论文信息:Object-Contextual Representations for Semantic Segmentation
代码链接:https://github.com/HRNet/HRNet-Semantic-Segmentation/tree/HRNet-OCR
整体信息:这是CAS和MSRA合作发表在ECCV2020上有关语义分割的论文,该论文中提出的OCRNet在2019年7月和2020年1月的 Cityscapes leaderboard 提交结果中都取得了语义分割任务第一名的成绩。对于语义分割任务,获取上下文信息是至关重要的。左图所示方法利用ASPP获取红色像素点周围的上下文信息,可以看到,采样的像素点包含人、背景和汽车三个类,并没有加以区分。而本文提出的Object Contextual Representations (OCR)方法直接将红色像素周围蓝色区域(汽车)的像素作为上下文信息。即图中的Object context。

在语义分割中,单个像素无法判断属于某一个物体,因此给予足够多地上下文信息至关重要。OCRNet的核心在于构建上下文信息时显式地增强了来自同一类物体地像素贡献。
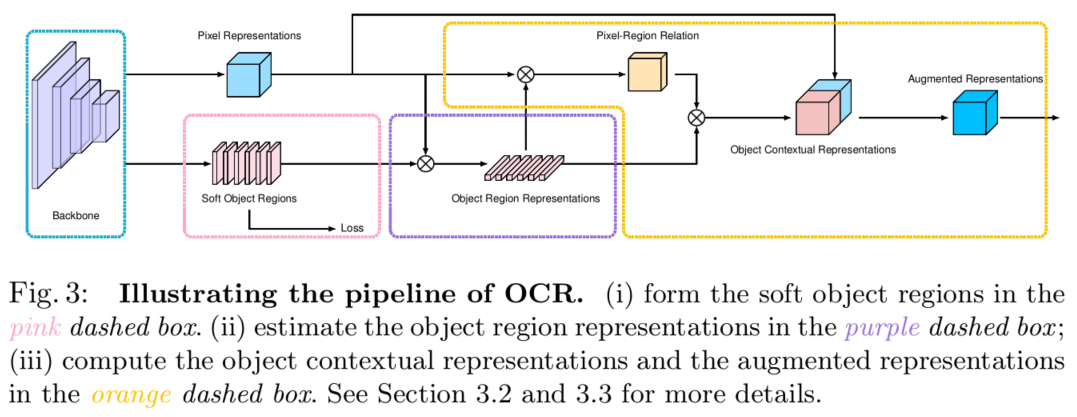
具体做法:
第一步:先通过有监督方法获得K个软目标区域(K soft object regions)表示;同时利用3x3卷积等操作获得整体的像素表示(pixel representations)
第二部:通过聚合K个软目标区域(K soft object regions)和整体像素表示(pixel representations)得到目标区域表示(Object Region Representations)
第三部:通过聚合K个目标区域并考虑它们与所有像素的关系,来加强每个像素的表示。得到Object Contextual Representations. 即文中的$y_i$,然后聚合$y_i$和$x_i$ 得到最终地增强像素表示Augmented Representations,即$z_i$ .
更为通俗易懂地如下图所示:
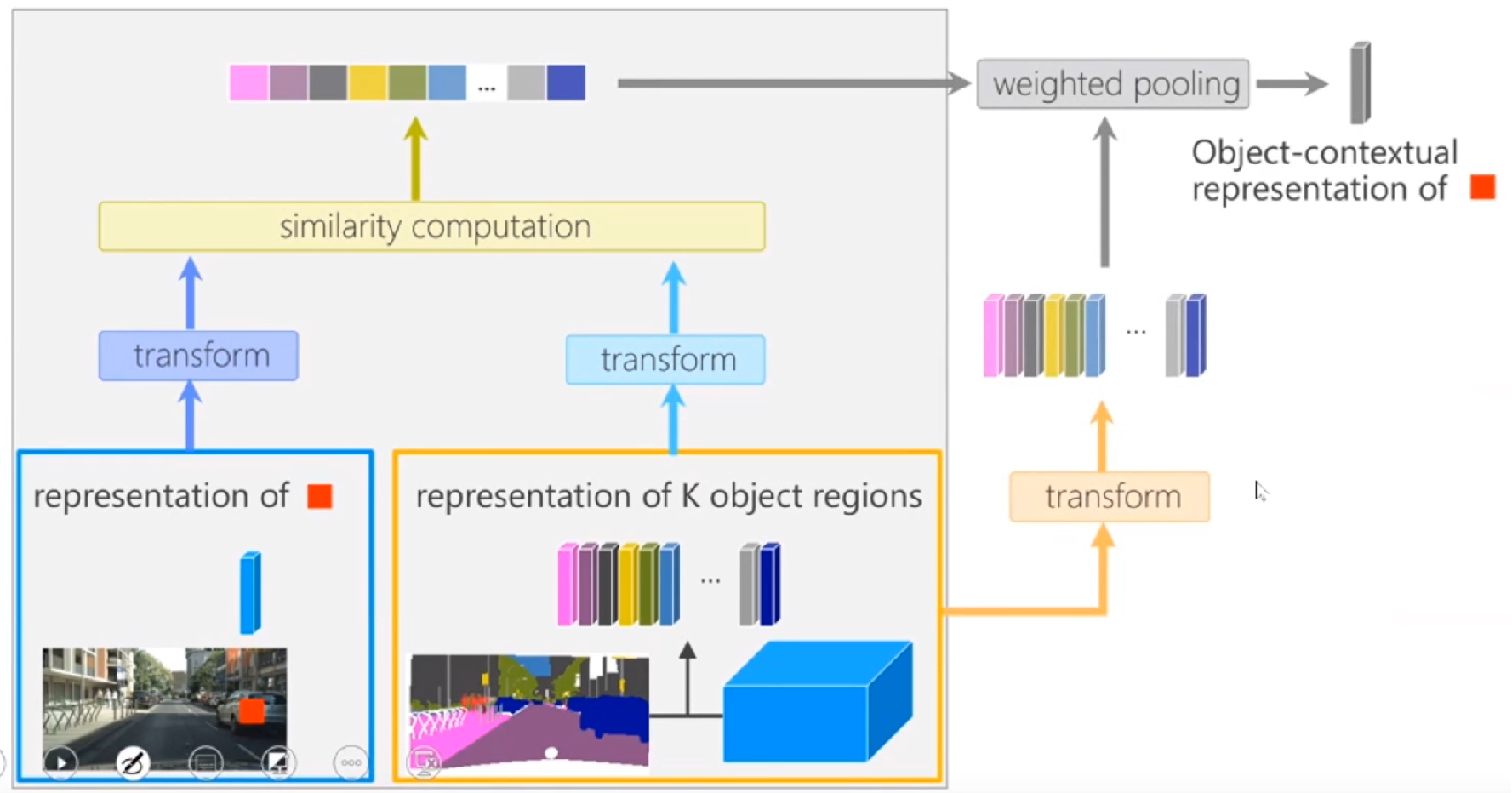
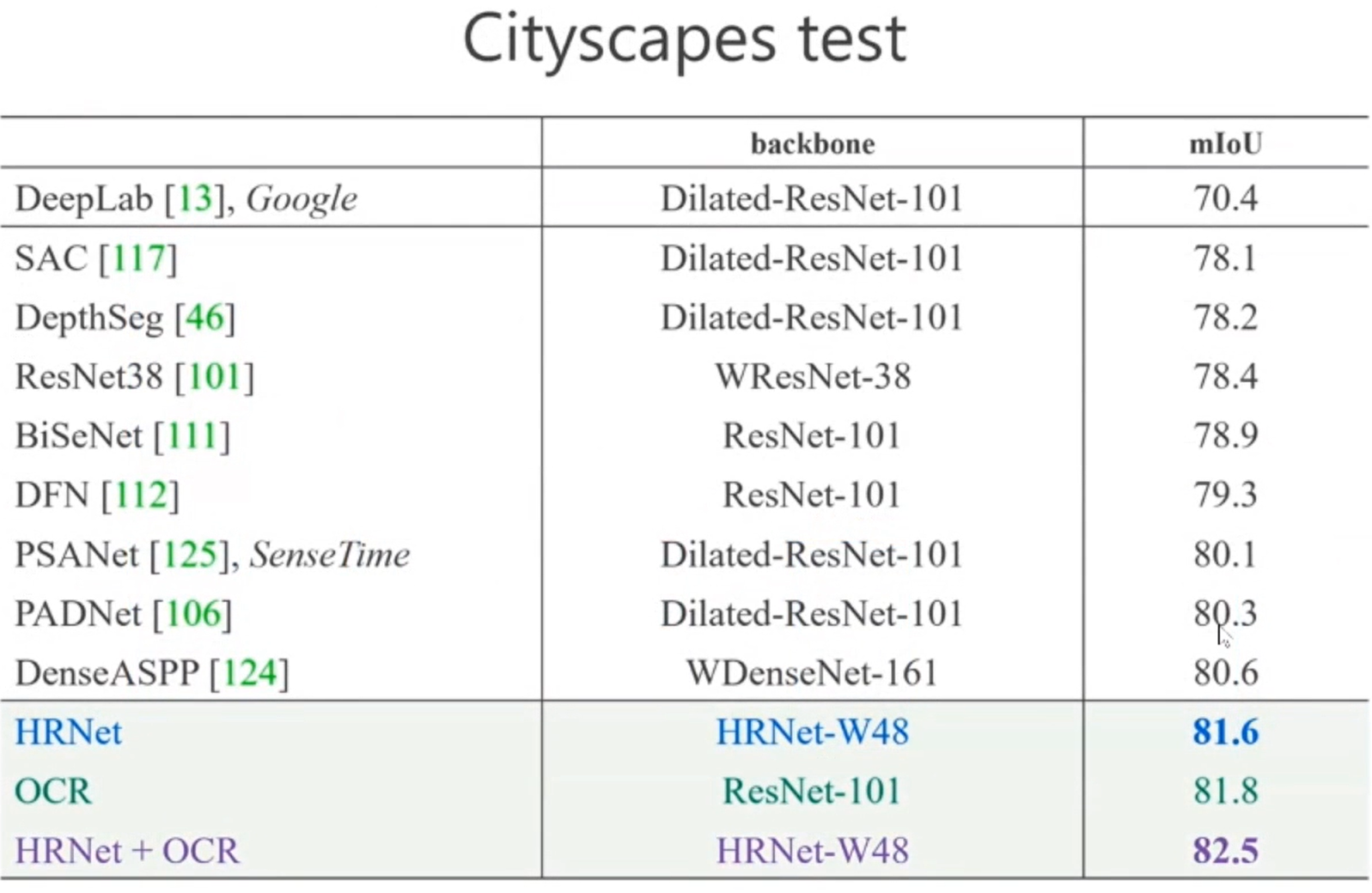
这个方法非常容易解释,看上去也比较有道理,最终在cityscapes上可以达到 82.5%,这是目前的SOTA。
其实,仔细观察,一个有意思的时,上述过程就是一个计算attention的过程。