在sora的技术报告中提到将视觉数据转换为patches,这个不得不提及ViT这篇开创之作,它便是通过将图像划分为多个patch,然后映射成token序列,输入到transformer完成一些视觉任务,但是,在划分patch时通常需要将图像调整为固定的分辨率进行处理,这种方法在某种程度上是次优的。NaViT这篇论文就是解决不同分辨率输入的问题。Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution,这篇论文是发表在NeuralPS2023上的一篇论文,Google DeepMind的工作,下面详细介绍NaViT工作原理。
NaViT
title:Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
author:Mostafa Dehghani, Basil Mustafa, Josip Djolonga,and etc.
NaViT是一种新的视觉Transformer,通过在训练过程中使用序列打包来处理任意分辨率和宽高比的输入,从而在训练效率、模型适应性和推理灵活性方面超越了传统的Vision Transformer。
- Randomly sampling resolutions at training time significantly reduces training cost. 显著降低训练成本
- NaViT results in high performance across a wide range of resolutions, enabling smooth cost-performance trade-off at inference time, and can be adapted with less cost to new tasks. 取得更好的效果,而且以更小的代价适用其他任务上
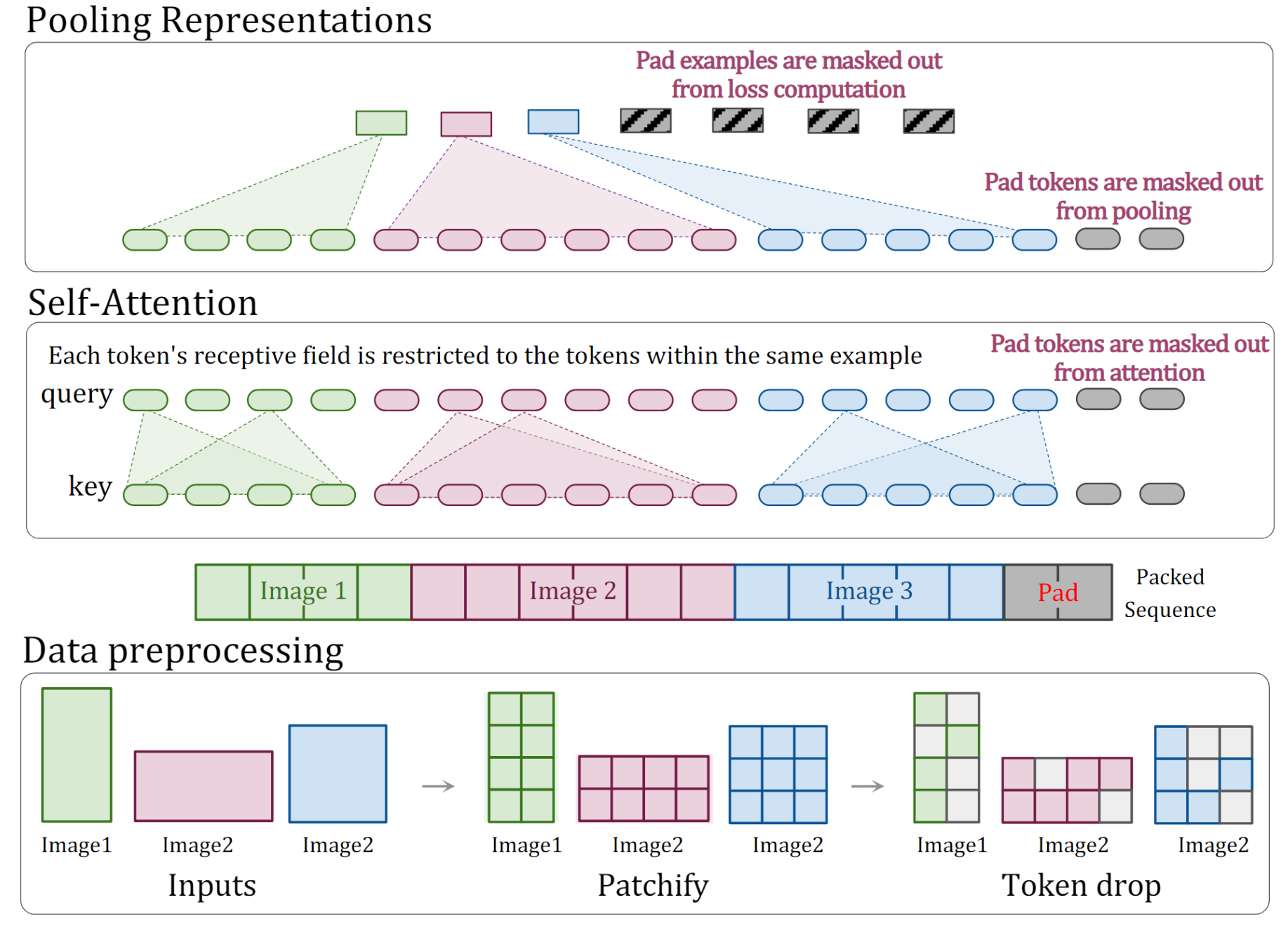
上述过程,展示了NaViT在处理任意分辨率的方法,Data preprocessing阶段,先将不同分辨率图片进行patch处理,再采用了token drop操作随机丢弃一些patch,类似dropout,目的是加速训练;预处理完后,把三张图片生成的patches拉平为一个序列,不够的地方用pad填充;在Self-Attention阶段,使用attention mask技术防止图片之间存在信息交换;
Architectural changes
NaViT 的架构是建立在 ViT的基础上的,但是又做些修改:
- Masked self attention and masked pooling,防止示例相互关注,引入了额外的attention mask;
- Factorized & fractional positional embeddings,支持可变宽高比并很容易外推到没见过的图片分辨率;
Training changes
在训练NaViT时,也引入了一些新的trick:
- Continuous Token dropping,packing enables continuous token dropping, whereby the token dropping rate can be varied per-image.
- Resolution sampling. it allows mixed-resolution training by sampling from a distribution of image sizes, while retaining each images’ original aspect ratio.
Improved training efficiency and performance
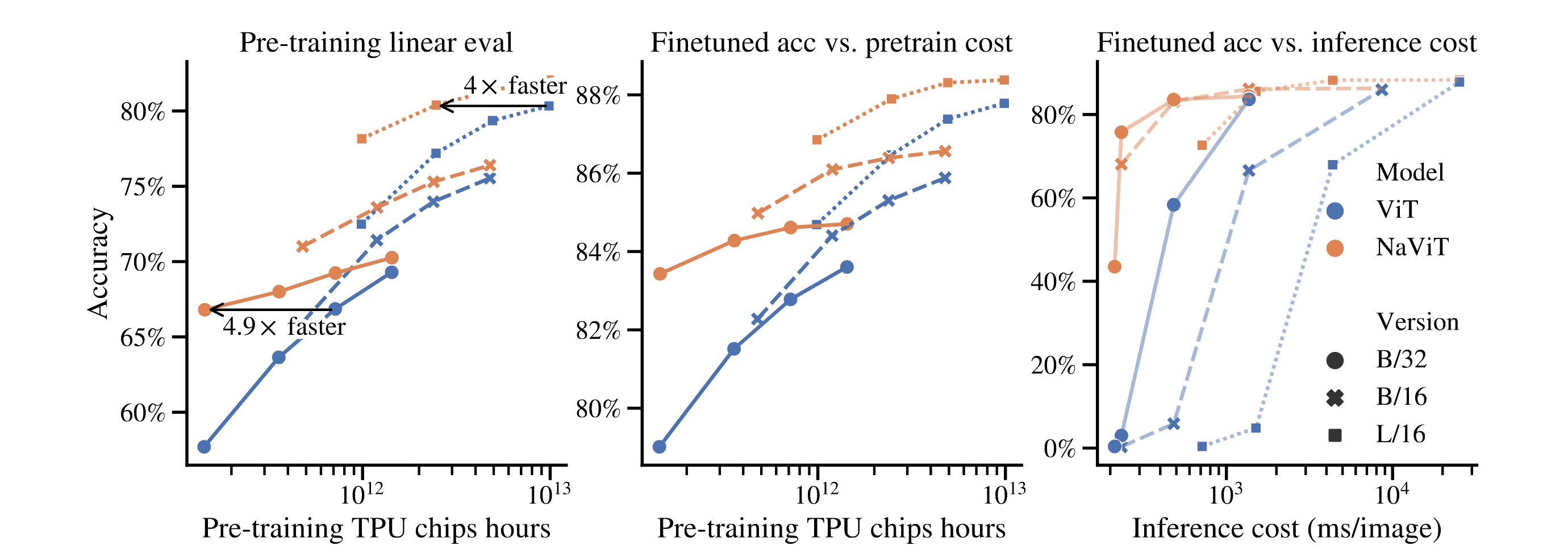
从实验结果上看,NaViT相比于ViT,训练速度是ViT的四倍,而且性能更好,推理速度也更快;