论文信息: Tsung-Yi Lin,Kaiming He, Best Student Paper Award at ICCV 2017
代码链接: https://github.com/fizyr/keras-retinanet
整体框架: 目标检测方法有两大类:基于proposal的two-stage方法和基于regression的one-stage方法。后者虽然比前者速度快,但是单精度要低于前者,作者通过分析发现,造成这种情况的主要原因是训练正负样本存在类别不平衡问题。作者针对这个问题提出了一个focal loss,并在FPN网络基础是使用focal loss 实例化提出了一个one-stage 法的网络:RetinaNet。在不影响其速度的情况下,在精度上可以超越当前的SOAT。
one-stage detector存在的问题:类别不平衡
这种方法的detector一般都是通过密集采样的方式从一张图片中密集采样出10\^4~10\^5个候选框,但这些候选框中只有少部分是包含有目标。即前景/背景之间存在严重的不平衡现象,这种不平衡会导致一个问题:负样本太多,占总的loss的大部分,而且都是easy负样本,这对网络训练来说没有任何帮助而且会降低网络泛化能力。针对这种情况一个普遍的做法是采用 hard negative mining:在训练时采样困难样本对网络训练或者训练时采用更复杂的采样策略。作者在文章中发现这种方法并不是那么的work,于是就提出了focal loss,这样不需要使用任何困难样本采样策略,可以对所有样本进行训练。
Focal loss: 用于处理 one-stage 目标检测场景在训练中出现的前景/背景类别极度不平衡问题(eg, 1:1000)。
对于二分类交叉熵(cross entropy,CE)定义如下:

为方便起见,定义$\text{pt}$ ,

从上左图的蓝线可以看出即使是容易分类样本($pt\ \gg 0.5)$,也能带来不小的损失。Focal loss 的目的是($p\ t\ \gg0.5)$的样本的loss更小。因此focal loss定义如下:

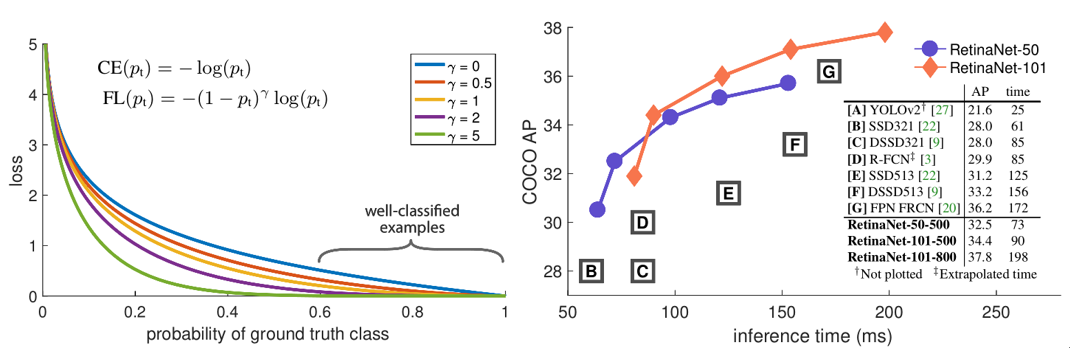
r取值[0,5]如上图。从上面的FL公式可以看出,FL具有两个性质:(1)样本分类错误时,$\text{pt}$很小,$(1
- pt)\hat{}r$趋近1,整个FL基本不变,当$pt \rightarrow 1$时,$(1 -pt)\hat{}r$趋近0,分类正确的样本就能被很好的down-weighted;(2)聚焦参数γ可以平滑地调节易分类样本被down-weighted的速率,当$\gamma =0$时,FL等于CE。总的来说,FL的目的还是在于减少易分类样本的权重,从而使模型在训练时更加专注于难分类的样本。
在具体实现时,作者还另外添加了一个超参数,FL如下:

RetinaNet: 作者在FPN网络的基础上应用focal loss,来实例化RetinaNet.大致网络结构如上图所示,具体细节可以看原文。如果之前有了解过OHEM(online hard example mining)的话,可以看出FL和OHEM很像,不过两者还是存在区别:
1) OHEM是只取3:1负样本用于计算loss,之外的全部置零,也就是将easy的样本全部抛弃;
2) Focal loss是取所有样本,根据难易程度给不同权重。
作者专门做了实验与OHEM进行对比发现,focal loss完全可以吊打OHEM。如下图左下角实验结果。
我也对自己的数据训练了一下效果还不错,不过针对一些密集目标还是会出现了一些bad case。下面是在coco和自己的数据上训练的结果