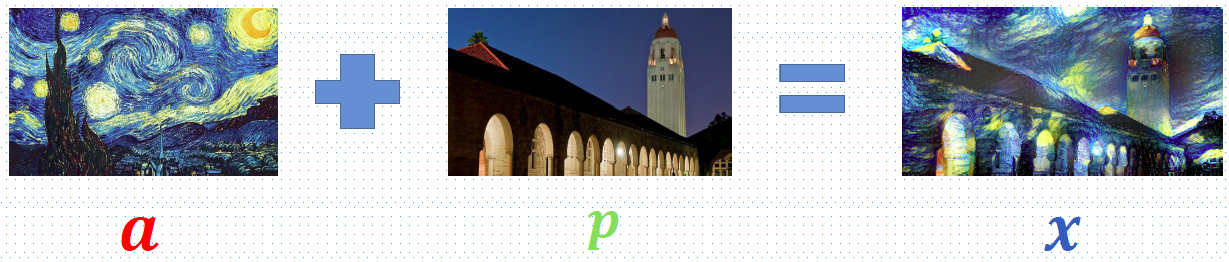
风格迁移,是一个非常有意思的任务,使用这种方法,可以将一张图片的风格“迁移”到另外一张图片上。如下图:
从上面的图看一看出,风格迁移就是输入一张图片,在持本身内容大致不变的情况下,结合一张艺术图片,然后生成出带有艺术效果的图片。风格迁移自2015年Gatys第一次提出开始,其热度一直不断攀升,期间还出现了一个非常火爆的“风格迁移”滤镜App——Prisma,App官网上面的风格迁移图片做的非常好看,真是美如画,可以去看看一下。
风格迁移自2015年发展到现在,涌现出许多非常不错的算法,这些算法大致可以分为三种:
- 原始风格迁移:固定风格固定内容;
- 快速风格迁移:固定风格任意内容;
- 极速风格迁移:任意风格任意内容;
风格迁移的大致思路基本都是通过定义两种loss:Content loss和 Style loss。分别对应着输出图片与 Content Image 内容上的差异,以及与 Style Image 在风格上的差异。最终的 Loss 为两种 Loss 的加权和,通过迭代优化,不断减小loss,使得生成图片既包含content image的内容也具有style image的风格。
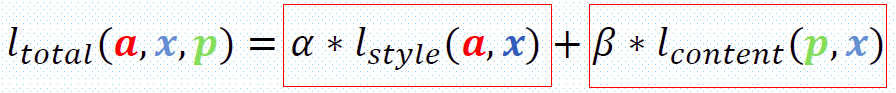
我们的目的是生成一张在内容上尽量与Content image 保持一致,在风格上尽量与Style image要保持一致的图片,现在输入输出,loss都知道了,那怎样具体去设计Content loss和Style loss呢。
原始风格迁移(style transfer)
原始风格迁移是在固定风格、固定内容的情况下做的风格迁移,这是最慢的方法,也是最经典的方法。原始风格迁移方法思路比较简单,将生成图片看做是一个训练的过程,训练变量就是图片,通过不断的迭代优化,生成与内容图片以及风格图片都尽量一致的图片,这种方法的缺点就是速度慢,效率低。这种方法可以参考这篇文章: A Neural Algorithm of Artistic Style。
网络结构
在进行风格迁移任务时,需要使用一个预训练网络对图像提取特征,通过这些特征来衡量两个图像之间的内容差异和风格差异。在这里我选用了VGG16,提取其中几个比较重要的层的特征。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class VGG(nn.Module):
def __init__(self, features):
super(VGG, self).__init__()
self.features = features
self.layer_name_mapping = {
'3': "relu1_2",
'8': "relu2_2",
'15': "relu3_3",
'22': "relu4_3"
}
for p in self.parameters():
p.requires_grad = False
def forward(self, x):
outs = []
for name, module in self.features._modules.items():
x = module(x)
if name in self.layer_name_mapping:
outs.append(x)
return outs
vgg16 = models.vgg16(pretrained=True)
vgg16 = VGG(vgg16.features[:23]).to(device).eval()
经过修改之后的VGG16可以提取relu1_2、relu2_2、relu3_3、relu4_3这几层的特征图。打印这几层特征图的大小,如下:1
2
3
4relu1_2 [1, 64, 512, 512]
relu2_2 [1, 128, 256, 256]
relu3_3 [1, 256, 128, 128]
relu4_3 [1, 512, 64, 64]
内容 Content loss
在进行风格迁移时,如何保证生成图像与内容图像的一致性,如何使用定量指标去衡量两张图片在内容上的差异呢。在上面的那张网络结构图上,采用的是relu3_3层特征去比较内容差异。注意,在这里,没有使用Image Transform Net。图片X,Y之间的内容差异可以如下表示:
$F_{XL}$表示将第relu3层的feature map展开后的一维向量。我们可以简单的认为,输入图片X在网络的第relu3层的内容就是它。根据生成图像和内容图像在relu3层的输出的特征图的均方误差(MeanSquaredError)来优化生成的图像与内容图像之间的内容一致性。
风格 Style loss
在Gatys那边文章中引入Gram矩阵来表示图像的风格,通过Gram矩阵来计算图片风格之间的差异。假设预训练网络在第L层的特征图大小1chw,Gram矩阵的大小为cc,每一个元素Gram(k,l)表示第k个通道的特征图和第l个通道的特征图相乘求和,则
上面知道了图片风格的定义,那么图片之间的风格差异就是两幅图的Gram矩阵的差异。具体代码实现如下:1
2
3
4
5
6def gram_matrix(y):
(b, ch, h, w) = y.size()
features = y.view(b, ch, w * h)
features_t = features.transpose(1, 2)
gram = features.bmm(features_t) / (ch * h * w)
return gram
图片X,Y之间的风格差异定义如下:
在风格迁移中,我们需要最小化几层内容差异$D_C^L(X,Y)$和几层风格差异$D_S^L(X,Y)$,我们的目标函数就最小化这两者的和。
其中$L_C$表示内容上需要输出的几层,$L_S$表示风格需要输出的几层。w表示相应的权重。从上面的那个网络结构图可以看出,在内容上只比较了relu3_3层的差异,在风格上比较了relu1_2、relu2_2、relu3_3、relu4_3 四层的差异。
完整代码实现 code
1 | ''' |
这里说明一下,上面的完整代码主要参考这里,还有这里。
最终实验结果如下:
从上面的实验结果可以看出,生成的图片即包含有content image的内容,也有style image的风格。上面生成一张512大小的图片,设置的是迭代300次,在tianX上用时10s左右,从速度上来讲还是挺慢的。下一篇博客会介绍一下在此基础上改进的快速风格迁移,以及基于meta network的极速风格迁移,尤其是CVPR2018的基于meta network的风格迁移方法,该方法可以直接在手机移动端运行,可以达到实时风格迁移的效果。
最后
图像风格迁移这个领域,我也是刚开始看,如果对这个方向感兴趣的话,想深入了解的话,就得需要多看看论文。然后搜集查找相关论文是一个比较耗时的过程,还有已经有人整理了不少关于风格迁移相关的论文和代码,想深入了解的话,可以看这里:Neural-Style-Transfer-Papers-Code。