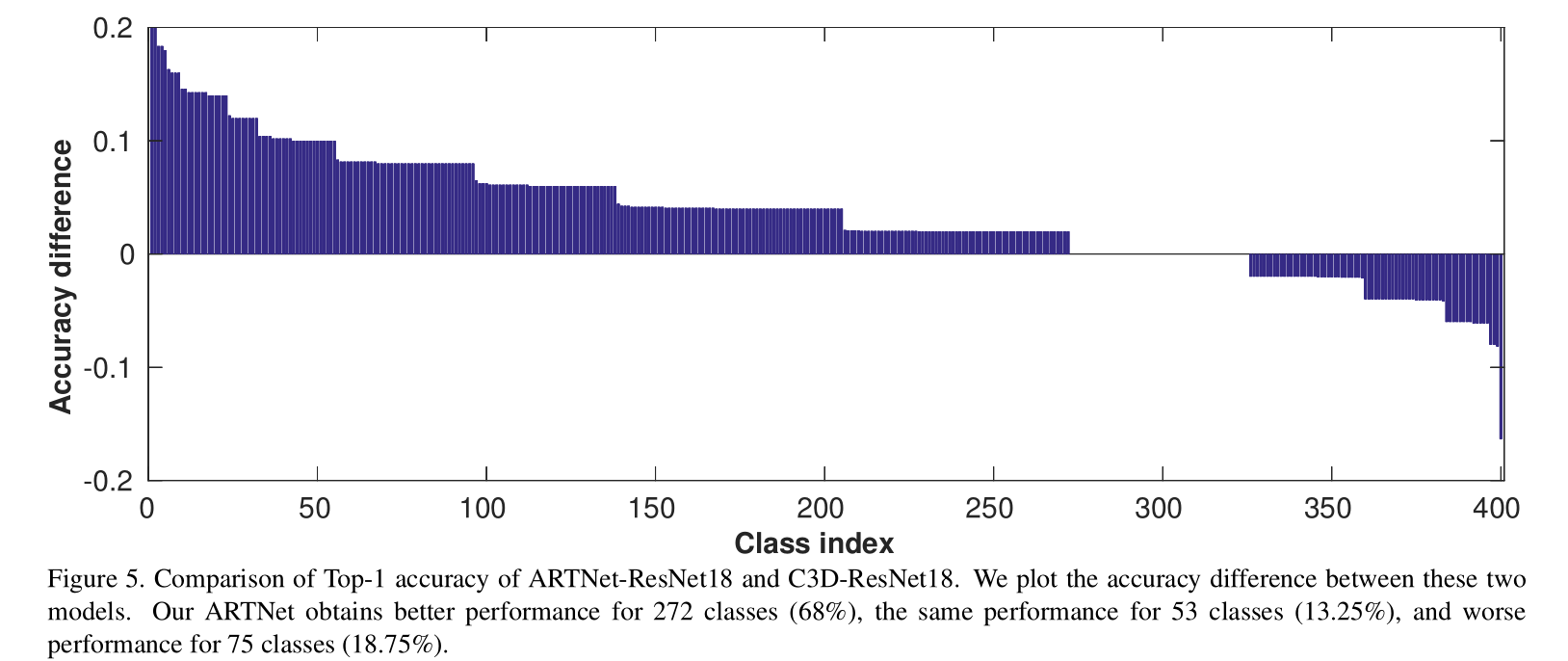
从上面在Kinetics上测试结果对比可以看出,68%的类上的测试结果是优于C3D的。