论文信息:CVPR2015 Workshop
代码链接:https://github.com/kevinlin311tw/caffe-cvprw15
整体框架:当前基于内容的图像检索(Content-based Image Retrieval,CBIR)旨在通过对图像内容的分析搜索出相似的图像,其主要包括两个部分:图像表示和相似性度量。现在深度学习的如火如荼以及在计算机视觉领域的成功,使用CNN特征作为图像表示越来越成为一种趋势,以AlexNet卷积神经网络为例,将最终的4096维向量作为最终图像的特征向量。这样的向量是一些高维向量,不利于计算,尤其是对于百万级的搜索库来说,效率极低。这篇文章的目的就是旨在提高基于CNN特征表示的检索速度,因此提出二进制哈希编码的CNN特征表示。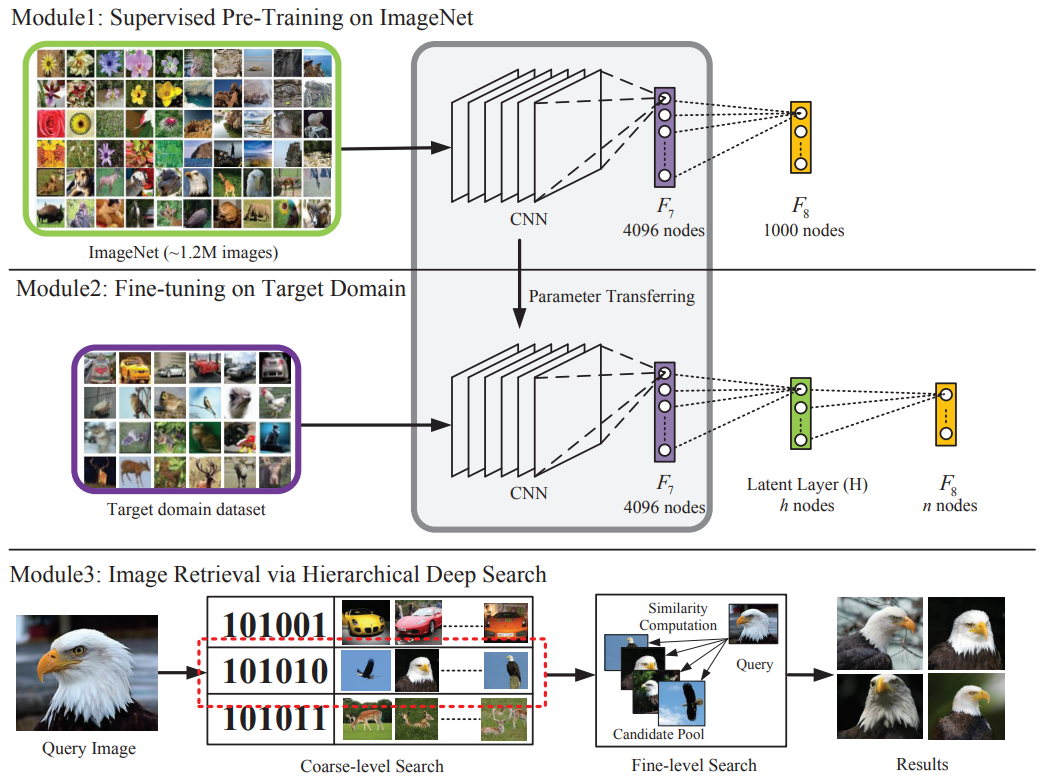
模型结构
从上图可以看出,模型是在一个深层CNN的最后一个全连接层(fc8)和倒数第二个全连接层(fc7)之间加了一层全连接隐层,就是图一中绿色的latent layer(H)。这样一来,既可以得到深层的CNN特征,文中主要用的是fc7的特征,还可以得到二分的哈希编码,即来自H。这个隐层H不仅是对fc7的一个特征概括,而且是一个连接CNN网络的中层特征与高层特征的桥梁。
哈希编码
为了让一个网络能够对某一类物体高鲁棒,即target domain adaption,用一类主题目标数据集来整定(fine-tune)整个网络。fc8的节点数由目标类别数决定,H的节点数在文中有两种尝试:48和128。这两个层在fine-tune时,是随机初始化的,其中H的初始化参考了LSH[1]的方法,即通过随机映射来构造哈希位。通过这样训练,得到的网络能够产生对特定物体的描述子以及对应的哈希编码。
图像检索
作者采用了一种从粗到精(coarse-to-fine)的搜索策略。给定一张图像I,首先提取H层特征。并对其进行二值化,如下:
(1)粗糙检索:粗糙检索是用H层的二分哈希码,相似性用hamming距离衡量。待检索图像设为I,将I和所有的图像的对应H层编码进行比对后,选择出hamming距离小于一个阈值的m个构成一个池,其中包含了这m个比较相似的图像;
(2)细致检索:细致检索则用到的是fc7层的特征,相似性用欧氏距离衡量。距离越小,则越相似。从粗糙检索得到的m个图像池中选出最相似的前k个图像作为最后的检索结果。每两张图128维的H层哈希码距离计算速度是0.113ms,4096维的fc7层特征的距离计算需要109.767ms,因此可见二值化哈希码检索的速度优势。
实验结果
作者在MNIST、CIFAR-10以及Yahoo-1M三个数据集上做了分类和检索的验证实验,为了公平地和其他算法进行比较,作者在前两个数据上仅使用了H层特征进行检索,在Yahoo-1M上使用了coarse-to-fine的层次检索方式。下面是三个数据集上一些实验结果。
(1) MNIST
左边是query,右边是使用48位和128位H层特征得到的结果。可以看到检索出的数字都是正确的,并且在这个数据集上48位的效果更好,128位的太高,容易引起过拟合。
(2)CIFAR-10
在这个数据集上128位的H层节点比48位的效果更好,比如128检索出更多的马头,而48位的更多的全身的马。
(3)Yahoo-1M
在这个数据集上作者使用了三种特征进行比较,分别是:1)使用H层特征+fc7特征;2)仅使用H层特征;3)fc7层特征;4)使用在ImageNet上预训练的AlexNet提取fc7层特征;实验结果如上图四行检索结果;可以看到如果只用alexnet而不进行fine-tune的话,检索出的结果精度很低。
总的来说,这篇文章的思路还是比较清晰简单,无论是从网络结构还是方法的设计上都比较简单,也没什么公式推导以及理论知识,但是却很work。我将其应用在商品识别项目上效果还是比较好。感兴趣的可以试试,代码也开源了。