平时做的都些检测相关的项目,因此对于各类检测框架使用较多,以及一些不知名的repo都有用过,平时接触的都是业务项目,很少去认真的看一个repo中算法的框架设计,最近项目处于交付阶段,主要是客户和平台开发人员对界面的问题。趁有空mmdetection的代码重新看了一遍,顺便做了一些笔记。
组件设计
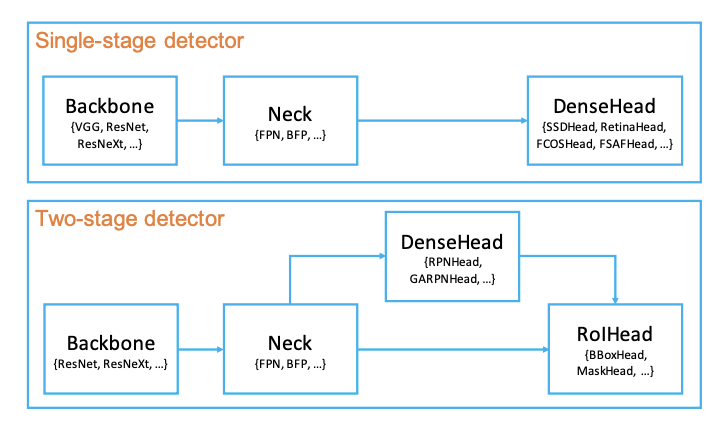
- BackBone: 特征提取骨架网络,ResNet,ResneXt,ssd_vgg, hrnet 等。
- Neck: 连接骨架和头部. 多层级特征融合,FPN,BFP,PAFPN 等。
- DenseHead: 处理特征图上的密集框部分, 主要分 AnchorHead。AnchorFreeHead 两大类,分别有 RPNHead, SSDHead,RetinaHead 和 FCOSHead 等。
- RoIHead (BBoxHead/MaskHead): 在特征图上对 roi 做类别分类或位置回归等 (1.x)。
- ROIHead:bbox 或 mask 的 roi_extractor+head(2.0, 合并了 extractor 和 head)
- SingleStage: BackBone + Neck + DenseHead
- TwoStage: BackBone + Neck + DenseHead + RoIHead(2.0)
结构设计
代码结构
configs 网络组件结构等配置信息
tools: 训练和测试的最终包装和一些实用脚本
mmdet:
- apis: 分布式环境设定 (1.x,2.0 移植到 mmcv), 推断, 测试, 训练基础代码;
- core: anchor 生成,bbox,mask 编解码, 变换, 标签锚定, 采样等, 模型评估, 加速, 优化器,后处理;
- datasets:coco,voc 等数据类, 数据 pipelines 的统一格式, 数据增强,数据采样;
- models: 模型组件 (backbone,head,loss,neck),采用注册和组合构建的形式完成模型搭建
- ops: 优化加速代码, 包括 nms,roialign,dcn,masked_conv,focal_loss 等
总体逻辑
从 tools/train.py 中能看到整体可分如下 4 个步骤:
1.mmcv.Config.fromfile 从配置文件解析配置信息, 并做适当更新, 包括环境搜集,预加载模型文件, 分布式设置,日志记录等;
2.mmdet.models 中的 build_detector 根据配置信息构造模型 ;
- 2.1 build 系列函数调用 build_from_cfg 函数, 按 type 关键字从注册表中获取相应的对象, 对象的具名参数在注册文件中赋值;
- 2.2 registr.py 放置了模型的组件注册器。其中注册器的 registermodule 成员函数是一个装饰器功能函数,在具体的类对象 A 头上装饰 @X.register _module,并同时在 A 对象所在包的初始化文件中调用 A,即可将 A 保存到 registry.module_dict 中, 完成注册;
- 2.3 目前包含 BACKBONES,NECKS,ROIEXTRACTORS,SHARED HEADS,HEADS,LOSSES,DETECTORS 七个模型相关注册器,另外还有数据类,优化器等注册器;
3.build_dataset 根据配置信息获取数据类;
- 3.1 coco,cityscapes,voc,deepfasion,lvis,wider_face 等数据 (数据类扩展见后续例子)。
4.train_detector 模型训练流程:
- 4.1数据 loader 化, 模型分布式化,优化器选取
- 4.2 进入 runner 训练流程 (来自 mmcv 库,采用 hook 方式,整合了 pytorch 训练流程)
- 4.3 训练 pipelines 具体细节见后续展开。
后续说说配置文件,注册机制和训练逻辑。