上午看了一下Bag of Tricks for Image Classification with Convolutional Neural Networks这篇文章,该文提到了许多关于如何提升CNN性能的trick。trick在CNN中起着非常重要的作用,然而很少有文章详细地介绍这些trick的使用。而这篇文章则对一些常用的trick做了详尽的介绍以及使用trick前后带来的对比,可以说是满满的干货,对应的代码实现,在这里。文章提到的trick包括:模型结构调整,数据增强,学习率调整,训练速度优化等等。
加快模型训练
目前加快模型训练有效的两种方式是:(1)使用大的batch size;(2)采用低精度训练;
(1)使用大的batch size训练
使用较大的 batch size 时,如果还是使用同样的 epochs 数量进行运算,则准确度往往低于 batch size 较小的场景。为了确保使用较大的 batch size 训练能够在相同 epochs 前提下获得与较小的 batch size 相近的测试准确度。这部分具体可以参考Accurate, Large Minibatch SGD这篇文章。作者总结了如下几种解决方案:
A.增大学习率:如果我们将 batch size 由 B 增加至 kB,我们亦需要将学习率由η增加至 kη(其中 k 为倍数)。
B.warm up:先用一个小的学习率先训几个epoch(warmup),因为网络的参数是随机初始化的,假如一开始就采用较大的学习率容易出现数值不稳定,这是使用warmup的原因。等到训练过程基本稳定了就可以使用原先设定的初始学习率进行训练了。论文中提到了warmup采用线性增加策略实现。举例而言,假设,初始学习率为η,选择前m个batch用于warm up,则在第i个batch时, 1 ≤ i ≤ m,设置学习率为 iη/m。
C.每个残差模块最后的BN层中γ设置为0:BN层的γ、β参数是用来对标准化后的输入做线性变换的,也就是γx^+β,一般γ参数都会初始化为1,β参数会初始化为0,作者认为初始化为0更有利于模型的训练。
D.不对bias执行weight decay操作:weight decay通常用于所有网络层的可学习参数(包括weight和bias)。其作用等效于对所有参数做L2正则化,以达到减少模型过拟合的作用。作者推荐仅仅只对weight进行weight decay操作。
(2)使用低精度训练
采用低精度比如FP16训练可以在数值层面上对网络训练加速。通过大多数网络训练都是采用FP32精度训练,是因为网络的输入,网络参数以及网络输出都是采用FP32。如果能使用16位浮点型参数进行训练,就可以大大加快模型的训练速度。下表是使用大的batch size和半精度FP16进行训练的前后对比,其中baseline 使用BS=256,FP32,efficient使用BS=1024,FP16: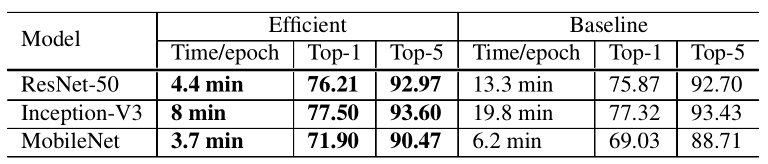
从实验结果可以看出,相比baseline,训练速度得到明显提升,而且准确率上也得到了一定程度提升。更加详细的对比实验如下: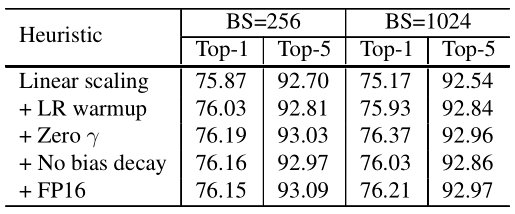
模型结构调整
这种模型结构调整是在不显著增加计算量的情况下对模型性能进行进一步提升。作者以ResNet为例进行优化。ResNet通常包括一个input stem,4个stage和1个output。下图展示的是原始resnet50结构。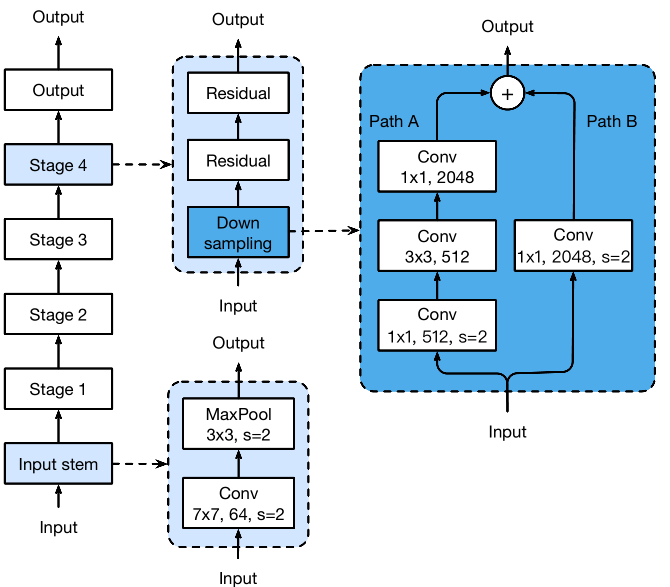
作者在downsampling 部分,input stem以及Path B部分做了一些小的调整,对应如下图(a),(b),(c)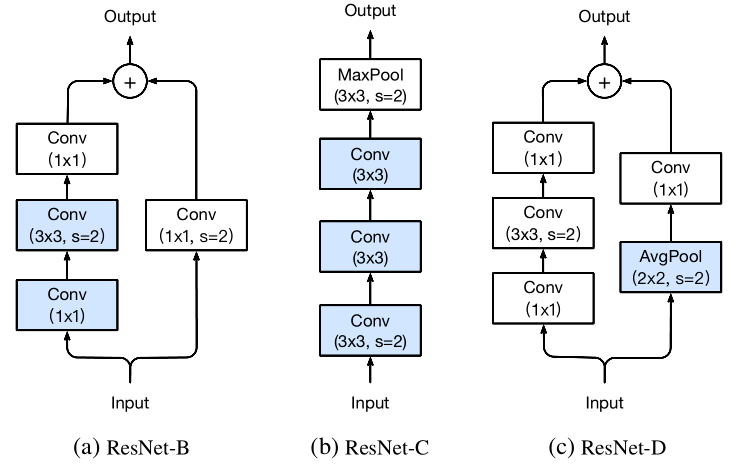
实验结果对比如下: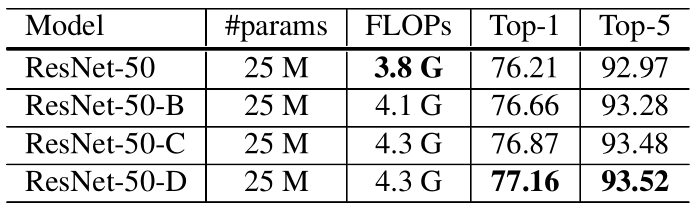
从实验结果可以看出,这些结构上微小的调整,并没有对计算量带来较大的变化,但对accuracy带来不小的提升。
模型训练调优
作者在这一部分提到了四种调优技巧:
采用cosine学习率衰减策略:实验对比结果如下,相比于常用的step decay,cosine decay在起始阶段开始衰减学习率,在step decay的学习率下降了10x时,cosine依然可以保持较大的学习率,这潜在的提高了训练速度。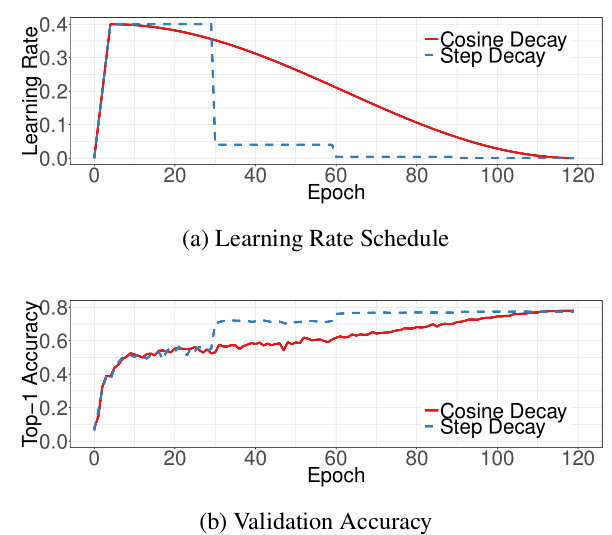
知识蒸馏:使用一个效果更好的teacher model训练student model,使得student model在模型结构不改变的情况下提升效果。作者采用ResNet-152作为teacher model,用ResNet-50作为student model。代码上通过在ResNet网络后添加一个蒸馏损失函数实现,这个损失函数用来评价teacher model输出和student model输出的差异,因此整体的损失函数原损失函数和蒸馏损失函数的结合: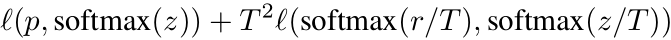
其中p表示真实标签,z表示student model的全连接层输出,r表示teacher model的全连接层输出,T是超参数,用来平滑softmax函数的输出。
mixup:mixup也是一种数据增强操作,其大致操作是,每次读取2张输入图像,假设用(xi,yi)和(xj,yj)表示,那么通过如下公式就可以合成得到一张新的图像(x,y),然后用这张新图像进行训练: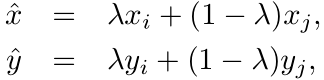
其中λ属于[0,1]服从Beta分布。实验结果如下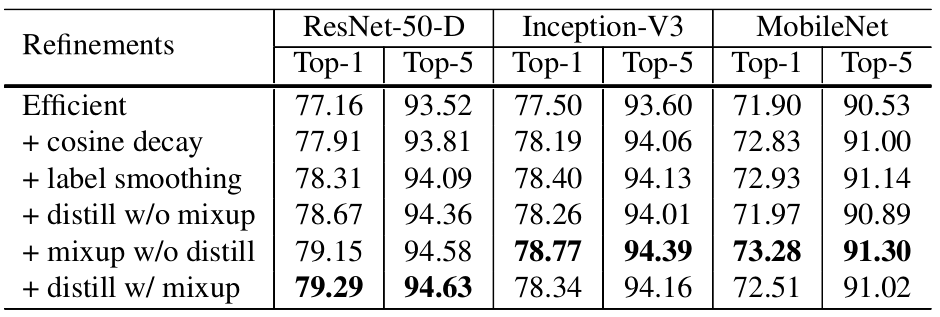
此外,作者将这些trick应用于其他图像任务中,比如目标检测,图像分割上同样有效,可以带来2-3个点的提升。