论文信息: Face++ && Tsinghua,2017
代码链接: https://github.com/zengarden/light_head_rcnn
论文背景: 这篇文章主要是基于faster rcnn 和 r-fcn 做的改进。这篇文章将two stage的检测模型分为了两个部分,body和head。body指的是roi pooling之前的网络部分,head指的是roi pooling和r-cnn子网络部分,r-cnn子网络是对roi进行分类和预测roi位置的那一部分。faster rcnn的roi pooling的channel数很大,有2048,这使得后面的两个fc层计算量很大, 而且faster rcnn的roi数目是很大的,针对每个roi都要调用一次r-cnn子网络,这个开销十分大。r-fcn在r-cnn子网络前设 了一个score map,试图共享roi的计算,以解决faster rcnn的这个问题,但是引入的score map的channel数很大,是 P*P(C+1),C为类别数,在COCO数据集上,这个值为3969(7*7*81),这使得r-fcn的计算量相比faster rcnn小了一些,但依然很大。综上,faster rcnn和r-fcn的head计算量都很大,即使body用了轻量化的网络,它们的速度依然比不上one stage的方法。这篇文章的主要目的就在于对head部分的结构重新设计,包括两个部分:R-CNN subnet + ROI warping ,减少head部分的计算量。模型的改进是在R-FCN上进行的。
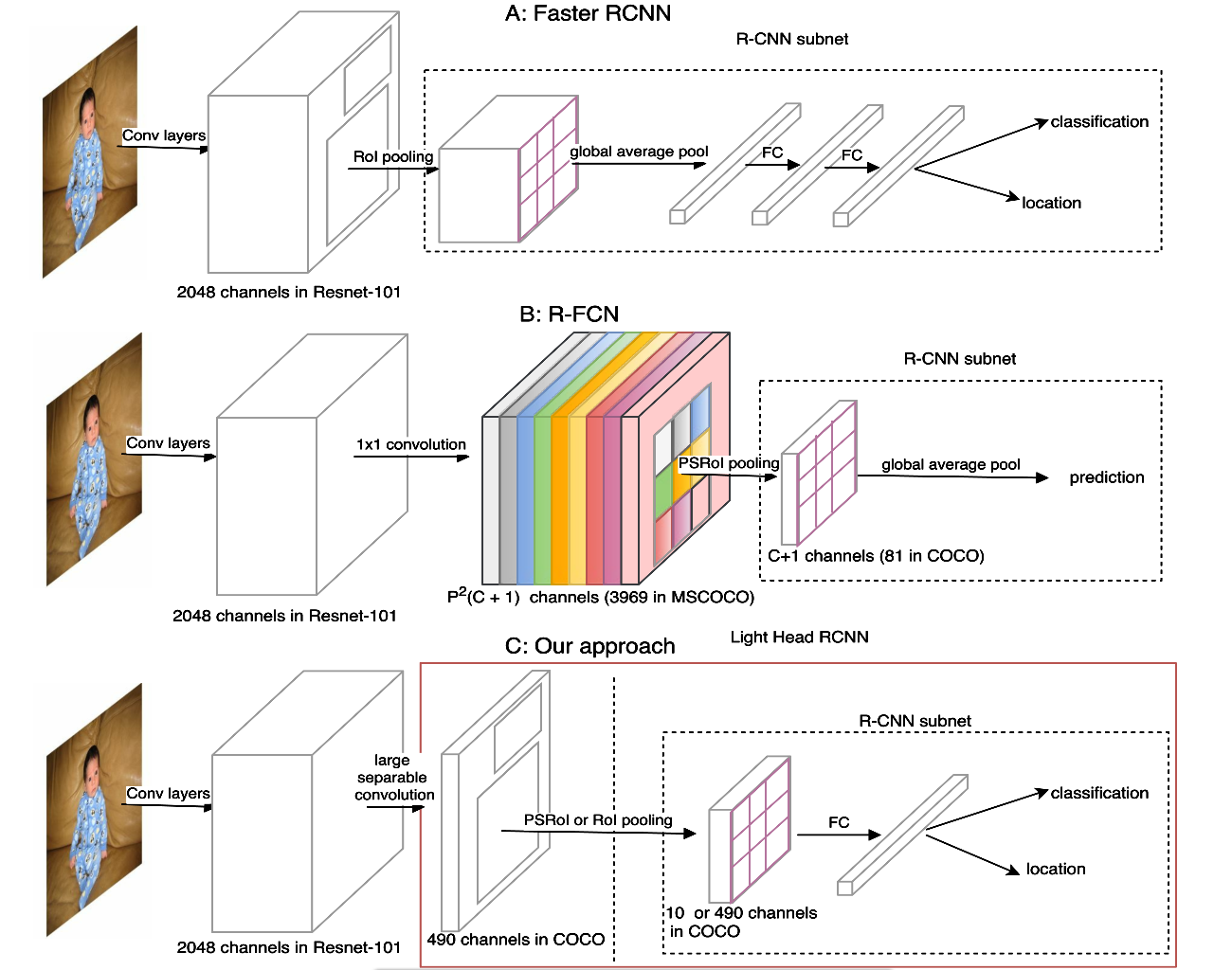
图1本文结构与Faster RCNN,R-FCN对比
1-R-CNN subnet
首先看R-CNN subnet(图中虚线框出来的部分)的设计。这里作者和两个经典网络Faster rcnn(称A)、R-FCN(B)进行了对比,如上图。作者从accuracy 和 speed 两方面进行阐述,说明另两个优缺点。
accuracy:A在FC层前,为了减小之后FC的计算量,使用了pooling,但这会对空间位置信息造成伤害;B也在prediction前直接用了pooling。
Speed:A 每一个ROI都是独立的经过一个subnet得到结果,会降低整个网络的速度,尤其proposal多的话,影响会更大;B
虽然采用cost-free R-CNN subnet,但是之前需要得到一个非常多的score map。
而作者提出的Light-Head R-CNN 只有一个FC层,用作者的话说 makes a good trade-off between the performance and computational speed。
2-ROI warping
在ROI warping 方面,由于是在R-FCN上进行的,一个很直观的想法就是降低进入head 部分feature map的channel数,文章就是讲R-FCN上的score map从P*P*(C+1)减少到P*P*a,a是一个与类别数无关的数值,比如10。这样score map与类别数无关,在roi pooling之后再添加一个fc层,用于预测类别和位置。作者实验发现,在channel数少的feature maps上做ROI pooling,不仅准确率提高,还会节约内存及计算量资源。一举两得。
整体结构:
作者的实验是基于两种setting的,setting “L” :用 Resnet 101 做基础的feature extractor 网络,证明作者算法的performance ; setting “S”:用一个类似 Xception的小网络做基础网络。
作者在base model 的最后一个卷积层用 large separable convolution layers获得 channel数少的feature map。结构如下。k在论文方法里设置为15,Cmid在setting L时是256,在setting S时是64,Cout为10*p*p(比R-FCN用的#classes*p*p 小很多)。k很大,感受野增大,因此feature maps效果更好。

经过上面的large separable convolution layers之后,再进行PSROI,然后接fc2048用于分类和回归。
3-实验部分(coco)
为了研究channel 数少的feature map 对ROI warping的影响,作者采用R-FCN作为 baseline,并且还对baseline
进行了少许改进,这里就不赘述,可以看论文的4.2.1。之后在baseline的基础上进行了如下变化:(1)将feature map channels 从 3969 (81 × 7 × 7) 改为 490 (10 × 7 ×7);(2)因为channel数少了,并不能直接voting得到最终的结果,所以最后加了fc进行prediction。结构如下图。
这里不得不说一下,作者在R-FCN的基础上做了三个trick{anchor数量,balance loss weight,256 top ranked for
BP},就提高了3.1个点,可见作者在使用各种trick方面非常强。

从实验结果来看,feature map channel虽然减少了,但是performance基本上没有差别。如下表格。

然后作者又做了实验研究large separable convolution的作用(同时也用的channel数更少),如下表

accuracy: ms-train指的是训练时采用scale jittering,crop size固定,但是图片的短边可以有不同尺寸。feature pyramid采用不同的尺寸的feature map上都有预测。align指采用ROI align

Speed:

仅从创新的角度上来看,个人觉得这篇文章的工作很一般,idea也比较简单,但却很work。可以看出作者的工程能力方面很扎实。